


On this put up, we talk about what embeddings are, present the right way to virtually use language embeddings, and discover the right way to use them so as to add performance reminiscent of zero-shot classification and semantic search. We then use Amazon Bedrock and language embeddings so as to add these options to a really simple syndication (RSS) aggregator software.
Amazon Bedrock is a totally managed service that makes basis fashions (FMs) from main AI startups and Amazon obtainable via an API, so you may select from a variety of FMs to seek out the mannequin that’s finest suited to your use case. Amazon Bedrock presents a serverless expertise, so you may get began shortly, privately customise FMs with your personal knowledge, and combine and deploy them into your functions utilizing Amazon Net Companies (AWS) companies with out having to handle infrastructure. For this put up, we use the Cohere v3 Embed mannequin on Amazon Bedrock to create our language embeddings.
Use case: RSS aggregator
To exhibit a number of the potential makes use of of those language embeddings, we developed an RSS aggregator web site. RSS is an internet feed that enables publications to publish updates in a standardized, computer-readable method. On our web site, customers can subscribe to an RSS feed and have an aggregated, categorized record of the brand new articles. We use embeddings so as to add the next functionalities:
- Zero-shot classification – Articles are labeled between totally different subjects. There are some default subjects, reminiscent of Know-how, Politics, and Well being & Wellbeing, as proven within the following screenshot. Customers can even create their very own subjects.
- Semantic search – Customers can search their articles utilizing semantic search, as proven within the following screenshot. Customers cannot solely seek for a particular subject but in addition slim their search by components reminiscent of tone or model.
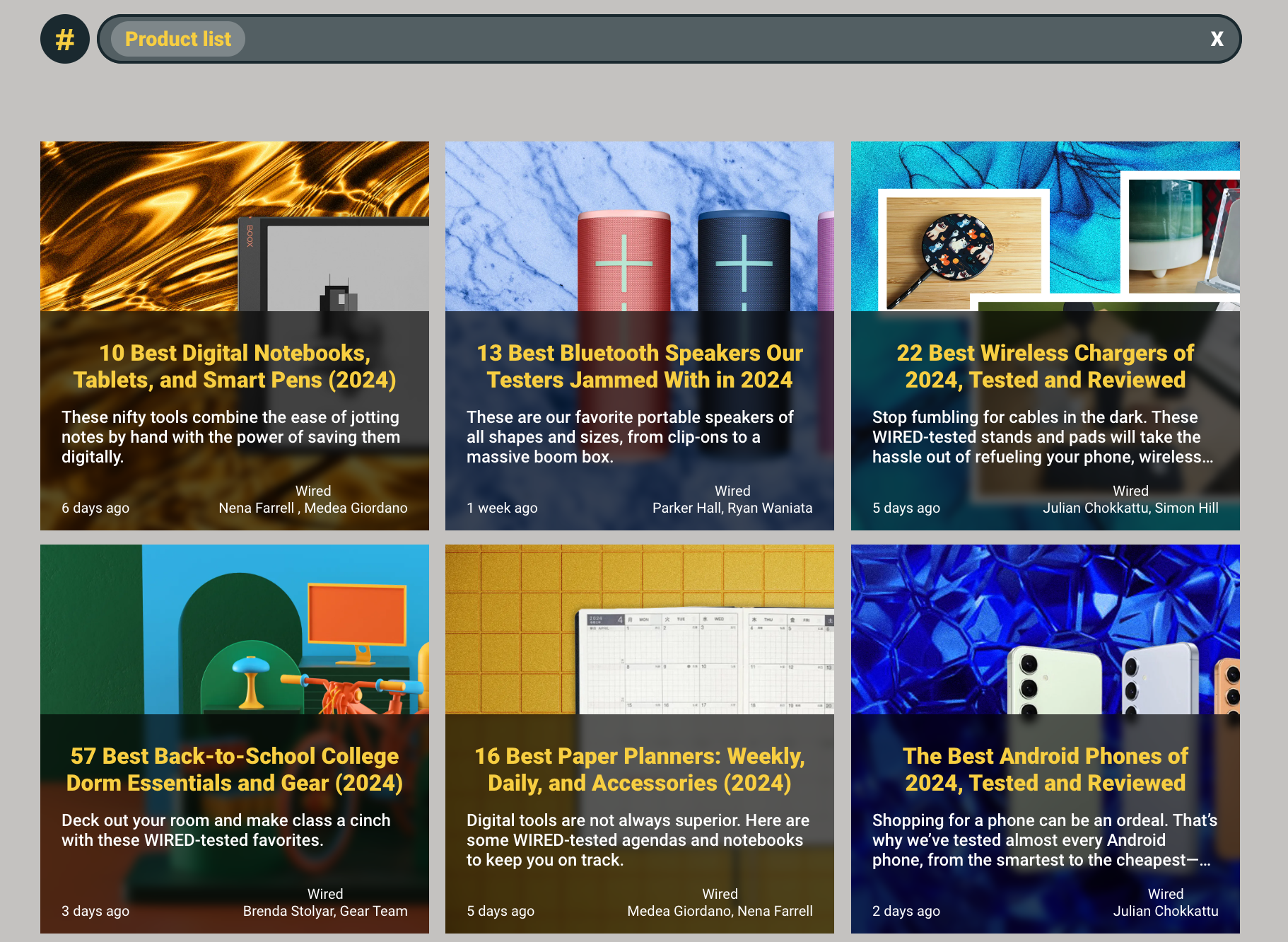
This put up makes use of this software as a reference level to debate the technical implementation of the semantic search and zero-shot classification options.
Answer overview
This resolution makes use of the next companies:
- Amazon API Gateway – The API is accessible via Amazon API Gateway. Caching is carried out on Amazon CloudFront for sure subjects to ease the database load.
- Amazon Bedrock with Cohere v3 Embed – The articles and subjects are transformed into embeddings with the assistance of Amazon Bedrock and Cohere v3 Embed.
- Amazon CloudFront and Amazon Easy Storage Service (Amazon S3) – The one-page React software is hosted utilizing Amazon S3 and Amazon CloudFront.
- Amazon Cognito – Authentication is completed utilizing Amazon Cognito consumer swimming pools.
- Amazon EventBridge – Amazon EventBridge and EventBridge schedules are used to coordinate new updates.
- AWS Lambda – The API is a Fastify software written in TypeScript. It’s hosted on AWS Lambda.
- Amazon Aurora PostgreSQL-Suitable Version and pgvector – Amazon Aurora PostgreSQL-Suitable is used because the database, each for the performance of the appliance itself and as a vector retailer utilizing pgvector.
- Amazon RDS Proxy – Amazon RDS Proxy is used for connection pooling.
- Amazon Easy Queue Service (Amazon SQS) – Amazon SQS is used to queue occasions. It consumes one occasion at a time so it doesn’t hit the speed restrict of Cohere in Amazon Bedrock.
The next diagram illustrates the answer structure.

