


Based on the Nationwide Most cancers Institute, a cancer biomarker is a “organic molecule present in blood, different physique fluids, or tissues that could be a signal of a traditional or irregular course of, or of a situation or illness corresponding to most cancers.” Biomarkers sometimes differentiate an affected affected person from an individual with out the illness. Properly-known most cancers biomarkers embrace EGFR for lung most cancers, HER2 for breast most cancers, PSA for prostrate most cancers, and so forth. The BEST (Biomarkers, EndpointS, and different Instruments) useful resource categorizes biomarkers into a number of varieties corresponding to diagnostic, prognostic, and predictive biomarkers that may be measured with varied methods together with molecular, imaging, and physiological measurements.
A study printed in Nature Opinions Drug Discovery mentions that the general success price for oncology medicine from Section I to approval is barely round 5%. Biomarkers play an important position in enhancing the success of medical growth by enhancing affected person stratification for trials, expediting drug growth, decreasing prices and dangers, and enabling customized drugs. For instance, a study of 1,079 oncology medicine discovered that the success charges for medicine developed with a biomarker was 24% versus 6% for compounds developed with out biomarkers.
Analysis scientists and real-world proof (RWE) consultants face quite a few challenges to investigate biomarkers and validate hypotheses for biomarker discovery with their present set of instruments. Most notably, this contains guide and time-consuming steps for search, summarization, and perception technology throughout varied biomedical literature (for instance, PubMed), public scientific databases (for instance, Protein Knowledge Financial institution), industrial information banks and inner enterprise proprietary information. They need to rapidly use, modify, or develop instruments crucial for biomarker identification and correlation throughout modalities, indications, drug exposures and coverings, and related endpoint outcomes corresponding to survival. Every experiment may make use of varied mixtures of knowledge, instruments, and visualization. Proof in scientific literature needs to be easy to establish and cite with related context.
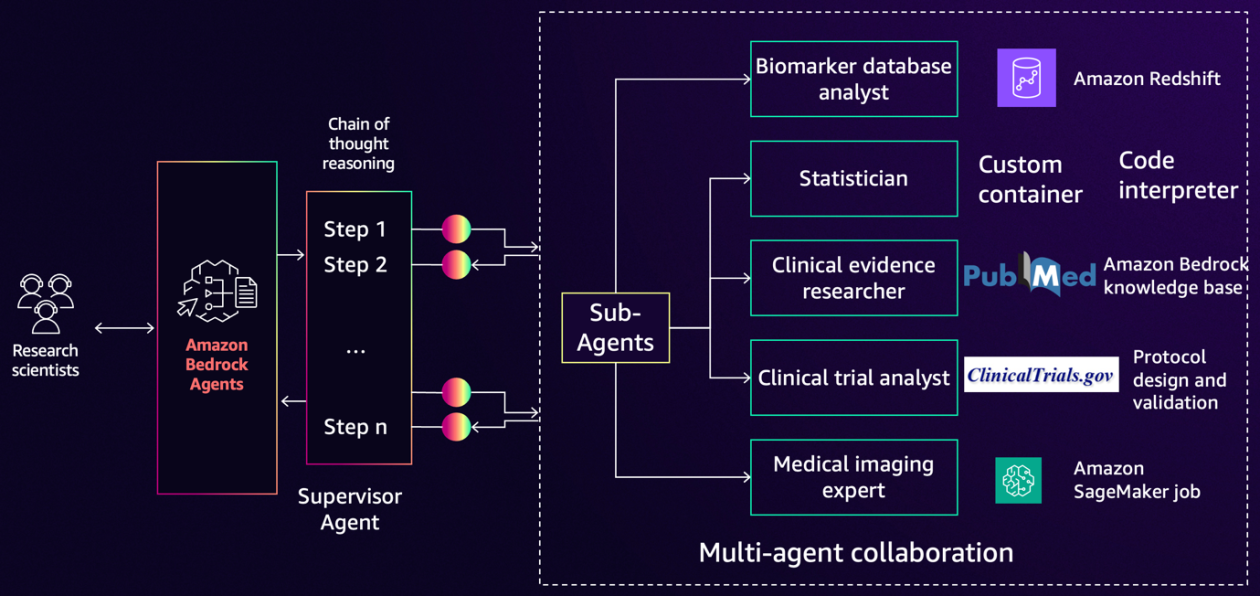
Amazon Bedrock Brokers allows generative AI functions to automate multistep duties by seamlessly connecting with firm methods, APIs, and information sources. Bedrock multi-agent collaboration allows builders to construct, deploy, and handle a number of specialised brokers working collectively seamlessly to deal with more and more complicated enterprise workflows. On this publish, we present you the way agentic workflows with Amazon Bedrock Brokers will help speed up this journey for analysis scientists with a pure language interface. We outline an instance evaluation pipeline, particularly for lung most cancers survival with medical, genomics, and imaging modalities of biomarkers. We showcase quite a lot of specialised brokers together with a biomarker database analyst, statistician, medical proof researcher, and medical imaging skilled in collaboration with a supervisor agent. We display superior capabilities of brokers for self-review and planning that assist construct belief with finish customers by breaking down complicated duties right into a collection of steps and exhibiting the chain of thought to generate the ultimate reply. The code for this answer is on the market in GitHub.
