


Regardless of the transformative potential of large-scale language fashions (LLMs), these fashions face vital challenges in producing contextually correct responses which are trustworthy to the enter supplied. . Guaranteeing the factuality of LLM output is very vital for duties that require solutions primarily based on lengthy, advanced paperwork which are the premise for additional purposes in analysis, schooling, and trade.
One of many main challenges in LLM improvement is the tendency to supply inaccurate or “hallucinatory” content material. This difficulty happens when the mannequin produces believable textual content that’s not supported by the enter information. Such inaccuracies can have critical penalties, together with the unfold of misinformation and lowered belief in AI techniques. Addressing this difficulty requires a complete benchmark that evaluates the constancy of LLM output to make sure that the generated textual content carefully matches the context supplied within the immediate.
Current options to the factuality problem embrace supervised fine-tuning and reinforcement studying. Though these strategies have limitations, they goal to optimize the LLM to extra carefully adhere to the factual content material. One other method leverages inference time methods equivalent to superior prompting and interpretability of mannequin states to cut back inaccuracy. Nonetheless, these methods usually introduce trade-offs, compromising qualities equivalent to creativity and response range. Subsequently, there stays a necessity for a sturdy and scalable framework to systematically consider and improve the facticity of LLMs with out sacrificing different attributes.
Researchers from Google DeepMind, Google Analysis, Google Cloud, and Kaggle launched the FACTS Grounding Leaderboard to deal with these gaps. This benchmark is particularly designed to measure LLM’s capacity to generate responses which are totally primarily based on a variety of enter contexts. The dataset incorporates person requests mixed with as much as 32,000 tokens of supply paperwork to request responses which are factually right and strictly conform to the enter context. The leaderboard is hosted on Kaggle and features a separation of private and non-private information to encourage broad participation whereas sustaining the integrity of the dataset.
The methodology underlying the FACTS Grounding benchmark entails a two-step analysis course of. First, solutions shall be reviewed for eligibility, and solutions that don’t adequately handle the person’s request shall be disqualified. Eligible solutions are then evaluated for factuality utilizing a number of automated resolution fashions, together with Gemini 1.5 Professional, GPT-4o, and Claude 3.5 Sonnet. These fashions are prompted utilizing optimized templates to make sure a excessive diploma of consistency with human judgment. For instance, the analysis course of makes use of span-level evaluation to check every declare in a response and combination scores throughout a number of fashions to attenuate bias. Moreover, the benchmark incorporates measures to stop gaming of the scoring system, equivalent to requiring complete responses that instantly handle the person’s query.
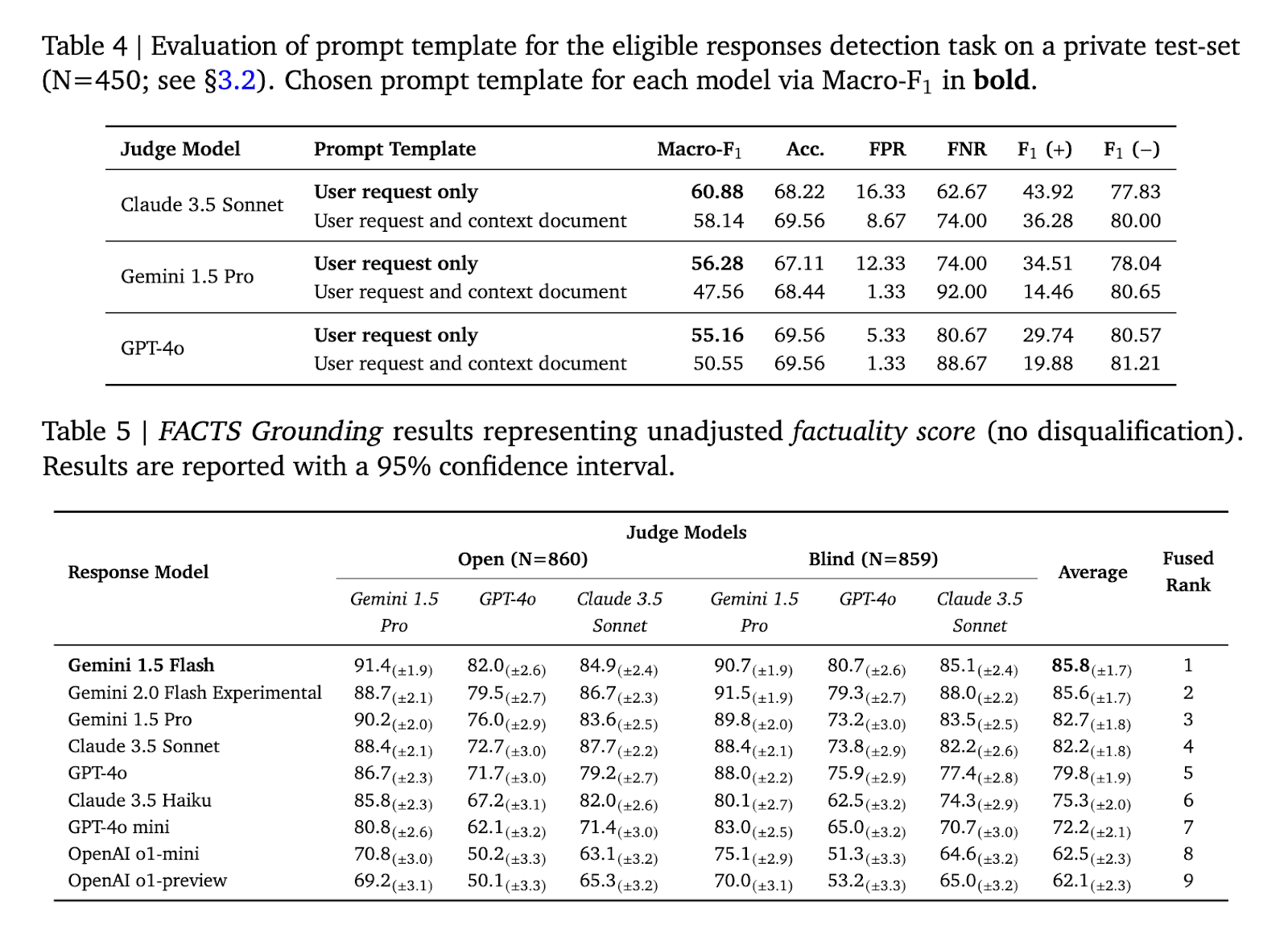
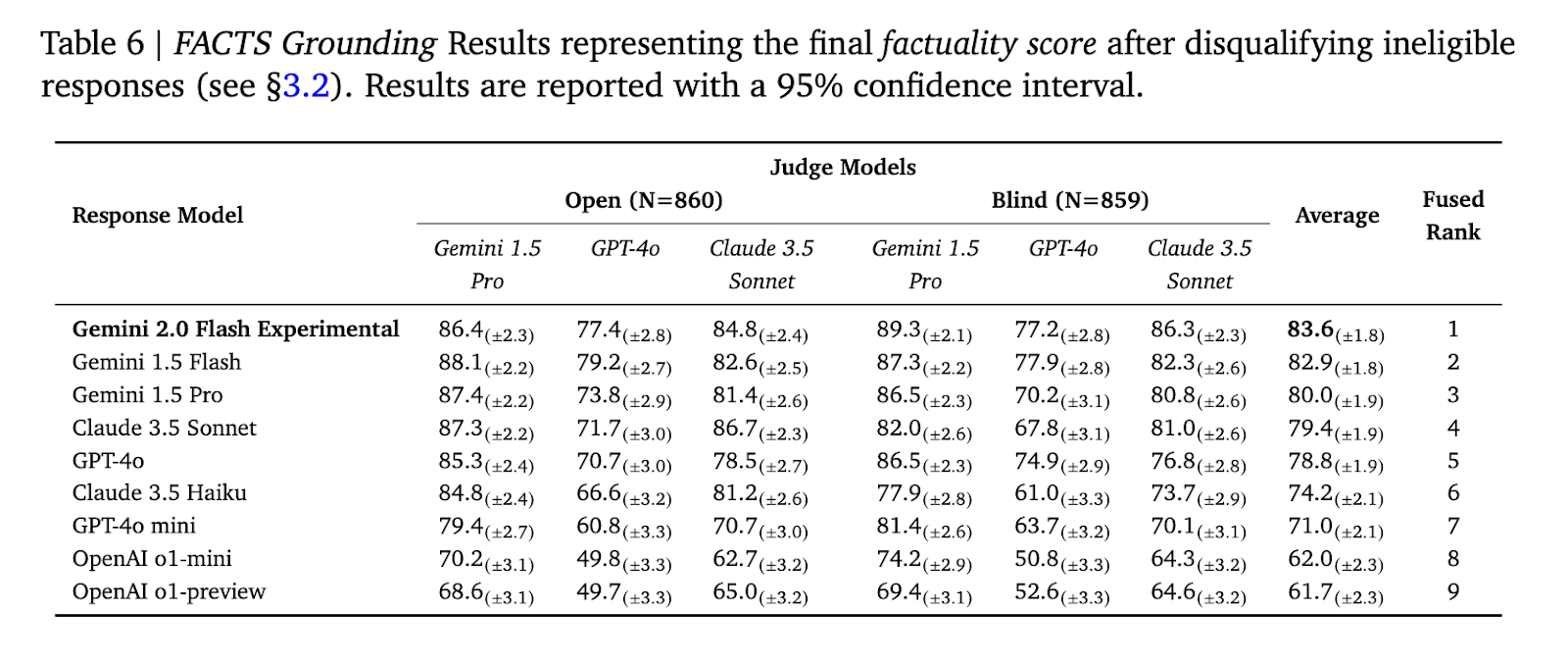
The FACTS Grounding Leaderboard revealed a variety of efficiency outcomes throughout the fashions examined, demonstrating the benchmark’s rigor in evaluating details. Among the many fashions evaluated, Gemini 1.5 Flash achieved a powerful factual rating of 85.8% on the general public dataset, adopted carefully by Gemini 1.5 Professional and GPT-4o with scores of 84.9% and 83.6% respectively . On the non-public dataset, Gemini 1.5 Professional outperformed others with a rating of 90.7%. Disqualification of ineligible solutions lowered scores by 1% to five%, highlighting the significance of sturdy filtering mechanisms. These outcomes spotlight the flexibility of benchmarks to distinguish efficiency and promote transparency in mannequin analysis.
