


Amazon SageMaker HyperPod is a purpose-built infrastructure for optimizing basis mannequin (FM) coaching and inference at scale. SageMaker HyperPod removes the undifferentiated heavy lifting concerned in constructing and optimizing machine studying (ML) infrastructure for coaching FMs, decreasing coaching time by as much as 40%.
SageMaker HyperPod provides persistent clusters with built-in resiliency, whereas additionally providing deep infrastructure management by permitting customers to SSH into the underlying Amazon Elastic Compute Cloud (Amazon EC2) situations. It helps effectively scale mannequin growth and deployment duties comparable to coaching, fine-tuning, or inference throughout a cluster of a whole bunch or hundreds of AI accelerators, whereas decreasing the operational heavy lifting concerned in managing such clusters. As AI strikes in the direction of deployment adopting to a large number of domains and use circumstances, the necessity for flexibility and management is changing into extra pertinent. Giant enterprises need to make certain the GPU clusters observe the organization-wide insurance policies and safety guidelines. Mission-critical AI/ML workloads typically require specialised environments that align with the group’s software program stack and operational requirements.
SageMaker HyperPod helps Amazon Elastic Kubernetes Service (Amazon EKS) and provides two new options that improve this management and suppleness to allow manufacturing deployment of large-scale ML workloads:
- Steady provisioning – SageMaker HyperPod now helps steady provisioning, which reinforces cluster scalability via options like partial provisioning, rolling updates, concurrent scaling operations, and steady retries when launching and configuring your HyperPod cluster.
- Customized AMIs – Now you can use customized Amazon Machine Photos (AMIs), which permits the preconfiguration of software program stacks, safety brokers, and proprietary dependencies that will in any other case require advanced post-launch bootstrapping. Clients can create customized AMIs utilizing the HyperPod public AMI as a base and set up further software program required to fulfill their group’s particular safety and compliance necessities.
On this put up, we dive deeper into every of those options.
Steady provisioning
The brand new steady provisioning function in SageMaker HyperPod represents a transformative development for organizations operating intensive ML workloads, delivering unprecedented flexibility and operational effectivity that accelerates AI innovation. This function supplies the next advantages:
- Partial provisioning – SageMaker HyperPod prioritizes delivering the utmost doable variety of situations with out failure. You can begin operating your workload whereas your cluster will try and provision the remaining situations.
- Concurrent operations – SageMaker HyperPod helps simultaneous scaling and upkeep actions (comparable to scale up, scale down, and patching) on a single occasion group ready for earlier operations to finish.
- Steady retries – SageMaker HyperPod persistently makes an attempt to meet the consumer’s request till it encounters a
NonRecoverableerror from the place restoration will not be doable. - Elevated buyer visibility – SageMaker HyperPod maps customer-initiated and service-initiated operations to structured exercise streams, offering real-time standing updates and detailed progress monitoring.
For ML groups going through tight deadlines and useful resource constraints, this implies dramatically diminished wait instances and the power to start mannequin coaching and deployment with no matter computing energy is straight away accessible, whereas the system works diligently within the background to provision remaining requested sources.
Implement steady provisioning in a SageMaker HyperPod cluster
The structure introduces an intuitive but highly effective parameter that places scaling technique management straight in your palms: --node-provisioning-mode. Steady provisioning maximizes useful resource utilization and operational agility.
The next code creates a cluster with one occasion group and steady provisioning mode enabled utilizing --node-provisioning-mode:
Extra options are launched with steady provisioning:
- Cron job scheduling for example group software program updates:
- Rolling updates with security measures. With rolling deployment, HyperPod step by step shifts site visitors out of your outdated fleet to a brand new fleet. If there is a matter throughout deployment, it shouldn’t have an effect on the entire cluster.
- Batch add nodes (add nodes to particular occasion teams):
- Batch delete nodes (take away particular nodes by ID):
- Allow Coaching Plan capability for example provisioning by including the
TrainingPlanArnparameter throughout occasion group creation:
- Cluster occasion observability:
Customized AMIs
To cut back operational overhead, nodes in a SageMaker HyperPod cluster are launched with the AWS Deep Studying AMIs (DLAMIs). AWS DLAMIs are pre-built AMIs which are optimized for operating deep studying workloads on EC2 situations. They arrive pre-installed with well-liked deep studying frameworks, libraries, and instruments to make it simple to get began with coaching and deploying deep studying fashions.
The brand new customized AMI function of SageMaker HyperPod unlocks even larger worth for enterprise clients by delivering the granular management and operational excellence it’s worthwhile to speed up AI initiatives whereas sustaining safety requirements. It seamlessly bridges high-performance computing necessities with enterprise-grade safety and operational excellence.
Organizations can now construct custom-made AMIs utilizing SageMaker HyperPod performance-tuned public AMIs as a basis; groups can pre-install safety brokers, compliance instruments, proprietary software program, and specialised libraries straight into optimized photographs.
This function provides the next advantages:
- It accelerates time-to-value by minimizing runtime set up delays and decreasing cluster initialization time via pre-built configurations.