Multi-modal biomarker evaluation workflow
Some instance scientific necessities from analysis scientists analyzing multi-modal affected person biomarkers embrace:
- What are the highest 5 biomarkers related to general survival? Present me a Kaplan Meier plot for top and low danger sufferers.
- Based on literature proof, what properties of the tumor are related to metagene X exercise and EGFR pathway?
- Are you able to compute the imaging biomarkers for the affected person cohort with low gene X expression? Present me the tumor segmentation and the sphericity and elongation values.
To reply the previous questions, analysis scientists sometimes run a survival evaluation pipeline (as proven within the following illustration) with multimodal information; together with medical, genomic, and computed tomography (CT) imaging information.
They could must:
- Preprocess programmatically a various set of enter information, structured and unstructured, and extract biomarkers (radiomic/genomic/medical and others).
- Conduct statistical survival analyses such because the Cox proportional hazards mannequin, and generate visuals corresponding to Kaplan-Meier curves for interpretation.
- Conduct gene set enrichment evaluation (GSEA) to establish vital genes.
- Analysis related literature to validate preliminary findings.
- Affiliate findings to radiogenomic biomarkers.
Resolution overview
We suggest a large-language-model (LLM) agents-based framework to reinforce and speed up the above evaluation pipeline. Design patterns for LLM brokers, as described in Agentic Design Patterns Part 1 by Andrew Ng, embrace the capabilities for reflection, instrument use, planning and multi-agent collaboration. An agent helps customers full actions based mostly on each proprietary and public information and consumer enter. Brokers orchestrate interactions between basis fashions (FMs), information sources, software program functions, and consumer conversations. As well as, brokers mechanically name APIs to take actions and search information bases to complement data for these actions.

As proven within the previous determine, we outline our answer to incorporate planning and reasoning with a number of sub-agents together with:
- Biomarker database analyst: Convert pure language inquiries to SQL statements and execute on an Amazon Redshift database of biomarkers.
- Statistician: Use a customized container with lifelines library to construct survival regression fashions and visualization corresponding to Kaplan Meier charts for survival evaluation.
- Scientific proof researcher: Use PubMed APIs to go looking biomedical literature for exterior proof. Use Amazon Bedrock Data Bases for Retrieval Augmented Era (RAG) to ship responses from inner literature proof.
- Scientific trial analyst: Use Clinicaltrials.gov APIs to go looking previous medical trial research.
- Medical imaging skilled: Use Amazon SageMaker jobs to reinforce brokers with the potential to set off asynchronous jobs with an ephemeral cluster to course of CT scan photographs.
Dataset description
The non-small cell lung cancer (NSCLC) radiogenomic dataset includes medical imaging, medical, and genomic information collected from a cohort of early-stage NSCLC sufferers referred for surgical remedy. Every information modality presents a special view of a affected person. It consists of medical information reflective of digital well being data (EHR) corresponding to age, gender, weight, ethnicity, smoking standing, tumor node metastasis (TNM) stage, histopathological grade, and survival consequence. The genomic information comprises gene mutation and RNA sequencing information from samples of surgically excised tumor tissue. It contains CT, positron emission tomography (PET)/CT photographs, semantic annotations of the tumors as noticed on the medical photographs utilizing a managed vocabulary, segmentation maps of tumors within the CT scans, and quantitative values obtained from the PET/CT scans.
We reuse the information pipelines described on this weblog publish.
