


Launched by NVIDIA AI Reinforcement studying pre-training (RLP)a coaching goal that injects reinforcement studying. Pre-training Do it in phases as a substitute of suspending it after coaching. The core thought is easy and testable. We deal with brief ones. Chain of Thought (CoT) as motion sampled earlier than prediction of subsequent token, Reward for info It gives the next tokens noticed: EMA baseline with out pondering. This ends in No verifier required, excessive density, position-based rewards This may be utilized to common textual content streams on a pre-training scale.
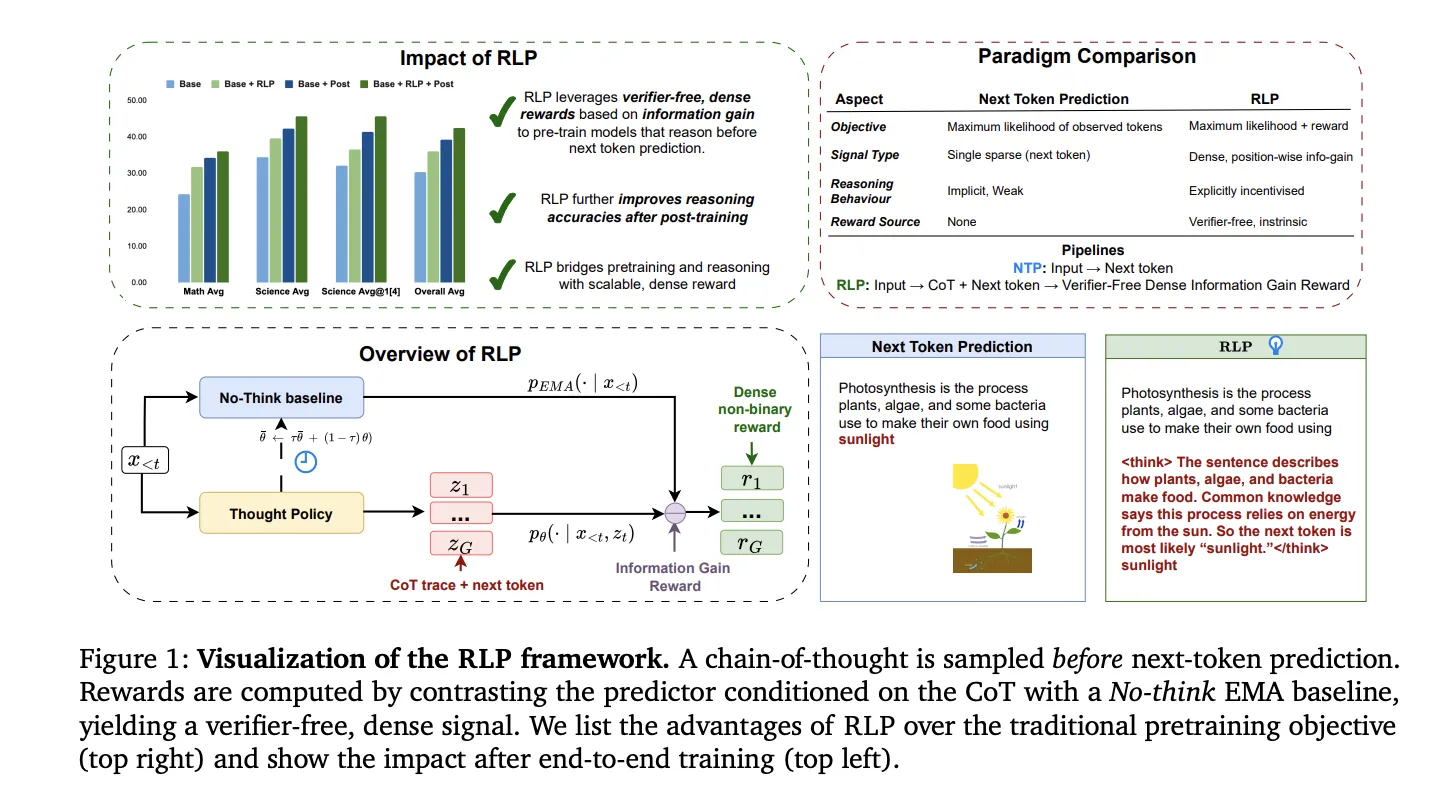
Mechanism: EMA counterfactual reward for info achieve
RLP makes use of a single community (shared parameters) and (1) CoT coverage 𝜋 𝜃 ( 𝑐 𝑡 ∣ 𝑥 < 𝑡 ) π θ (ct ∣x
r(ct)=logpθ(xt∣x
Why that is technically vital: This differs from earlier “strengthened pre-training” variations that depend on sparse, binary Accuracy Sign or Proxy Filter, RLP densely packed, No verifier required Comes with a reward Credit per place Pondering In every single place Improves Forecasts and Permits Updates Location of all tokens Typically web-scale corpora with out exterior validators or curated reply keys.
