


How integrating BatchNorm in a normal Imaginative and prescient transformer structure results in quicker convergence and a extra steady community

Introduction
The Vision Transformer (ViT) is the primary purely self-attention-based structure for picture classification duties. Whereas ViTs do carry out higher than the CNN-based architectures, they require pre-training over very giant datasets. In an try to search for modifications of the ViT which can result in quicker coaching and inference — particularly within the context of medium-to-small enter knowledge sizes — I started exploring in a previous article ViT-type fashions which combine Batch Normalization (BatchNorm) of their structure. BatchNorm is thought to make a deep neural community converge quicker — a community with BatchNorm achieves increased accuracy in comparison with the base-line mannequin when skilled over the identical variety of epochs. This in flip hastens coaching. BatchNorm additionally acts as an environment friendly regularizer for the community, and permits a mannequin to be skilled with a better studying fee. The principle aim of this text is to research whether or not introducing BatchNorm can result in related results in a Imaginative and prescient Transformer.
For the sake of concreteness, I’ll give attention to a mannequin the place a BatchNorm layer is launched within the Feedforward Community (FFN) inside the transformer encoder of the ViT, and the LayerNorm previous the FFN is omitted. In every single place else within the transformer — together with the self-attention module — one continues to make use of LayerNorm. I’ll seek advice from this model of ViT as ViTBNFFN — Imaginative and prescient Transformer with BatchNorm within the Feedforward Community. I’ll practice and take a look at this mannequin on the MNIST dataset with picture augmentations and examine the High-1 accuracy of the mannequin with that of the usual ViT over various epochs. I’ll select an identical architectural configuration for the 2 fashions (i.e. an identical width, depth, patch measurement and so forth) in order that one can successfully isolate the impact of the BatchNorm layer.
Right here’s a fast abstract of the principle findings:
- For an inexpensive selection of hyperparameters (studying fee and batch measurement), ViTBNFFN does converge quicker than ViT, supplied the transformer depth (i.e variety of layers within the encoder) is sufficiently giant.
- As one will increase the training fee, ViTBNFFN seems to be extra steady than ViT, particularly at bigger depths.
I’ll open with a short dialogue on BatchNorm in a deep neural community, illustrating a number of the properties talked about above utilizing a concrete instance. I’ll then talk about intimately the structure of the mannequin ViTBNFFN. Lastly, I’ll take a deep dive into the numerical experiments that research the results of BatchNorm within the Imaginative and prescient Transformer.
The Dataset : MNIST with Picture Augmentation
Allow us to start by introducing the augmented MNIST dataset which I’ll use for all of the numerical experiments described on this article. The coaching and take a look at datasets are given by the perform get_datasets_mnist() as proven in Code Block 1.
The essential traces of code are given in traces 5–10, which listing the small print of the picture augmentations I’ll use. I’ve launched three totally different transformations:
- RandomRotation(levels=20) : A random rotation of the picture with the vary of rotation in levels being (-20, 20).
- RandomAffine(levels = 0, translate = (0.2, 0.2)) : A random affine transformation, the place the specification translate = (a, b) implies that the horizontal and vertical shifts are sampled randomly within the intervals [- image_width × a, image_width × a] and [-image_height × b, image_height × b] respectively. The levels=0 assertion deactivates rotation since now we have already taken it into consideration through random rotation. One may embody a scale transformation right here however we implement it utilizing the zoom out operation.
- RandomZoomOut(0,(2.0, 3.0), p=0.2) : A random zoom out transformation, which randomly samples the interval (2.0, 3.0) for a float r and outputs a picture with output_width = input_width × r and output_height = input_height × r. The float p is the chance that the zoom operation is carried out. This transformation is adopted by a Resize transformation in order that the ultimate picture is once more 28 × 28.
Batch Normalization in a Deep Neural Community
Allow us to give a fast overview of how BatchNorm improves the efficiency of a deep neural community. Suppose zᵃᵢ denotes the enter for a given layer of a deep neural community, the place a is the batch index which runs from a=1,…, Nₛ and that i is the function index operating from i=1,…, C. The BatchNorm operation then includes the next steps:
- For a given function index i, one first computes the imply and the variance over the batch of measurement Nₛ i.e.