The FACTS Grounding Leaderboard fills a vital hole in LLM evaluation by specializing in long-form response technology. Not like benchmarks that target slim use instances equivalent to short-form factuality or summarization, this benchmark addresses a broader vary of duties equivalent to fact-finding, doc evaluation, and data synthesis. By sustaining excessive requirements and actively updating leaderboards with new fashions, this initiative offers an vital device to enhance factual accuracy in LLM.
The analysis crew’s efforts spotlight the significance of a rigorous analysis framework to beat the challenges related to LLM-generated content material. The FACTS Grounding benchmark offers a scientific method to measuring details and fosters innovation within the improvement of extra dependable and correct AI techniques. This achievement units new requirements for evaluating LLM and stimulates additional advances in synthetic intelligence.
try of paper and technical details. All credit score for this analysis goes to the researchers of this undertaking. Do not forget to observe us Twitter and please be a part of us telegram channel and linkedin groupsHmm. Do not forget to affix us 60,000+ ML subreddits.
🚨 Trending: LG AI Analysis releases EXAONE 3.5: 3 open supply bilingual frontier AI degree fashions that ship unparalleled command following and lengthy context understanding for world management in distinctive generative AI….
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in supplies from the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic and is consistently researching purposes in areas equivalent to biomaterials and biomedicine. With a powerful background in supplies science, he explores new advances and creates alternatives to contribute.

{kind=link}