perceive the outcomes
Qwen3-1.7B-Base: Pre-training with RLP improved total averages in math and science ~19% in comparison with base mannequin and ~17% in comparison with compute-matched steady pre-training (CPT). rear After the identical coaching (SFT + RLVR) Throughout all variants, the RLP-initialized mannequin is Roughly 7-8% relative advantages, with the best profit being achieved in inference-heavy benchmarks (AIME25, MMLU-Professional).
Nemotron-Nano-12B v2: Apply RLP to 12B Hybrid Mamba Transformer Checkpoints permit Total common elevated from 42.81% to 61.32% and Absolute +23% achieve in scientific reasoningalthough RLP execution was used. Tokens decreased by about 200B (Coaching for 19.8T versus 20T token. I utilized for RLP 250M token). that is the spotlight knowledge effectivity and structure unbiased Motion.
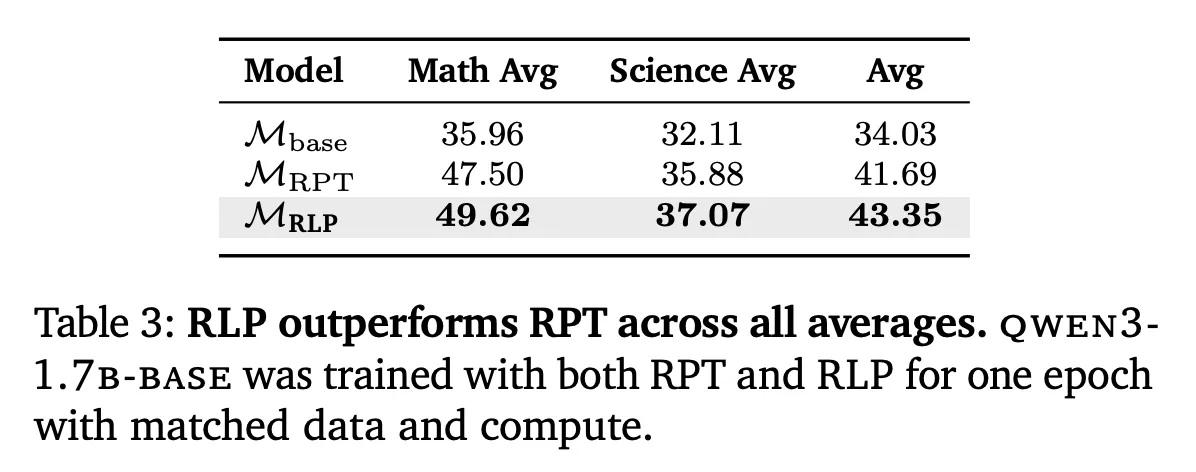
RPT comparability: Calculate, RLP with Omni-MATH fashion settings underneath matched knowledge exceeded RPT About Arithmetic, Science, and Total Averages – Attributed to RLP Steady info acquisition Comparability of rewards and RPT sparse binary Sign tokens and entropy filtered tokens.
