


The AWS Generative AI Innovation Middle (GenAIIC) is a staff of AWS science and technique specialists who’ve deep data of generative AI. They assist AWS clients jumpstart their generative AI journey by constructing proofs of idea that use generative AI to convey enterprise worth. Because the inception of AWS GenAIIC in Might 2023, now we have witnessed excessive buyer demand for chatbots that may extract data and generate insights from large and sometimes heterogeneous data bases. Such use circumstances, which increase a big language mannequin’s (LLM) data with exterior information sources, are often called Retrieval-Augmented Era (RAG).
This two-part collection shares the insights gained by AWS GenAIIC from direct expertise constructing RAG options throughout a variety of industries. You need to use this as a sensible information to constructing higher RAG options.
On this first put up, we deal with the fundamentals of RAG structure and the way to optimize text-only RAG. The second put up outlines the way to work with a number of information codecs comparable to structured information (tables, databases) and pictures.
Anatomy of RAG
RAG is an environment friendly solution to present an FM with further data by utilizing exterior information sources and is depicted within the following diagram:
- Retrieval: Based mostly on a person’s query (1), related data is retrieved from a data base (2) (for instance, an OpenSearch index).
- Augmentation: The retrieved data is added to the FM immediate (3.a) to enhance its data, together with the person question (3.b).
- Era: The FM generates a solution (4) by utilizing the data supplied within the immediate.
The next is a basic diagram of a RAG workflow. From left to proper are the retrieval, the augmentation, and the technology. In follow, the data base is commonly a vector retailer.
A deeper dive within the retriever
In a RAG structure, the FM will base its reply on the data supplied by the retriever. Due to this fact, a RAG is simply pretty much as good as its retriever, and lots of the suggestions that we share in our sensible information are about the way to optimize the retriever. However what’s a retriever precisely? Broadly talking, a retriever is a module that takes a question as enter and outputs related paperwork from a number of data sources related to that question.
Doc ingestion
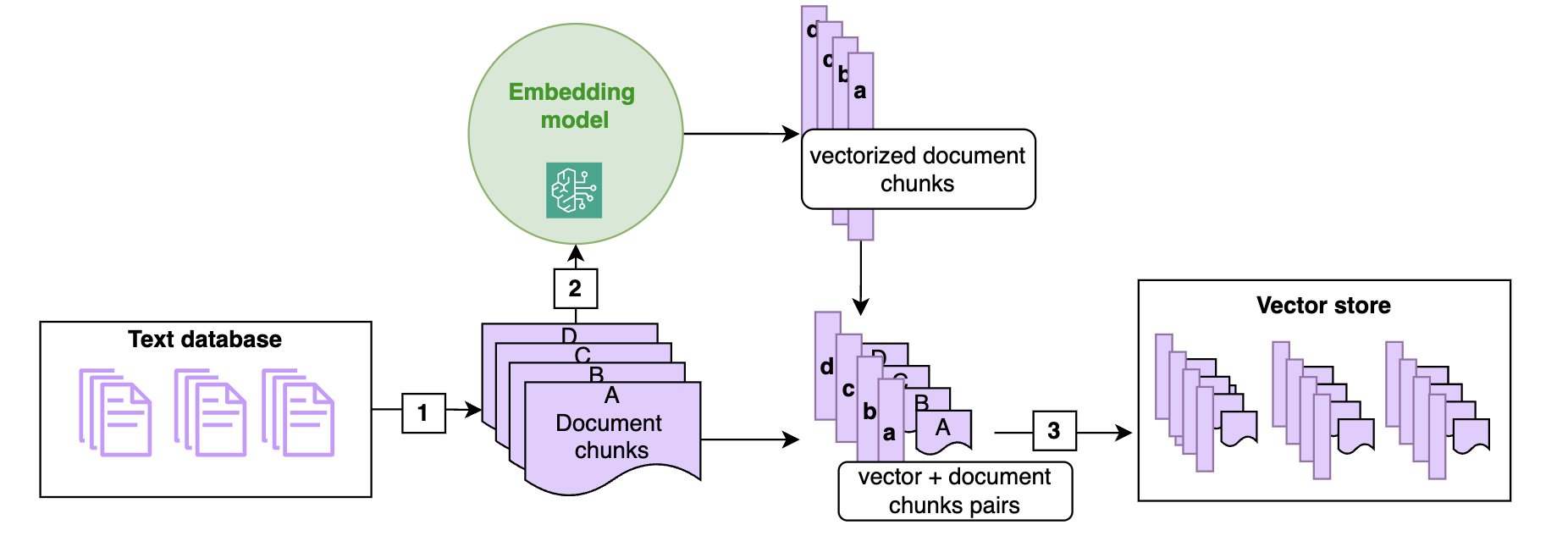
In a RAG structure, paperwork are sometimes saved in a vector retailer. As proven within the following diagram, vector shops are populated by chunking the paperwork into manageable items (1) (if a doc is brief sufficient, chunking won’t be required) and remodeling every chunk of the doc right into a high-dimensional vector utilizing a vector embedding (2), such because the Amazon Titan embeddings mannequin. These embeddings have the attribute that two chunks of texts which might be semantically shut have vector representations which might be additionally shut in that embedding (within the sense of the cosine or Euclidean distance).