What are embeddings?
This part presents a fast primer on what embeddings are and the way they can be utilized.
Embeddings are numerical representations of ideas or objects, reminiscent of language or pictures. On this put up, we talk about language embeddings. By lowering these ideas to numerical representations, we will then use them in a method that a pc can perceive and function on.
Let’s take Berlin and Paris for example. As people, we perceive the conceptual hyperlinks between these two phrases. Berlin and Paris are each cities, they’re capitals of their respective nations, and so they’re each in Europe. We perceive their conceptual similarities nearly instinctively, as a result of we will create a mannequin of the world in our head. Nonetheless, computer systems haven’t any built-in method of representing these ideas.
To signify these ideas in a method a pc can perceive, we convert them into language embeddings. Language embeddings are excessive dimensional vectors that be taught their relationships with one another via the coaching of a neural community. Throughout coaching, the neural community is uncovered to monumental quantities of textual content and learns patterns primarily based on how phrases are colocated and relate to one another in numerous contexts.
Embedding vectors enable computer systems to mannequin the world from language. As an illustration, if we embed “Berlin” and “Paris,” we will now carry out mathematical operations on these embeddings. We will then observe some pretty fascinating relationships. As an illustration, we might do the next: Paris – France + Germany ~= Berlin. It is because the embeddings seize the relationships between the phrases “Paris” and “France” and between “Germany” and “Berlin”—particularly, that Paris and Berlin are each capital cities of their respective nations.
The next graph reveals the phrase vector distance between nations and their respective capitals.