2. One normalizes the enter utilizing the imply and variance computed above (with ϵ being a small optimistic quantity):

3. Lastly, one shifts and rescales the normalized enter for each function i:

the place there isn’t any summation over the index i, and the parameters (γᵢ, βᵢ) are trainable.
Think about a deep neural community for classifying the MNIST dataset. I’ll select a community consisting of three fully-connected hidden layers, with 100 activations every, the place every hidden layer is endowed with a sigmoid activation perform. The final hidden layer feeds right into a classification layer with 10 activations equivalent to the ten lessons of the MNIST dataset. The enter to this neural community is a Second-tensor of form b × 28² — the place b is the batch measurement and every 28 × 28 MNIST picture is reshaped right into a 28²-dimensional vector. On this case, the function index runs from i=1, …, 28².
This mannequin is much like the one mentioned within the unique BatchNorm paper — I’ll seek advice from this mannequin as DNN_d3. One could contemplate a model of this mannequin the place one provides a BatchNorm layer earlier than the sigmoid activation perform in every hidden layer. Allow us to name the resultant mannequin DNNBN_d3. The concept is to know how the introduction of the BatchNorm layer impacts the efficiency of the community.
To do that, allow us to now practice and take a look at the 2 fashions on the MNIST dataset described above, with CrossEntropyLoss() because the loss perform and the Adam optimizer, for 15 epochs. For a studying fee lr=0.01 and a coaching batch measurement of 100 (we select a take a look at batch measurement of 5000), the take a look at accuracy and the coaching loss for the fashions are given in Determine 1.

Evidently, the introduction of BatchNorm makes the community converge quicker — DNNBN achieves a better take a look at accuracy and decrease coaching loss. BatchNorm can subsequently pace up coaching.
What occurs if one will increase the training fee? Typically talking, a excessive studying fee would possibly result in gradients blowing up or vanishing, which might render the coaching unstable. Particularly, bigger studying charges will result in bigger layer parameters which in flip give bigger gradients throughout backpropagation. BatchNorm, nevertheless, ensures that the backpropagation by a layer is just not affected by a scaling transformation of the layer parameters (see Part 3.3 of this paper for extra particulars). This makes the community considerably extra proof against instabilities arising out of a excessive studying fee.
To show this explicitly for the fashions at hand, allow us to practice them at a a lot increased studying fee lr=0.1 — the take a look at accuracy and the coaching losses for the fashions on this case are given in Determine 2.

The excessive studying fee manifestly renders the DNN unstable. The mannequin with BatchNorm, nevertheless, is completely well-behaved! A extra instructive option to visualize this habits is to plot the accuracy curves for the 2 studying charges in a single graph, as proven in Determine 3.

Whereas the mannequin DNN_d3 stops coaching on the excessive studying fee, the affect on the efficiency of DNNBN_d3 is considerably milder. BatchNorm subsequently permits one to coach a mannequin at a better studying fee, offering yet one more option to pace up coaching.
The Mannequin ViTBNFFN : BatchNorm within the FeedForward Community
Allow us to start by briefly reviewing the structure of the usual Imaginative and prescient Transformer for picture classification duties, as proven within the schematic diagram of Determine 4. For extra particulars, I refer the reader to my earlier article or one of many many wonderful critiques of the subject in In the direction of Information Science.

Functionally, the structure of the Imaginative and prescient Transformer could also be divided into three predominant parts:
- Embedding layer : This layer maps a picture to a “sentence” — a sequence of tokens, the place every token is a vector of dimension dₑ (the embedding dimension). Given a picture of measurement h × w and c coloration channels, one first splits it into patches of measurement p × p and flattens them — this offers (h × w)/p² flattened patches (or tokens) of dimension dₚ = p² × c, that are then mapped to vectors of dimension dₑ utilizing a learnable linear transformation. To this sequence of tokens, one provides a learnable token — the CLS token — which is remoted on the finish for the classification activity. Schematically, one has:

Lastly, to this sequence of tokens, one provides a learnable tensor of the identical form which encodes the positional embedding data. The resultant sequence of tokens is fed into the transformer encoder. The enter to the encoder is subsequently a 3d tensor of form b × N × dₑ — the place b is the batch measurement, N is the variety of tokens together with the CLS token, and dₑ is the embedding dimension.
2. Transformer encoder : The transformer encoder maps the sequence of tokens to a different sequence of tokens with the identical quantity and the identical form. In different phrases, it maps the enter 3d tensor of form b × N × dₑ to a different 3d tensor of the identical form. The encoder can have L distinct layers (outlined because the depth of the transformer) the place every layer is made up of two sub-modules as proven in Determine 5— the multi-headed self-attention (MHSA) and the FeedForward Community (FFN).