Scientific information
The info is saved in CSV format as proven within the following desk. Every row corresponds to the medical data of a affected person.
| Case ID | Survival standing | Age at histological prognosis | Weight (lbs) | Smoking standing | Pack years | Give up smoking yr | Chemotherapy | Adjuvant remedy | EGFR mutation standing |
| R01-005 | Useless | 84 | 145 | Former | 20 | 1951 | No | No | Wildtype |
| R01-006 | Alive | 62 | Not collected | Former | Not collected | nan | No | No | Wildtype |
Genomics information
The next desk exhibits the tabular illustration of the gene expression information. Every row corresponds to a affected person, and the columns signify a subset of genes chosen for demonstration. The worth denotes the expression stage of a gene for a affected person. A better worth means the corresponding gene is extremely expressed in that particular tumor pattern.
| Case_ID | LRIG1 | HPGD | GDF15 | CDH2 | POSTN |
| R01-024 | 26.7037 | 3.12635 | 13.0269 | 0 | 36.4332 |
| R01-153 | 15.2133 | 5.0693 | 0.90866 | 0 | 32.8595 |
Medical imaging information
The next picture is an instance overlay of a tumor segmentation onto a lung CT scan (case R01-093 within the dataset).

Deployment and getting began
Observe the deployment directions described within the GitHub repo.
Full deployment takes roughly 10–quarter-hour. After deployment, you’ll be able to entry the pattern UI to check the agent with pattern questions accessible within the UI or the chain of thought reasoning example.
The stack may also be launched within the us-east-1 or us-west-2 AWS Areas by selecting launch stack within the following:
| Area | codepipeline.yaml |
| us-east-1 | |
| us-west-2 |
Amazon Bedrock Brokers deep dive
The next diagram describes the important thing elements of the agent that interacts with the customers by way of an internet software.

Massive language fashions
LLMs, corresponding to Anthropic’s Claude or Amazon Titan fashions, possess the flexibility to grasp and generate human-like textual content. They allow brokers to grasp consumer queries, generate acceptable responses, and carry out complicated reasoning duties. Within the deployment, we use Anthropic’s Claude 3 Sonnet mannequin.
Immediate templates
Immediate templates are pre-designed buildings that information the LLM’s responses and behaviors. These templates assist form the agent’s character, tone, and particular capabilities to grasp scientific terminology. By rigorously crafting immediate templates, you’ll be able to assist make it possible for brokers keep consistency of their interactions and cling to particular tips or model voice. Amazon Bedrock Brokers offers default immediate templates for pre-processing customers’ queries, orchestration, a information base, and a post-processing template.
Directions
Along with the immediate templates, directions describe what the agent is designed to do and the way it can work together with customers. You need to use directions to outline the position of a selected agent and the way it can use the accessible set of actions below completely different circumstances. Directions are augmented with the immediate templates as context for every invocation of the agent. You’ll find how we outline our agent directions in agent_build.yaml.
Consumer enter
Consumer enter is the start line for an interplay with an agent. The agent processes this enter, understanding the consumer’s intent and context, after which formulates an acceptable chain of thought. The agent will decide whether or not it has the required data to reply the consumer’s query or must request extra data from the consumer. If extra data is required from the consumer, the agent will formulate the query to request further data. Amazon Bedrock Brokers are designed to deal with a variety of consumer inputs, from easy queries to complicated, multi-turn conversations.
Amazon Bedrock Data Bases
The Amazon Bedrock information base is a repository of knowledge that has been vectorized from the supply information and that the agent can entry to complement its responses. By integrating an Amazon Bedrock information base, brokers can present extra correct and contextually acceptable solutions, particularly for domain-specific queries which may not be lined by the LLM’s common information. On this answer, we embrace literature on non-small cell lung most cancers that may signify inner proof belonging to a buyer.
Motion teams
Motion teams are collections of particular capabilities or API calls that Amazon Bedrock Brokers can carry out. By defining motion teams, you’ll be able to prolong the agent’s capabilities past mere dialog, enabling it to carry out sensible, real-world duties. The next instruments are made accessible to the agent by way of motion teams within the answer. The supply code may be discovered within the ActionGroups folder within the repository.
- Text2SQL and Redshift database invocation: The Text2SQL motion group permits the agent to get the related schema of the Redshift database, generate a SQL question for the actual sub-question, evaluate and refine the SQL question with a further LLM invocation, and at last execute the SQL question to retrieve the related outcomes from the Redshift database. The motion group comprises OpenAPI schema for these actions. If the question execution returns a consequence better than the acceptable lambda return payload measurement, the motion group writes the information to an intermediate Amazon Easy Storage Service (Amazon S3) location as a substitute.