The next diagram illustrates the ingestion of textual content paperwork within the vector retailer utilizing an embedding mannequin. Notice that the vectors are saved alongside the corresponding textual content chunk (3), in order that at retrieval time, whenever you determine the chunks closest to the question, you may return the textual content chunk to be handed to the FM immediate.
Semantic search
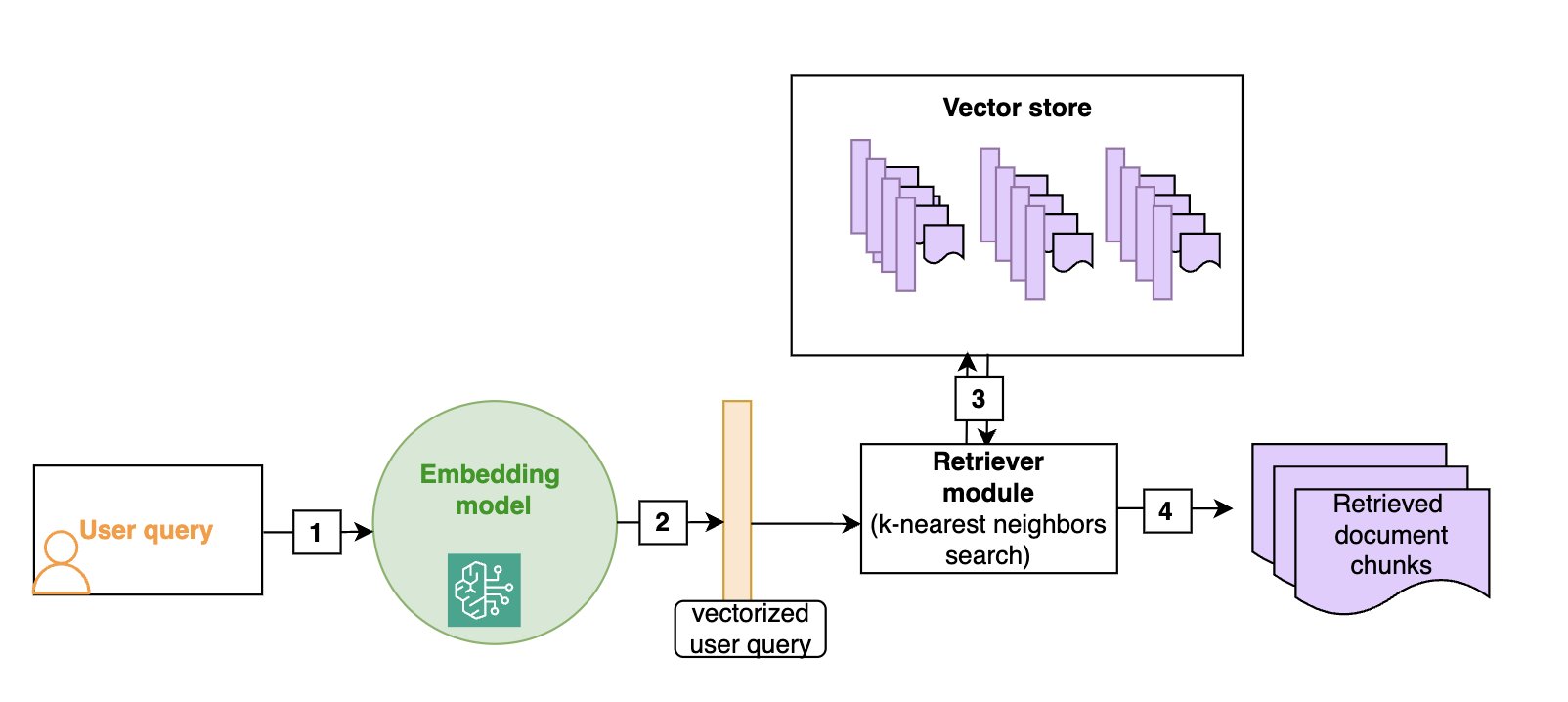
Vector shops permit for environment friendly semantic search: as proven within the following diagram, given a person question (1), we vectorize it (2) (utilizing the identical embedding because the one which was used to construct the vector retailer) after which search for the closest vectors within the vector retailer (3), which is able to correspond to the doc chunks which might be semantically closest to the preliminary question (4). Though vector shops and semantic search have turn out to be the default in RAG architectures, extra conventional keyword-based search continues to be worthwhile, particularly when looking for domain-specific phrases (comparable to technical jargon) or names. Hybrid search is a manner to make use of each semantic search and key phrases to rank a doc, and we’ll give extra particulars on this system within the part on superior RAG methods.
