


Common duties, together with steady numerical predictions, have historically depend on numerical heads corresponding to Gaussa parameters and level -to -wiztensol tasks. These typical approaches have a robust distribution requirement, requires many labeled knowledge, and tends to disassemble when modeling superior numerical distribution. New analysis on giant language fashions introduces completely different approaches. Specific the numerical worth as a sequence of a discrete token and use computerized regression decodes for prediction. Nonetheless, this shift consists of the necessity for environment friendly tokenization mechanism, the potential for numerical accuracy loss, the potential for steady coaching, and the necessity to overcome the continual token -type induction bias. There are some severe duties. worth. Overcoming these points will result in a stronger, excessive -data effectivity, versatile regression framework, and can broaden the appliance of deep studying fashions past the traditional method.
The traditional regression mannequin is determined by the numerical tensor challenge or parametric distribution head corresponding to Gaussian fashions. These typical approaches are spreading, however there are some drawbacks. The Gaussian -based mannequin has the downside of assuming the output of the traditional distribution, limiting the flexibility to mannequin extra superior multimodal distribution. Pointwise regression heads wrestle with very non -linear or sudden relationships and restrict the generalization of assorted datasets. Excessive -dimensional fashions, such because the histogram -based Riemann distribution, are calculated, knowledge -integrated, and thus, inefficient. As well as, many typical approaches require specific normalization or output scaling, introducing further complexity and potential instability. Within the typical work, we tried to make use of a big language mannequin to undertake a return from textual content to textual content, however many of the work is nearly systematic for “something from textual content” the place numerical output is a token sequence. A brand new paradigm might be launched as a result of it isn’t performed. Numerical prediction.
Google Deepmind researchers suggest various regression formulation and reconstruct numerical predictions as computerized regression sequencing points. As a substitute of producing scalar values instantly, this methodology encodes the numerical worth as a token sequence and makes use of a constrained decoding to generate legitimate numerical output. Encoding the numerical worth as a discrete token sequence, which makes this methodology extra versatile and expressive when modeling the precise knowledge. Not like Gaussian -based approaches, this methodology doesn’t accompany the information on the information, so it may be generalized by precise duties with uneven patterns. This mannequin helps the correct modeling of the complicated distribution of multi -modal, enhancing the efficiency of density and pointwise regression duties. By using some great benefits of computerized regression decoders, we are going to keep aggressive efficiency in comparison with customary numerical heads and reap the benefits of the current progress of language modeling. This system supplies a sturdy and versatile framework that may precisely mannequin a variety of numerical relationships, and supplies a sensible various to straightforward regression strategies which can be often thought-about versatile.
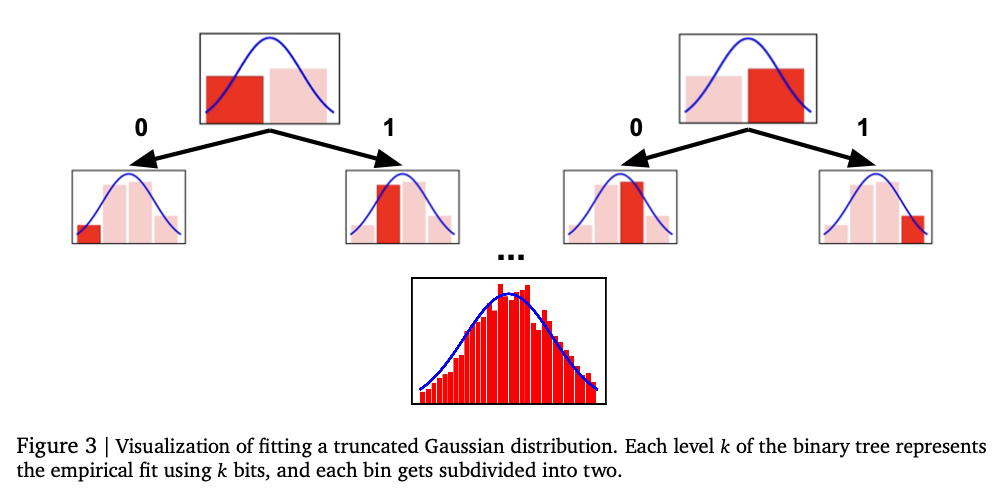
This method makes use of two token strategies for numerical expression: normalized token and non -normalized token. The normalized token conversion is encoded with a hard and fast vary worth with a base B extension, and supplies extra accuracy because the sequence size will increase. Non-formal tokenization extends the identical concept to a wider vary of numbers, with generalized floating-point expressions corresponding to IEEE-754 with out the necessity for specific normalization. The transformer computerized regression mannequin generates a numerical output token token on a situation for offering legitimate numerical sequences. This mannequin is educated utilizing cross -entropy loss on token sequences and supplies correct numerical expressions. As a substitute of instantly predict scalar output, the system samples token sequences and makes use of statistical estimation applied sciences corresponding to common or median calculation for remaining predictions. The analysis is carried out within the precise desk regression dataset of the OpenML-CTR23 and AMLB benchmarks, in comparison with the Gaussian combination mannequin, histogram-based regression, and customary level of regression head. Hyper parameter tuning is executed in numerous decoders, corresponding to layers, hidden items, and token vocabulary fluctuations to offer optimized efficiency.