- Scientific evaluation with a customized container: The scientific evaluation motion group permits the agent to make use of a customized container to carry out scientific evaluation with particular libraries and APIs. On this answer, these embrace duties corresponding to becoming survival regression fashions and Kaplan Meier plot technology for survival evaluation. The customized container permits a consumer to confirm that the outcomes are repeatable with out deviations in library variations or algorithmic logic. This motion group defines capabilities with particular parameters for every of the required duties. The Kaplan Meier plot is output to Amazon S3.
- Biomedical literature proof with PubMed: The PubMed motion group permits the agent to work together with the PubMed Entrez Programming Utilities (E-utilities) API to fetch biomedical literature. The motion group comprises OpenAPI schema that accepts consumer queries to go looking throughout PubMed for articles. The Lambda perform offers a handy solution to seek for and retrieve scientific articles from the PubMed database. It permits customers to carry out searches utilizing particular queries, retrieve article metadata, and deal with the complexities of API interactions. Total, the agent makes use of this motion group and serves as a bridge between a researcher’s question and the PubMed database, simplifying the method of accessing and processing biomedical analysis data.
- Medical imaging with SageMaker jobs: The medical imaging motion group permits the agent to course of CT scan photographs of particular affected person teams by triggering a SageMaker processing job. We re-use the medical imaging element from this earlier weblog.
The motion group creates patient-level third-dimensional radiomic options that specify the scale, form, and visible attributes of the tumors noticed within the CT scans and shops them in Amazon S3. For every affected person examine, the next steps are carried out, as proven within the determine that follows:
- Learn the 2D DICOM slice information for each the CT scan and tumor segmentation, mix them to 3D volumes, and save the volumes in NIfTI format.
- Align CT quantity and tumor segmentation so we are able to focus the computation contained in the tumor.
- Compute radiomic options describing the tumor area utilizing the pyradiomics library. It extracts 120 radiomic features of eight lessons corresponding to statistical representations of the distribution and co-occurrence of the depth inside the tumorous area of curiosity, and shape-based measurements describing the tumor morphologically.

Chain of thought reasoning and responses
Let’s take a look at a couple of examples of chain of thought reasoning and execution with the supervisor agent. The supervisor agent interprets the consumer query, generates a sequence of steps, and executes them with the related sub-agents.
To answer the next questions, the agent units up the next orchestration workflows with the accessible sub-agents.
Query: What’s the finest gene expression biomarker (lowest p worth) with general survival for sufferers which have undergone chemotherapy, present me a bar chart with the highest 5 biomarkers.
- I’ll generate a plan
- Question the biomarker database for sufferers’ information
- Run survival evaluation to search out p-values
- Get the highest 5 biomarkers with lowest p-values and create a visualization
- I’ll ask the Biomarker database analyst
- Get DB schema and generate SQL
- Overview and refine the SQL with self-evaluation
- Execute the SQL question and retailer the ends in Amazon S3
- I’ll ask the Statistician
- Retrieve the generated dataset from the database analyst
- Match a survival regression mannequin with the customized container API
- Retrieve the mannequin match abstract outcomes and kind the highest 5 biomarkers based mostly on the bottom p-value
- Generate a bar chart with the highest 5 biomarkers
Supervisor response: Gene biomarker ‘gdf15’ has the bottom p worth of 0.02, due to this fact gdf15 is the perfect gene biomarker. The bar chart exhibits the highest 5 biomarkers and their corresponding p values.
Query: Based on literature proof, what properties of the tumor are related to metagene X exercise and EGFR pathway?
- I’ll generate a plan
- Route the request to the Scientific proof researcher
- I’ll ask the Scientific proof researcher
- Question inner information base for inner proof
- Question PubMed for exterior literature
- Summarize the outcomes with citations
Supervisor response: Based mostly on inner and exterior proof, imaging properties, molecular traits, drug resistance and therapeutic approaches, signalling pathways and mechanisms, rising therapeutic methods , and mobile properties are related for the EGFR pathway.
Query: Are you able to compute the imaging biomarkers for affected person cohort with low gene X expression? Present me the tumor segmentation and the sphericity and elongation values.
- I’ll generate a plan
- Question the biomarker database to search out the affected person cohort with lowest gdf15 values
- Set off medical imaging evaluation jobs to course of CT scan photographs of the cohort
- Summarize the findings of the imaging jobs.