The MHSA module implements a non-linear map on the 3d tensor of form b × N × dₑ to a 3d tensor of the identical form which is then fed into the FFN as proven in Determine 2. That is the place data from totally different tokens get combined through the self-attention map. The configuration of the MHSA module is fastened by the variety of heads nₕ and the top dimension dₕ.
The FFN is a deep neural community with two linear layers and a GELU activation within the center as proven in Determine 6.

The enter to this sub-module is a 3d tensor of of form b × N × dₑ. The linear layer on the left transforms it to a 3d tensor of form b × N × d_mlp, the place d_mlp is the hidden dimension of the community. Following the non-linear GELU activation, the tensor is mapped to a tensor of the unique form by the second layer.
3. MLP Head : The MLP Head is a fully-connected community that maps the output of the transformer encoder — 3d tensor of form b × N × dₑ — to a Second tensor of form b × d_num the place d_num is the variety of lessons within the given picture classification activity. That is executed by first isolating the CLS token from the enter tensor after which placing it by the related community.
The mannequin ViTBNFFN has the identical structure as described above with two variations. Firstly, one introduces a BatchNorm Layer within the FFN of the encoder between the primary linear layer and the GELU activation as proven in Determine 7. Secondly, one removes the LayerNorm previous the FFN in the usual ViT encoder (see Determine 5 above).

For the reason that linear transformation acts on the third dimension of the enter tensor of form b × N × dₑ , we must always determine dₑ because the function dimension of the BatchNorm. The PyTorch implementation of the brand new feedforward community is given in Code Block 2.
The built-in BatchNorm class in PyTorch all the time takes the primary index of a tensor because the batch index and the second index because the function index. Due to this fact, one wants to remodel our 3d tensor with form b × N × dₑ to a tensor of form b × dₑ × N earlier than making use of BatchNorm, and remodeling it again to b × N × dₑ afterwards. As well as, I’ve used the Second BatchNorm class (since it’s barely quicker than the 1d BatchNorm). This requires selling the 3d tensor to a 4d tensor of form b × dₑ × N × 1 (line 16) and remodeling it again (line 18) to a 3d tensor of form b × N × dₑ. One can use the 1d BatchNorm class with out altering any of the outcomes offered within the part.
The Experiment
With a set studying fee and batch measurement, I’ll practice and take a look at the 2 fashions — ViT and ViTBNFFN — on the augmented MNIST dataset for 10 epochs and examine the High-1 accuracies on the validation dataset. Since we’re fascinated by understanding the results of BatchNorm, we must examine the 2 fashions with an identical configurations. The experiment can be repeated at totally different depths of the transformer encoder preserving the remainder of the mannequin configuration unchanged. The precise configuration for the 2 fashions that I take advantage of on this experiment is given as follows :
- Embedding layer: An MNIST picture is a grey-scale picture of measurement 28× 28. The patch measurement is p= 7, which means that the variety of tokens is 16 + 1 =17 together with the CLS token. The embedding dimension is dₑ = 64.
- Transformer encoder: The MHSA submodule has nₕ = 8 heads with head dimension dₕ=64. The hidden dimension of the FFN is d_mlp = 128. The depth of the encoder would be the solely variable parameter on this structure.
- MLP head: The MLP head will merely include a linear layer.
The coaching and testing batch sizes can be fastened at 100 and 5000 respectively for all of the epochs, with CrossEntropyLoss() because the loss perform and Adam optimizer. The dropout parameters are set to zero in each the embedding layer in addition to the encoder. I’ve used the NVIDIA L4 Tensor Core GPU accessible at Google Colab for all of the runs, which have been recorded utilizing the monitoring function of MLFlow.
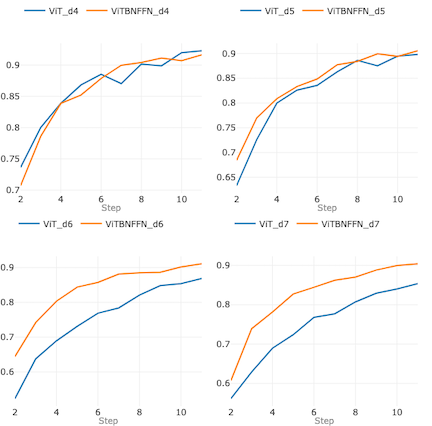
Allow us to begin by coaching and testing the fashions on the studying fee lr= 0.003. Determine 8 under summarizes the 4 graphs which plot the accuracy curves of the 2 fashions at depths d=4, 5, 6 and seven respectively. In these graphs, the notation ViT_dn (ViTBNFFN_dn) denotes ViT (ViTBNFFN) with depth of the encoder d=n and the remainder of the mannequin configuration being the identical as specified above.