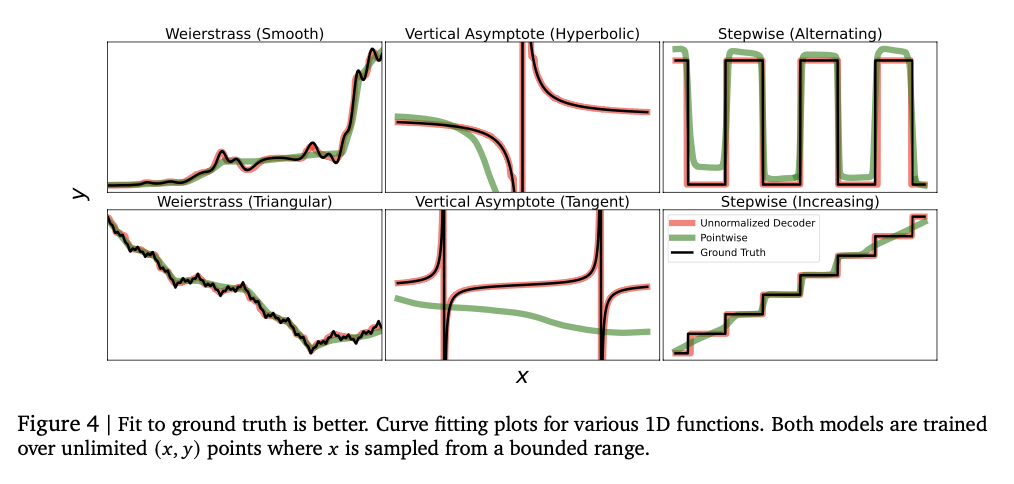
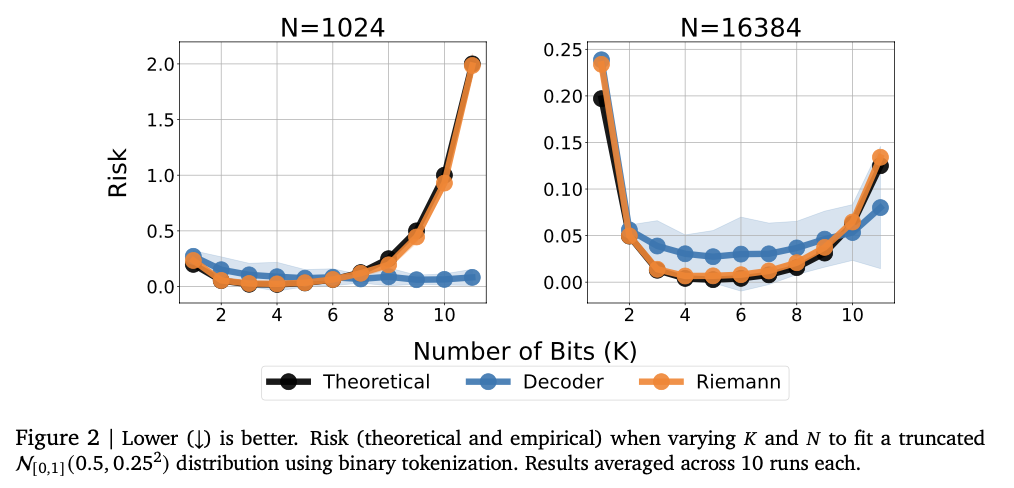
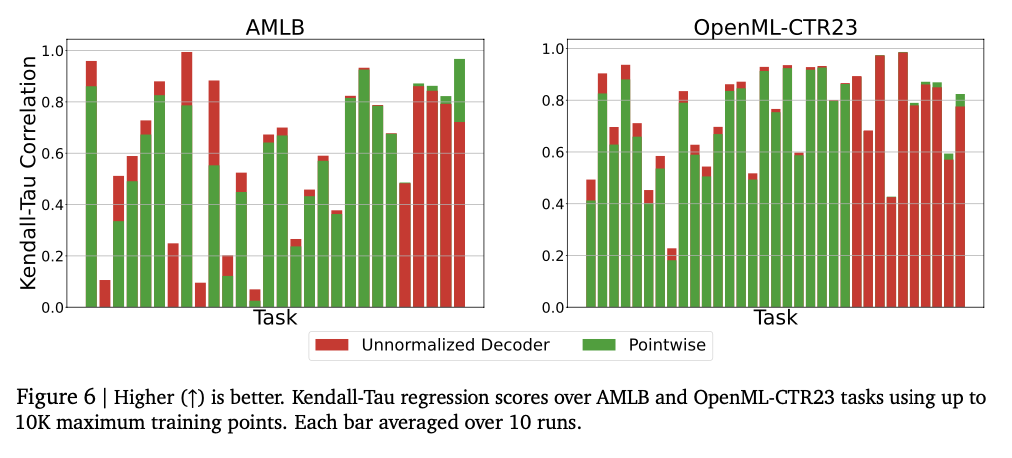
The experiment signifies that the mannequin captures complicated numerical relationships usually and achieves highly effective efficiency with numerous regression duties. Low knowledge setting, which is especially indispensable to the steadiness of numerical values, usually achieves a excessive Kendarto correlation rating by returning to the desk mannequin, which regularly exceeds the bottom line mannequin. This methodology can be wonderful within the estimation of density, capturing complicated distribution captures, outpering the Gaussian blended mannequin, and exceeds the Lehman -based method in Negat Bloglykeria Quick. The mannequin measurement tuning at first improves efficiency and causes extra capability. The steadiness of the numerical values is drastically improved by error correction strategies corresponding to tokens and majority vote, minimizing the vulnerability in opposition to the outlook worth. These outcomes have proven this regression framework, which is a sturdy and adaptive various to the traditional methodology, and has proven the flexibility to achieve numerous datasets and modeling duties.