The next diagram illustrates the retrieval of textual content paperwork which might be semantically near the person question. You could use the identical embedding mannequin at ingestion time and at search time.
Implementation on AWS
A RAG chatbot will be arrange in a matter of minutes utilizing Amazon Bedrock Information Bases. The data base will be linked to an Amazon Easy Storage Service (Amazon S3) bucket and can robotically chunk and index the paperwork it accommodates in an OpenSearch index, which is able to act because the vector retailer. The retrieve_and_generate API does each the retrieval and a name to an FM (Amazon Titan or Anthropic’s Claude household of fashions on Amazon Bedrock), for a completely managed resolution. The retrieve API solely implements the retrieval part and permits for a extra customized method downstream, comparable to doc put up processing earlier than calling the FM individually.
On this weblog put up, we’ll present suggestions and code to optimize a completely customized RAG resolution with the next elements:
- An OpenSearch Serverless vector search assortment because the vector retailer
- Customized chunking and ingestion features to ingest the paperwork within the OpenSearch index
- A customized retrieval perform that takes a person question as an enter and outputs the related paperwork from the OpenSearch index
- FM calls to your mannequin of alternative on Amazon Bedrock to generate the ultimate reply.
On this put up, we deal with a customized resolution to assist readers perceive the inside workings of RAG. Many of the suggestions we offer will be tailored to work with Amazon Bedrock Information Bases, and we’ll level this out within the related sections.
Overview of RAG use circumstances
Whereas working with clients on their generative AI journey, we encountered quite a lot of use circumstances that match throughout the RAG paradigm. In conventional RAG use circumstances, the chatbot depends on a database of textual content paperwork (.doc, .pdf, or .txt). Partially 2 of this put up, we’ll focus on the way to prolong this functionality to photographs and structured information. For now, we’ll deal with a typical RAG workflow: the enter is a person query, and the output is the reply to that query, derived from the related textual content chunks or paperwork retrieved from the database. Use circumstances embrace the next:
- Customer support– This may embrace the next:
- Inside– Dwell brokers use an inside chatbot to assist them reply buyer questions.
- Exterior– Prospects instantly chat with a generative AI chatbot.
- Hybrid– The mannequin generates sensible replies for reside brokers that they’ll edit earlier than sending to clients.
- Worker coaching and sources– On this use case, chatbots can use worker coaching manuals, HR sources, and IT service paperwork to assist staff onboard sooner or discover the data they should troubleshoot inside points.
- Industrial upkeep– Upkeep manuals for advanced machines can have a number of hundred pages. Constructing a RAG resolution round these manuals helps upkeep technicians discover related data sooner. Notice that upkeep manuals usually have pictures and schemas, which might put them in a multimodal bucket.
- Product data search– Area specialists must determine related merchandise for a given use case, or conversely discover the best technical details about a given product.
- Retrieving and summarizing monetary information– Analysts want probably the most up-to-date data on markets and the financial system and depend on massive databases of reports or commentary articles. A RAG resolution is a solution to effectively retrieve and summarize the related data on a given subject.
Within the following sections, we’ll give suggestions that you need to use to optimize every side of the RAG pipeline (ingestion, retrieval, and reply technology) relying on the underlying use case and information format. To confirm that the modifications enhance the answer, you first want to have the ability to assess the efficiency of the RAG resolution.
Evaluating a RAG resolution
Opposite to conventional machine studying (ML) fashions, for which analysis metrics are effectively outlined and simple to compute, evaluating a RAG framework continues to be an open downside. First, accumulating floor reality (data recognized to be right) for the retrieval part and the technology part is time consuming and requires human intervention. Secondly, even with a number of question-and-answer pairs accessible, it’s tough to robotically consider if the RAG reply is shut sufficient to the human reply.
