


A group of researchers from Stanford College has been launched Medagentbencha brand new benchmark suite designed to guage large-scale language mannequin (LLM) brokers within the healthcare context. Not like earlier question-solving datasets, Medagentbench gives a Digital Digital Well being Document (EHR) Setting AI methods should work together, plan, and execute multi-step medical duties. This reveals a significant shift from testing static inference to assessing agent performance Stay, tool-based medical workflow.
Why do healthcare require agent benchmarks?
LLMs have moved past static chat-based interactions Agent conduct– Excessive-level instruction interpretation, API calls, affected person information integration, and complicated processes automation. In drugs, this evolution helps cope Employees shortages, doc burden, and administration inefficiency.
There are general-purpose agent benchmarks (agent benches, agent boards, tau benches, and many others.), Healthcare didn’t have a standardized benchmark This captures the complexity of medical information, FHIR interoperability, and longitudinal affected person information. Medagentbench fills this hole by offering a reproducible and clinically related evaluation framework.
What does Medagentbench embrace?
How are the duties configured?
Medagentbench consists of it 300 duties throughout 10 classeswritten by a licensed physician. These duties embrace looking out affected person info, monitoring lab outcomes, documentation, check order, referral, and drugs administration. The duty is a median of 2-3 steps and mirror workflow encountered in inpatient and outpatient care.
Which affected person information assist benchmarking?
Benchmark leverage 100 lifelike affected person profiles Extracted from Stamford’s Starr information repository and consists of over 700,000 information Consists of labs, vitals, prognosis, procedures, and drugs orders. Knowledge had been recognized and jittered for privateness whereas sustaining medical validity.
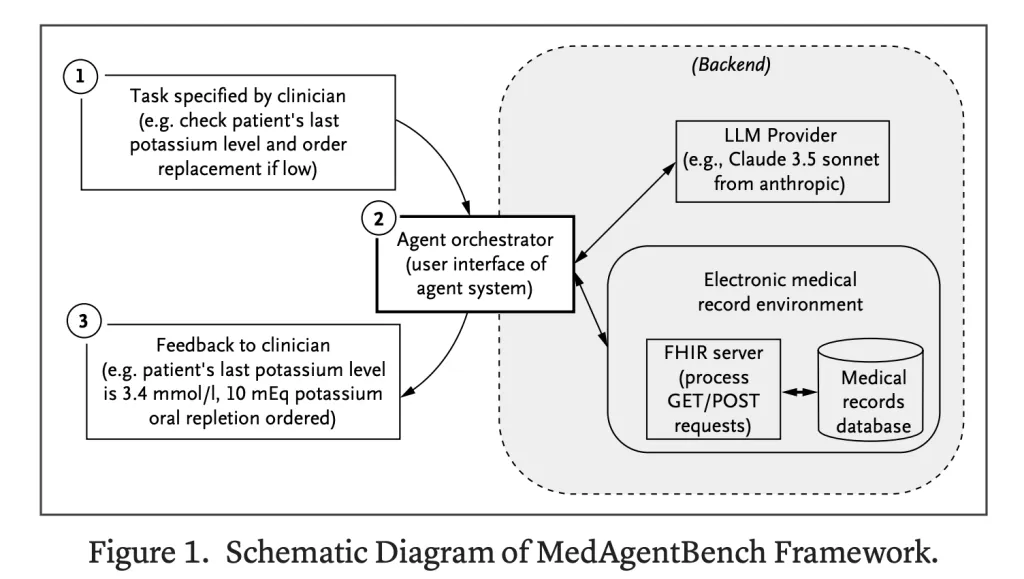
How is the setting constructed?
The setting is Fhir complianthelps each looking out (GET) and modifying (Put up) EHR information. AI methods can simulate lifelike medical interactions, resembling very important documentation and drugs order placement. This design permits the benchmark to be translated straight into the Stay EHR system.
How are fashions evaluated?
- metric: Job success price (SR) measured strictly Cross @1 Reflecting real-world security necessities.
- Examined mannequin: 12 main LLMs together with GPT-4O, Claude 3.5 Sonnet, Gemini 2.0, Deepseek-V3, Qwen2.5, and Llama 3.3.
- Agent Orchestrator: Baseline orchestration setup with 9 FHIR capabilities; 8 interplay rounds per process.
Which mannequin carried out finest?
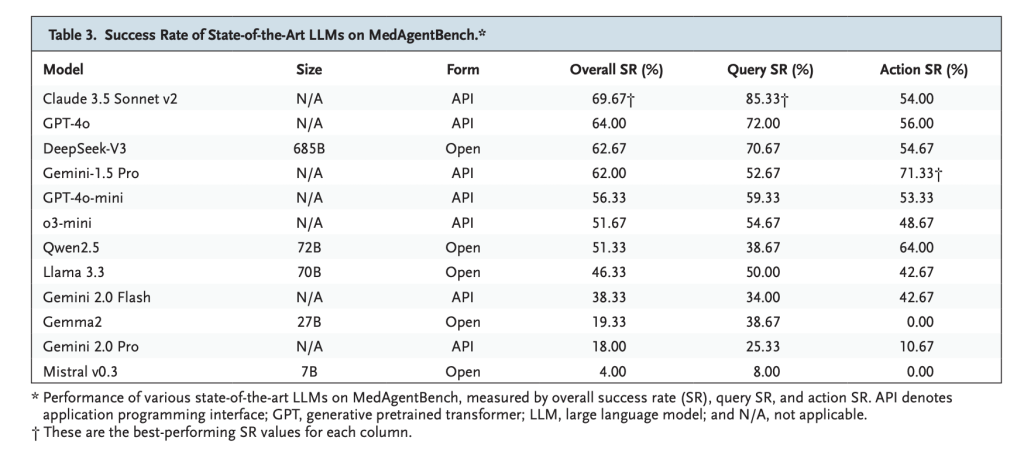
- Claude 3.5 Sonnet V2General it is one of the best 69.67% successparticularly robust in search duties (85.33%).
- GPT-4O: 64.0% success. Exhibits balanced search and motion efficiency.
- deepseek-v3: 62.67% success. He’s main the best way amongst open weight fashions.
- commentaryMost fashions had been wonderful Question process However it was a battle Motion-based duties Secure multi-step execution is required.
What errors did the mannequin create?
Two dominant patterns of dysfunction emerged.
- Failure to stick to directions – Invalid API calls or incorrect JSON format.
- Output mismatch – Offers an entire assertion when structured numeric values are required.
These errors spotlight the hole Accuracy and reliabilityeach are vital in medical deployment.
abstract
Medagentbench establishes the primary giant benchmark for assessing LLM brokers in a practical EHR setting, combining 300 clinicians with an FHIR-compliant setting and 100 affected person profiles. The outcomes present that it might be robust however restricted reliability. Claude 3.5 Sonnet V2 leads at 69.67%. Will increase the hole between profitable question and protected motion execution. MedagentBench, constrained by single-center information and EHR-centric scopes, gives an open and reproducible framework for driving the following technology of reliable healthcare AI brokers
Please examine paper and Technology Blog. Please be happy to examine GitHub pages for tutorials, code and notebooks. Additionally, please be happy to comply with us Twitter And remember to hitch us 100k+ ml subreddit And subscribe Our Newsletter.

Mikal Sutter is a knowledge science professional with a Grasp’s diploma in Knowledge Science from Padova College. With its strong foundations of statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.

{kind=link}