For d= 4 and d= 5 (the highest row of graphs), the accuracies of the 2 fashions are comparable — for d=4 (prime left) ViT does considerably higher, whereas for d=5 (prime proper) ViTBNFFN surpasses ViT marginally. For d < 4, the accuracies stay comparable. Nonetheless, for d=6 and d=7 (the underside row of graphs), ViTBNFFN does considerably higher than ViT. One can test that this qualitative function stays the identical for any depth d ≥ 6.
Allow us to repeat the experiment at a barely increased studying fee lr = 0.005. The accuracy curves of the 2 fashions at depths d=1, 2, 3 and 4 respectively are summarized in Determine 9.

For d= 1 and d= 2 (the highest row of graphs), the accuracies of the 2 fashions are comparable — for d=1 ViT does considerably higher, whereas for d=2 they’re nearly indistinguishable. For d=3 (backside left), ViTBNFFN achieves a barely increased accuracy than ViT. For d=4 (backside proper), nevertheless, ViTBNFFN does considerably higher than ViT and this qualitative function stays the identical for any depth d ≥ 4.
Due to this fact, for an inexpensive selection of studying fee and batch measurement, ViTBNFFN converges considerably quicker than ViT past a crucial depth of the transformer encoder. For the vary of hyperparameters I contemplate, evidently this crucial depth will get smaller with rising studying fee at a set batch measurement.
For the deep neural community instance, we noticed that the affect of a excessive studying fee is considerably milder on the community with BatchNorm. Is there one thing analogous that occurs for a Imaginative and prescient Transformer? That is addressed in Determine 10. Right here every graph plots the accuracy curves of a given mannequin at a given depth for 2 totally different studying charges lr=0.003 and lr=0.005. The primary column of graphs corresponds to ViT for d=2, 3 and 4 (prime to backside) whereas the second column corresponds to ViTBNFFN for a similar depths.

Think about d=2 — given by the highest row of graphs — ViT and ViTBNFFN are comparably impacted as one will increase the training fee. For d = 3 — given by the second row of graphs — the distinction is important. ViT achieves a a lot decrease accuracy on the increased studying fee — the accuracy drops from about 91% to round 78% on the finish of epoch 10. Alternatively, for ViTBNFFN, the accuracy on the finish of epoch 10 drops from about 92% to about 90%. This qualitative function stays the identical at increased depths too — see the underside row of graphs which corresponds to d=4. Due to this fact, the affect of the upper studying fee on ViTBNFFN appears considerably milder for sufficiently giant depth of the transformer encoder.
Conclusion
On this article, I’ve studied the results of introducing a BatchNorm layer contained in the FeedForward Community of the transformer encoder in a Imaginative and prescient Transformer. Evaluating the fashions on an augmented MNIST dataset, there are two predominant classes that one could draw. Firstly, for a transformer of adequate depth and for an inexpensive selection of hyperparameters, the mannequin with BatchNorm achieves considerably increased accuracy in comparison with the usual ViT. This quicker convergence can vastly pace up coaching. Secondly, much like our instinct for deep neural networks, the Imaginative and prescient Transformer with BatchNorm is extra resilient to a better studying fee, if the encoder is sufficiently deep.

{kind=link}