In our expertise, when a RAG system performs poorly, we discovered the retrieval half to nearly all the time be the wrongdoer. Massive pre-trained fashions comparable to Anthropic’s Claude mannequin will generate high-quality solutions if supplied with the best data, and we discover two predominant failure modes:
- The related data isn’t current within the retrieved paperwork: On this case, the FM can attempt to make up a solution or use its personal data to reply. Including guardrails in opposition to such habits is important.
- Related data is buried inside an extreme quantity of irrelevant information: When the scope of the retriever is simply too broad, the FM can get confused and begin mixing up a number of information sources, leading to a improper reply. Extra superior fashions comparable to Anthropic’s Claude Sonnet 3.5 and Opus are reported to be extra sturdy in opposition to such habits, however that is nonetheless a threat to pay attention to.
To judge the standard of the retriever, you need to use the next conventional retrieval metrics:
- Prime-k accuracy: Measures whether or not at the very least one related doc is discovered throughout the prime okay retrieved paperwork.
- Imply Reciprocal Rank (MRR)– This metric considers the rating of the retrieved paperwork. It’s calculated as the typical of the reciprocal ranks (RR) for every question. The RR is the inverse of the rank place of the primary related doc. For instance, if the primary related doc is in third place, the RR is 1/3. A better MRR signifies that the retriever can rank probably the most related paperwork larger.
- Recall– This metric measures the flexibility of the retriever to retrieve related paperwork from the corpus. It’s calculated because the variety of related paperwork which might be efficiently retrieved over the overall variety of related paperwork. Larger recall signifies that the retriever can discover a lot of the related data.
- Precision– This metric measures the flexibility of the retriever to retrieve solely related paperwork and keep away from irrelevant ones. It’s calculated by the variety of related paperwork efficiently retrieved over the overall variety of paperwork retrieved. Larger precision signifies that the retriever isn’t retrieving too many irrelevant paperwork.
Notice that if the paperwork are chunked, the metrics have to be computed on the chunk degree. This implies the bottom reality to judge a retriever is pairs of query and record of related doc chunks. In lots of circumstances, there is just one chunk that accommodates the reply to the query, so the bottom reality turns into query and related doc chunk.
To judge the standard of the generated response, two predominant choices are:
- Analysis by material specialists: this offers the very best reliability when it comes to analysis however can’t scale to a lot of questions and slows down iterations on the RAG resolution.
- Analysis by FM (additionally referred to as LLM-as-a-judge):
- With a human-created start line: Present the FM with a set of floor reality question-and-answer pairs and ask the FM to judge the standard of the generated reply by evaluating it to the bottom reality one.
- With an FM-generated floor reality: Use an FM to generate question-and-answer pairs for given chunks, after which use this as a floor reality, earlier than resorting to an FM to check RAG solutions to that floor reality.
We suggest that you simply use an FM for evaluations to iterate sooner on bettering the RAG resolution, however to make use of subject-matter specialists (or at the very least human analysis) to supply a ultimate evaluation of the generated solutions earlier than deploying the answer.
A rising variety of libraries supply automated analysis frameworks that depend on further FMs to create a floor reality and consider the relevance of the retrieved paperwork in addition to the standard of the response:
- Ragas– This framework affords FM-based metrics beforehand described, comparable to context recall, context precision, reply faithfulness, and reply relevancy. It must be tailored to Anthropic’s Claude fashions due to its heavy dependence on particular prompts.
- LlamaIndex– This framework offers a number of modules to independently consider the retrieval and technology elements of a RAG system. It additionally integrates with different instruments comparable to Ragas and DeepEval. It accommodates modules to create floor reality (query-and-context pairs and question-and-answer pairs) utilizing an FM, which alleviates using time-consuming human assortment of floor reality.
- RefChecker– That is an Amazon Science library centered on fine-grained hallucination detection.
Troubleshooting RAG
Analysis metrics give an general image of the efficiency of retrieval and technology, however they don’t assist diagnose points. Diving deeper into poor responses might help you perceive what’s inflicting them and what you are able to do to alleviate the problem. You may diagnose the problem by taking a look at analysis metrics and in addition by having a human evaluator take a more in-depth have a look at each the LLM reply and the retrieved paperwork.
The next is a quick overview of points and potential fixes. We are going to describe every of the methods in additional element, together with real-world use circumstances and code examples, within the subsequent part.