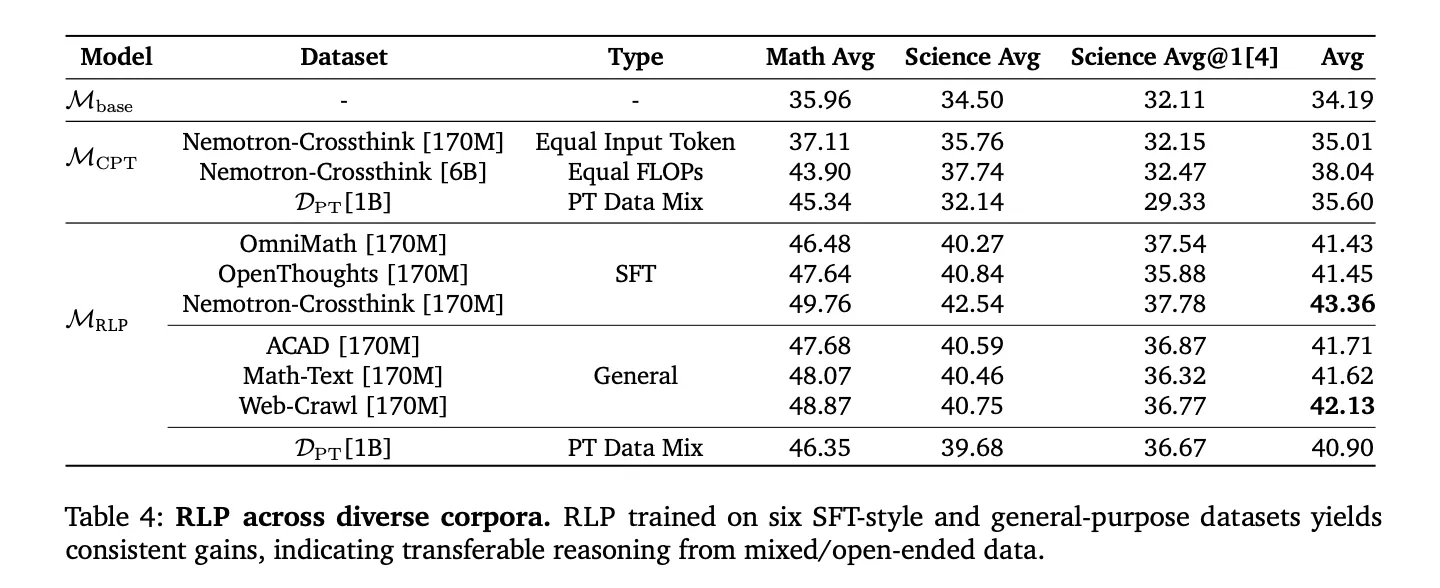
Comparability of positioning and post-training RL and knowledge curation
Reinforcement studying pre-training (RLP) is orthogonal to the post-training pipeline (SFT, RLVR) and present combine Enchancment after commonplace alignment. The reward shall be calculated From mannequin log proof Moderately than an exterior validator, scale it like this: area unbiased corpora (internet crawls, educational paperwork, textbooks) and SFT-style inference corpusavoiding vulnerabilities in narrowly chosen datasets. Computing Match Comparability (Consists of) CPT with 35x extra tokens (according to FLOP), RLP nonetheless leads on the general common, suggesting that enhancements come from: design of objectivenot a funds.
Vital factors
- RLP makes inference a pre-training aim. Pattern the thought chain and reward it earlier than predicting the subsequent token Info acquisition It is above the EMA baseline with out pondering.
- Dense, location alerts that do not require a verifier: It really works on common textual content streams with out exterior graders and permits scalable pre-training updates on each token.
- Outcomes for Qwen3-17B: +19% in comparison with base throughout pre-training and +17% in comparison with compute-matched CPT. With an identical SFT+RLVR, RLP maintains as much as 7-8% achieve (most on AIME25, MMLU-Professional).
- Nemotron-Nano-12B v2: total common goes up 42.81% → 61.32% (+18.51 pp; ~35 to 43% relative) and +23 factors Scientific reasoning reduces the NTP tokens utilized by roughly 200B.
- Vital coaching particulars: Replace solely the gradients of thought tokens with clipped surrogates and group-relative advantages. Extra rollouts (≈16) and longer pondering intervals (≈2048) would assist. There isn’t a profit to token-level KL anchoring.
conclusion
RLP restructures pre-training to immediately reward “assume earlier than predicting” habits utilizing verifier-free info acquisition alerts, producing sturdy inference positive aspects that persist by the identical SFT+RLVR and scale throughout architectures (Qwen3-1.7B, Nemotron-Nano-12B v2). The aim of this methodology, particularly to distinction CoT conditional chance with a no-sink EMA baseline, integrates cleanly into large-scale pipelines with out handpicked validators, making it a sensible improve to pre-training for the subsequent token somewhat than a post-training add-on.
Please test paper, code and Project page. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to observe us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a synthetic intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per 30 days, demonstrating its reputation amongst viewers.

{kind=link}