Subtracting “France” from “Paris” removes the nation semantics, leaving a vector representing the idea of a capital metropolis. Including “Germany” to this vector, we’re left with one thing intently resembling “Berlin,” the capital of Germany. The vectors for this relationship are proven within the following graph.

For our use case, we use the pre-trained Cohere Embeddings mannequin in Amazon Bedrock, which embeds complete texts fairly than a single phrase. The embeddings signify the that means of the textual content and will be operated on utilizing mathematical operations. This property will be helpful to map relationships reminiscent of similarity between texts.
Zero-shot classification
A method through which we use language embeddings is by utilizing their properties to calculate how comparable an article is to one of many subjects.
To do that, we break down a subject right into a sequence of various and associated embeddings. As an illustration, for tradition, we now have a set of embeddings for sports activities, TV packages, music, books, and so forth. We then embed the incoming title and outline of the RSS articles, and calculate the similarity in opposition to the subject embeddings. From this, we will assign subject labels to an article.
The next determine illustrates how this works. The embeddings that Cohere generates are extremely dimensional, containing 1,024 values (or dimensions). Nonetheless, to exhibit how this technique works, we use an algorithm designed to scale back the dimensionality of the embeddings, t-distributed Stochastic Neighbor Embedding (t-SNE), in order that we will view them in two dimensions. The next picture makes use of these embeddings to visualise how subjects are clustered primarily based on similarity and that means.

You need to use the embedding of an article and verify the similarity of the article in opposition to the previous embeddings. You’ll be able to then say that if an article is clustered intently to one in every of these embeddings, it may be labeled with the related subject.
That is the k-nearest neighbor (k-NN) algorithm. This algorithm is used to carry out classification and regression duties. In k-NN, you can also make assumptions round a knowledge level primarily based on its proximity to different knowledge factors. As an illustration, you may say that an article that has proximity to the music subject proven within the previous diagram will be tagged with the tradition subject.
The next determine demonstrates this with an ArsTechnica article. We plot in opposition to the embedding of an article’s title and outline: (The local weather is altering so quick that we haven’t seen how unhealthy excessive climate might get: Many years-old statistics now not signify what is feasible within the current day).

The benefit of this strategy is that you would be able to add customized, user-generated subjects. You’ll be able to create a subject by first making a sequence of embeddings of conceptually associated objects. As an illustration, an AI subject could be just like the embeddings for AI, Generative AI, LLM, and Anthropic, as proven within the following screenshot.