- The related chunk wasn’t retrieved (retriever has low prime okay accuracy and low recall or noticed by human analysis):
- Strive growing the variety of paperwork retrieved by the closest neighbor search and re-ranking the outcomes to chop again on the variety of chunks after retrieval.
- Strive hybrid search. Utilizing key phrases together with semantic search (often called hybrid search) may assist, particularly if the queries include names or domain-specific jargon.
- Strive question rewriting. Having an FM detect the intent or rewrite the question might help create a question that’s higher fitted to the retriever. As an illustration, a person question comparable to “What data do you might have within the data base in regards to the financial outlook in China?” accommodates quite a lot of context that isn’t related to the search and can be extra environment friendly if rewritten as “financial outlook in China” for search functions.
- Too many chunks have been retrieved (retriever has low precision or noticed by human analysis):
- Strive utilizing key phrase matching to limit the search outcomes. For instance, for those who’re on the lookout for details about a selected entity or property in your data base, solely retrieve paperwork that explicitly point out them.
- Strive metadata filtering in your OpenSearch index. For instance, for those who’re on the lookout for data in information articles, attempt utilizing the date area to filter solely the latest outcomes.
- Strive utilizing question rewriting to get the best metadata filtering. This superior approach makes use of the FM to rewrite the person question as a extra structured question, permitting you to benefit from OpenSearch filters. For instance, for those who’re on the lookout for the specs of a selected product in your database, the FM can extract the product title from the question, and you may then use the product title area to filter out the product title.
- Strive utilizing reranking to chop down on the variety of chunks handed to the FM.
- A related chunk was retrieved, however it’s lacking some context (can solely be assessed by human analysis):
- Strive altering the chunking technique. Remember that small chunks are good for exact questions, whereas massive chunks are higher for questions that require a broad context:
- Strive growing the chunk measurement and overlap as a primary step.
- Strive utilizing section-based chunking. In case you have structured paperwork, use sections delimiters to chop your paperwork into chunks to have extra coherent chunks. Bear in mind that you simply may lose a few of the extra fine-grained context in case your chunks are bigger.
- Strive small-to-large retrievers. If you wish to preserve the fine-grained particulars of small chunks however ensure you retrieve all of the related context, small-to-large retrievers will retrieve your chunk together with the earlier and subsequent ones.
- Strive altering the chunking technique. Remember that small chunks are good for exact questions, whereas massive chunks are higher for questions that require a broad context:
- If not one of the above assist:
- Contemplate coaching a customized embedding.
- The retriever isn’t at fault, the issue is with FM technology (evaluated by a human or LLM):
- Strive immediate engineering to mitigate hallucinations.
- Strive prompting the FM to make use of quotes in its solutions, to permit for handbook reality checking.
- Strive utilizing one other FM to judge or right the reply.
A sensible information to bettering the retriever
Notice that not all of the methods that observe have to be applied collectively to optimize your retriever—some may even have reverse results. Use the previous troubleshooting information to get a shortlist of what may work, then have a look at the examples within the corresponding sections that observe to evaluate if the strategy will be useful to your retriever.
Hybrid search
Instance use case: A big producer constructed a RAG chatbot to retrieve product specs. These paperwork include technical phrases and product names. Contemplate the next instance queries:
The queries are equal and have to be answered with the identical doc. The key phrase part will just remember to’re boosting paperwork mentioning the title of the product, XYZ whereas the semantic part will make it possible for paperwork containing viscosity get a excessive rating, even when the question accommodates the phrase viscous.
Combining vector search with key phrase search can successfully deal with domain-specific phrases, abbreviations, and product names that embedding fashions may wrestle with. Virtually, this may be achieved in OpenSearch by combining a k-nearest neighbors (k-NN) question with key phrase matching. The weights for the semantic search in comparison with key phrase search will be adjusted. See the next instance code:
Amazon Bedrock Information Bases additionally helps hybrid search, however you may’t modify the weights for semantic in comparison with key phrase search.
Including metadata data to textual content chunks
Instance use case: Utilizing the identical instance of a RAG chatbot for product specs, contemplate product specs which might be a number of pages lengthy and the place the product title is simply current within the header of the doc. When ingesting the doc into the data base, it’s chunked into smaller items for the embedding mannequin, and the product title solely seems within the first chunk, which accommodates the header. See the next instance:
Beneath is the FM response to the query "What are the strengths of participant A?":
 Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Middle, the place she helps clients sort out vital enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.
Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Middle, the place she helps clients sort out vital enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.

{kind=link}