- I’ll ask the Biomarker database analyst
- Get DB schema and generate SQL
- Overview and refine the SQL with self-evaluation
- Execute the SQL question and retrieve affected person ids
- I’ll ask the medical imaging skilled
- Retrieve the affected person cohort from the database analyst
- Compute imaging biomarkers for every affected person within the cohort with a SageMaker medical imaging job
- On job completion notification, retrieve and analyse the outcomes
- Extract the required biomarkers and visualize the tumour segmentation output photographs
Supervisor response: The compute imaging biomarker job to course of the medical photographs of the sufferers was triggered and is now full. The next sufferers have been chosen based mostly on their gene X expression values. The elongation and sphericity values for the affected person tumours are displayed together with the corresponding tumour segmentation photographs.
Analysis scientists face vital challenges in figuring out and validating biomarkers particular to most cancers subtypes and related to interventions and affected person outcomes. Present instruments usually require intensive guide steps to go looking, summarize, and generate insights throughout various information sources. This publish has demonstrated how Amazon Bedrock Brokers can provide a versatile framework with multi-agent collaboration and related instruments to assist speed up this important discovery course of.
By offering an instance evaluation pipeline for lung most cancers survival, we showcased how these agentic workflows use a pure language interface, database retrieval, statistical modeling, literature search, and medical picture processing to rework complicated analysis queries into actionable insights. The agent used superior and clever capabilities corresponding to self-review and planning, breaking down duties into step-by-step analyses and transparently displaying the chain of thought behind the ultimate solutions. Whereas the potential affect of this know-how on pharmaceutical analysis and medical trial outcomes stays to be totally realized, options like this will help automate information evaluation and speculation validation duties.
The code for this answer is on the market on GitHub, and we encourage you to discover and construct upon this template. For examples to get began with Amazon Bedrock Brokers, take a look at the Amazon Bedrock Agents GitHub repository.
Concerning the authors
 Hasan Poonawala is a Senior AI/ML Options Architect at AWS, working with Healthcare and Life Sciences clients. Hasan helps design, deploy and scale Generative AI and Machine studying functions on AWS. He has over 15 years of mixed work expertise in machine studying, software program growth and information science on the cloud. In his spare time, Hasan likes to discover nature and spend time with family and friends.
Hasan Poonawala is a Senior AI/ML Options Architect at AWS, working with Healthcare and Life Sciences clients. Hasan helps design, deploy and scale Generative AI and Machine studying functions on AWS. He has over 15 years of mixed work expertise in machine studying, software program growth and information science on the cloud. In his spare time, Hasan likes to discover nature and spend time with family and friends.
 Michael Hsieh is a Principal AI/ML Specialist Options Architect. He works with HCLS clients to advance their ML journey with AWS applied sciences and his experience in medical imaging. As a Seattle transplant, he loves exploring the nice mom nature town has to supply, such because the mountaineering trails, surroundings kayaking within the SLU, and the sundown at Shilshole Bay.
Michael Hsieh is a Principal AI/ML Specialist Options Architect. He works with HCLS clients to advance their ML journey with AWS applied sciences and his experience in medical imaging. As a Seattle transplant, he loves exploring the nice mom nature town has to supply, such because the mountaineering trails, surroundings kayaking within the SLU, and the sundown at Shilshole Bay.
 Nihir Chadderwala is a Senior AI/ML Options Architect on the International Healthcare and Life Sciences workforce. His background is constructing large information and AI-powered options to buyer issues in quite a lot of domains corresponding to software program, media, automotive, and healthcare. In his spare time, he enjoys taking part in tennis, and watching and studying about Cosmos.
Nihir Chadderwala is a Senior AI/ML Options Architect on the International Healthcare and Life Sciences workforce. His background is constructing large information and AI-powered options to buyer issues in quite a lot of domains corresponding to software program, media, automotive, and healthcare. In his spare time, he enjoys taking part in tennis, and watching and studying about Cosmos.
 Zeek Granston is an Affiliate AI/ML Options Architect targeted on constructing efficient synthetic intelligence and machine studying options. He stays present with business traits to ship sensible outcomes for shoppers. Exterior of labor, Zeek enjoys constructing AI functions, and taking part in basketball.
Zeek Granston is an Affiliate AI/ML Options Architect targeted on constructing efficient synthetic intelligence and machine studying options. He stays present with business traits to ship sensible outcomes for shoppers. Exterior of labor, Zeek enjoys constructing AI functions, and taking part in basketball.

{kind=link}