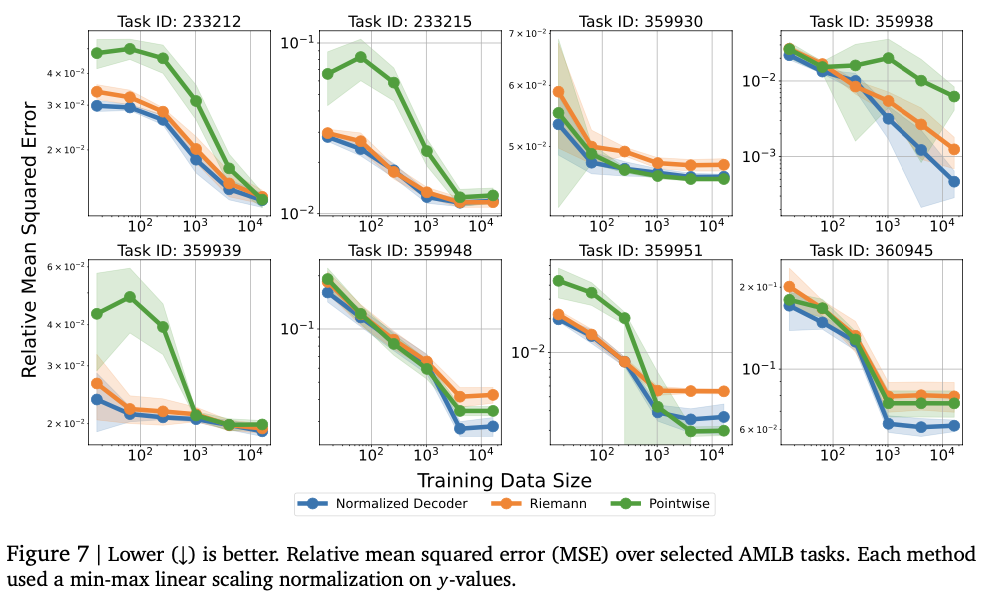
This work introduces a brand new method to numerical prediction by using tokenized expressions and computerized regression decodes. By changing the traditional regression head with a token -based output, this framework improves the flexibleness of actual numbers knowledge modeling. Whereas offering theoretical assure to roughly the chance distribution, we are going to present a wide range of regression duties, particularly density, and a aggressive efficiency. Particularly with complicated distribution and sparse coaching knowledge modeling, vital context is healthier than typical regression strategies. For future duties, we are going to enhance the token methodology to enhance numerical accuracy and stability, broaden frameworks to multi -output regression and excessive -dimensional prediction duties, and estimate the reinforcement studying compensation modeling and visible -based numerical values. Investigating the appliance. These outcomes will improve the scope of duties that may be solved usually for the traditional methodology of the traditional methodology of sequence -based numerical returns.
Examine -out paper and GitHub page。 All credit of this research are despatched to researchers on this challenge. Additionally, remember to observe us Twitter And please be a part of us Telegram channel and Linkedin GROUP。 Do not forget to take part in us 75k+ ml subbreddit。
Lingering MarktechPost invitations AI corporations/startups/teams to future AI journal companions on “Open Supply AI” and “Agent AI”.
ASWIN AK is a MarktechPost consulting intern. He’s pursuing a double diploma in Haragpool at Indian College of Know-how. He’s keen about knowledge science and machine studying, giving a background and sensible expertise of educational work to unravel actual cross -domain points.

{kind=link}