- From a safety standpoint, it permits enterprise-grade centralized management, so safety groups can keep full oversight whereas assembly their compliance necessities.
- Operationally, the function promotes excellence via standardized, reproducible environments utilizing version-controlled AMIs, whereas offering seamless integration with present workflows.
The next sections define a step-by-step method to construct your individual AMI and apply it to your SageMaker HyperPod cluster.
Choose and procure your SageMaker HyperPod base AMI
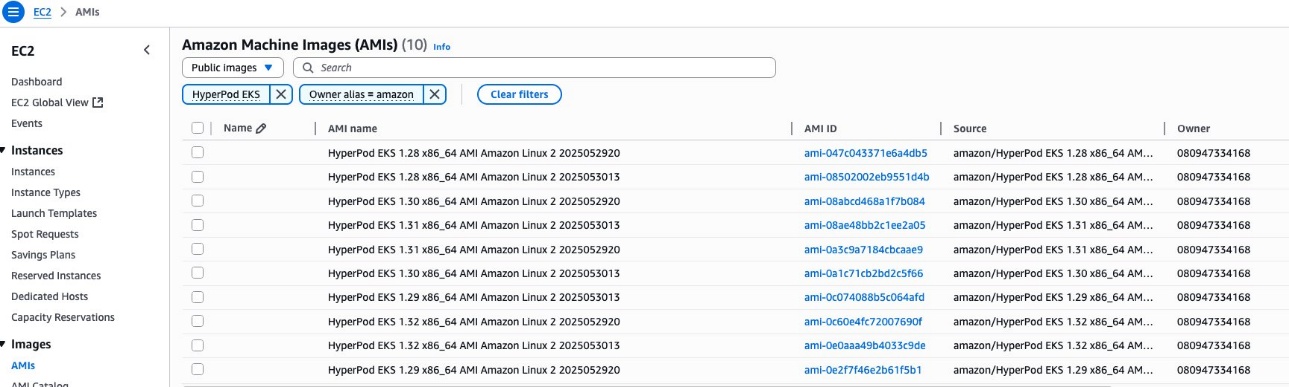
You possibly can select from two choices to retrieve the SageMaker HyperPod base AMI. To make use of the Amazon EC2 console, full the next steps:
- On the Amazon EC2 console, select AMIs beneath Photos within the navigation pane.
- Select Public photographs because the picture kind and set the Proprietor alias filter to Amazon.
- Seek for AMIs prefixed with
HyperPod EKS. - Select the suitable AMI (ideally the newest).
Alternatively, you should utilize the Amazon Command Line Interface (AWS CLI) with AWS Programs Supervisor to fetch the newest SageMaker HyperPod base AMI:
Construct your customized AMI
After you choose a SageMaker HyperPod public AMI, use that as the bottom AMI to construct your individual customized AMI utilizing one of many following strategies. This isn’t an exhaustive listing for constructing AMIs; you should utilize your most popular technique. SageMaker HyperPod doesn’t have any sturdy suggestions.
- Amazon EC2 console – Select your custom-made EC2 occasion, then select Motion, Picture and Templates, Create Picture.
- AWS CLI – Use the
aws ec2create-image command. - HashiCorp Packer – Packer is an open supply instrument from HashiCorp that you should utilize to create equivalent machine photographs for a number of platforms from a single supply configuration. It helps creating AMIs for AWS, in addition to photographs for different cloud suppliers and virtualization platforms.
- EC2 Picture Builder – EC2 Picture Builder is a completely managed AWS service that makes it simple to automate the creation, upkeep, validation, sharing, and deployment of Linux or Home windows Server photographs.
Arrange the required permissions
Earlier than you begin utilizing customized AMIs, affirm you have got the required AWS Identification and Entry Administration (IAM) insurance policies configured. Be sure you add the next insurance policies to your ClusterAdmin consumer permissions (IAM coverage):
Run cluster administration operations
To create a cluster with a customized AMI, use the aws sagemaker create-cluster command. Specify your customized AMI within the ImageId parameter, and embody different required cluster configurations:
Scale up an occasion group with the next code:
Add an occasion group with the next code:
Concerns
When utilizing customized AMIs together with your cluster, concentrate on the next necessities and limitations:
- Snapshot help – Customized AMIs should comprise solely the basis snapshot. Extra snapshots aren’t supported and can trigger cluster creation or replace operations to fail with a validation exception if the AMI accommodates further snapshots past the basis quantity.
- Patching –
ImageIdinupdate-clusteris immutable. For patching present occasion teams, you will need to use UpdateClusterSoftware withImageId. - AMI variations and deprecation – The general public AMI releases web page talks in regards to the public AMI variations and deprecation standing. Clients are anticipated to observe this web page for AMI vulnerabilities and deprecation standing and patch cluster with up to date customized AMI.
Clear up
To wash up your sources to keep away from incurring extra fees, full the next steps:
- Delete your SageMaker HyperPod cluster.