In a conventional classification system, we’d be required to coach a classifier—a supervised studying job the place we’d want to supply a sequence of examples to ascertain whether or not an article belongs to its respective subject. Doing so will be fairly an intensive job, requiring labeled knowledge and coaching the mannequin. For our use case, we will present examples, create a cluster, and tag articles with out having to supply labeled examples or prepare extra fashions. That is proven within the following screenshot of outcomes web page of our web site.
In our software, we ingest new articles on a schedule. We use EventBridge schedules to periodically name a Lambda perform, which checks if there are new articles. If there are, it creates an embedding from them utilizing Amazon Bedrock and Cohere.
We calculate the article’s distance to the totally different subject embeddings, and might then decide whether or not the article belongs to that class. That is performed with Aurora PostgreSQL with pgvector. We retailer the embeddings of the subjects after which calculate their distance utilizing the next SQL question:
The <-> operator within the previous code calculates the Euclidean distance between the article and the subject embedding. This quantity permits us to grasp how shut an article is to one of many subjects. We will then decide the appropriateness of a subject primarily based on this rating.
We then tag the article with the subject. We do that in order that the next request for a subject is as computationally as gentle as potential; we do a easy be a part of fairly than calculating the Euclidean distance.
We additionally cache a particular subject/feed mixture as a result of these are calculated hourly and aren’t anticipated to alter within the interim.
Semantic search
As beforehand mentioned, the embeddings produced by Cohere include a mess of options; they embed the meanings and semantics of a phrase of phrase. We’ve additionally discovered that we will carry out mathematical operations on these embeddings to do issues reminiscent of calculate the similarity between two phrases or phrases.
We will use these embeddings and calculate the similarity between a search time period and an embedding of an article with the k-NN algorithm to seek out articles which have comparable semantics and meanings to the search time period we’ve offered.
For instance, in one in every of our RSS feeds, we now have quite a lot of totally different articles that charge merchandise. In a conventional search system, we’d depend on key phrase matches to supply related outcomes. Though it may be easy to discover a particular article (for instance, by looking “finest digital notebooks”), we would wish a special methodology to seize a number of product record articles.
In a semantic search system, we first remodel the time period “Product record” in an embedding. We will then use the properties of this embedding to carry out a search inside our embedding house. Utilizing the k-NN algorithm, we will discover articles which might be semantically comparable. As proven within the following screenshot, regardless of not containing the textual content “Product record” in both the title or description, we’ve been capable of finding articles that include a product record. It is because we had been in a position to seize the semantics of the question and match it to the prevailing embeddings we now have for every article.
In our software, we retailer these embeddings utilizing pgvector on Aurora PostgreSQL. pgvector is an open supply extension that permits vector similarity search in PostgreSQL. We remodel our search time period into an embedding utilizing Amazon Bedrock and Cohere v3 Embed.
After we’ve transformed the search time period to an embedding, we will evaluate it with the embeddings on the article which have been saved through the ingestion course of. We will then use pgvector to seek out articles which might be clustered collectively. The SQL code for that’s as follows:
This code calculates the space between the subjects, and the embedding of this text as “similarity.” If this distance is shut, then we will assume that the subject of the article is expounded, and we due to this fact connect the subject to the article.
Conditions
To deploy this software in your personal account, you want the next conditions:
- An energetic AWS account.
- Mannequin entry for Cohere Embed English. On the Amazon Bedrock console, select Mannequin entry within the navigation pane, then select Handle mannequin entry. Choose the FMs of your selection and request entry.

Deploy the AWS CDK stack
When the prerequisite steps are full, you’re able to arrange the answer:
- Clone the GitHub repository containing the answer information:
git clone https://github.com/aws-samples/rss-aggregator-using-cohere-embeddings-bedrock
- Navigate to the answer listing:
cd infrastructure
- In your terminal, export your AWS credentials for a task or consumer in ACCOUNT_ID. The position must have all crucial permissions for AWS CDK deployment:
- export AWS_REGION=”<area>”
– The AWS Area you wish to deploy the appliance to - export AWS_ACCESS_KEY_ID=”<access-key>”
– The entry key of your position or consumer - export AWS_SECRET_ACCESS_KEY=”<secret-key>”
– The key key of your position or consumer
- export AWS_REGION=”<area>”
- In the event you’re deploying the AWS CDK for the primary time, run the next command:
cdk bootstrap
- To synthesize the AWS CloudFormation template, run the next command:
cdk synth -c vpc_id=<ID Of your VPC>
- To deploy, use the next command:
cdk deploy -c vpc_id=<ID Of your VPC>
When deployment is completed, you may verify these deployed stacks by visiting the AWS CloudFormation console, as proven within the following screenshot.

Clear up
Run the next command within the terminal to delete the CloudFormation stack provisioned utilizing the AWS CDK:
cdk destroy --all
Conclusion
On this put up, we explored what language embeddings are and the way they can be utilized to reinforce your software. We’ve realized how, by utilizing the properties of embeddings, we will implement a real-time zero-shot classifier and might add highly effective options reminiscent of semantic search.
The code for this software will be discovered on the accompanying GitHub repo. We encourage you to experiment with language embeddings and discover out what highly effective options they’ll allow to your functions!
In regards to the Creator
 Thomas Rogers is a Options Architect primarily based in Amsterdam, the Netherlands. He has a background in software program engineering. At AWS, Thomas helps prospects construct cloud options, specializing in modernization, knowledge, and integrations.
Thomas Rogers is a Options Architect primarily based in Amsterdam, the Netherlands. He has a background in software program engineering. At AWS, Thomas helps prospects construct cloud options, specializing in modernization, knowledge, and integrations.

{kind=link}