- In the event you created the networking stack from the SageMaker HyperPod workshop, delete the stack as properly to scrub up the digital non-public cloud (VPC) sources and the FSx for Lustre quantity.
Conclusion
On this put up, we launched three options in SageMaker HyperPod that improve scalability and customizability for ML infrastructure. Steady provisioning provides versatile useful resource provisioning that will help you begin coaching and deploying your fashions sooner and handle your cluster extra effectively. With customized AMIs, you’ll be able to align your ML environments with organizational safety requirements and software program necessities. To study extra about these options, see:
Concerning the authors
 Mark Vinciguerra is an Affiliate Specialist Options Architect at Amazon Net Providers (AWS) primarily based in New York. He focuses on Generative AI coaching and inference, with the purpose of serving to clients architect, optimize, and scale their workloads throughout numerous AWS providers. Previous to AWS, he went to Boston College and graduated with a level in Laptop Engineering. You possibly can join with him on LinkedIn.
Mark Vinciguerra is an Affiliate Specialist Options Architect at Amazon Net Providers (AWS) primarily based in New York. He focuses on Generative AI coaching and inference, with the purpose of serving to clients architect, optimize, and scale their workloads throughout numerous AWS providers. Previous to AWS, he went to Boston College and graduated with a level in Laptop Engineering. You possibly can join with him on LinkedIn.
 Anoop Saha is a Sr GTM Specialist at Amazon Net Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with prime frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and enormous companies, primarily specializing in silicon and system structure of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Net Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with prime frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and enormous companies, primarily specializing in silicon and system structure of AI infrastructure.
 Monidipa Chakraborty at present serves as a Senior Software program Growth Engineer at Amazon Net Providers (AWS), particularly inside the SageMaker HyperPod workforce. She is dedicated to helping clients by designing and implementing strong and scalable methods that exhibit operational excellence. Bringing almost a decade of software program growth expertise, Monidipa has contributed to varied sectors inside Amazon, together with Video, Retail, Amazon Go, and AWS SageMaker.
Monidipa Chakraborty at present serves as a Senior Software program Growth Engineer at Amazon Net Providers (AWS), particularly inside the SageMaker HyperPod workforce. She is dedicated to helping clients by designing and implementing strong and scalable methods that exhibit operational excellence. Bringing almost a decade of software program growth expertise, Monidipa has contributed to varied sectors inside Amazon, together with Video, Retail, Amazon Go, and AWS SageMaker.
 Arun Nagpal is a Sr Technical Account Supervisor & Enterprise Help Lead at Amazon Net Providers (AWS), specializing in driving generative AI and supporting startups via enterprise-wide cloud transformations. He focuses on adopting AI providers inside AWS and aligning expertise methods with enterprise goals to realize impactful outcomes.
Arun Nagpal is a Sr Technical Account Supervisor & Enterprise Help Lead at Amazon Net Providers (AWS), specializing in driving generative AI and supporting startups via enterprise-wide cloud transformations. He focuses on adopting AI providers inside AWS and aligning expertise methods with enterprise goals to realize impactful outcomes.
 Daiming Yang is a technical chief at AWS, engaged on machine studying infrastructure that allows large-scale coaching and inference workloads. He has contributed to a number of AWS providers and is proficient in numerous AWS applied sciences, with experience in distributed methods, Kubernetes, and cloud-native structure. Obsessed with constructing dependable, customer-focused options, he focuses on reworking advanced technical challenges into easy, strong methods that scale globally.
Daiming Yang is a technical chief at AWS, engaged on machine studying infrastructure that allows large-scale coaching and inference workloads. He has contributed to a number of AWS providers and is proficient in numerous AWS applied sciences, with experience in distributed methods, Kubernetes, and cloud-native structure. Obsessed with constructing dependable, customer-focused options, he focuses on reworking advanced technical challenges into easy, strong methods that scale globally.
 Kunal Jha is a Principal Product Supervisor at AWS, the place he focuses on constructing Amazon SageMaker HyperPod to allow scalable distributed coaching and fine-tuning of basis fashions. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. You possibly can join with him on LinkedIn.
Kunal Jha is a Principal Product Supervisor at AWS, the place he focuses on constructing Amazon SageMaker HyperPod to allow scalable distributed coaching and fine-tuning of basis fashions. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. You possibly can join with him on LinkedIn.
 Sai Kiran Akula is an engineering chief at AWS, engaged on the HyperPod workforce centered on enhancing infrastructure for machine studying coaching/inference jobs. He has contributed to core AWS providers like EC2, ECS, Fargate, and SageMaker companion AI apps. With a background in distributed methods, he focuses on constructing dependable and scalable options throughout groups.
Sai Kiran Akula is an engineering chief at AWS, engaged on the HyperPod workforce centered on enhancing infrastructure for machine studying coaching/inference jobs. He has contributed to core AWS providers like EC2, ECS, Fargate, and SageMaker companion AI apps. With a background in distributed methods, he focuses on constructing dependable and scalable options throughout groups.

{kind=link}
{kind=link}