



So Previous articlewe have been launched Structured Output Powered by OpenAI. ChatCompletions API basic availability launch (Version 1.40.0), the structured output was utilized to dozens of use circumstances, spawning quite a few threads. OpenAI Forum.
The aim of this text is to supply a deeper understanding, clear up some misconceptions, and supply tips about tips on how to apply it in the very best method in several eventualities.
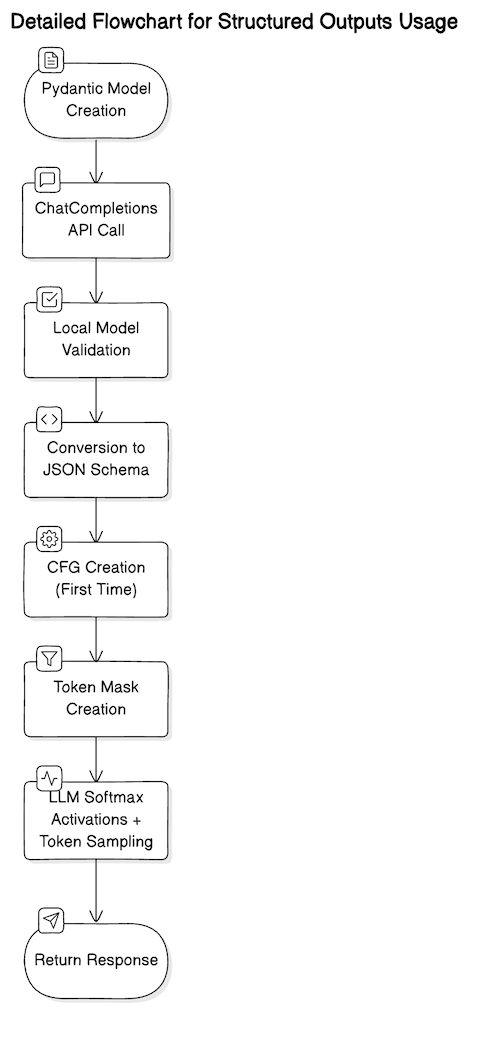
Structured output is a method to drive the output of an LLM right into a predefined schema, normally a JSON schema. That is carried out by Context-Free Grammar (CFG)It’s used within the token sampling step together with the beforehand generated token to tell whether or not the following token is legitimate. Regular Expressions For token technology.
The OpenAI API implementation truly tracks a restricted subset of JSON Schema performance. A extra basic structured output answer can be to overviewIt’s doable to make use of a barely bigger subset of the JSON schema and even outline a very customized non-JSON schema, so long as you might have entry to the OpenAI API mannequin. This text assumes the OpenAI API implementation.
Based on JSON Schema Core Specification, “JSON Schema declares what a JSON doc seems to be like, tips on how to extract data from it, and tips on how to work together with it.”JSON Schema defines six primary sorts: null, boolean, object, array, quantity, and string. It additionally defines sure key phrases, annotations, and sure behaviors. For instance, within the schema: array Whenever you add an annotation minItems Change into 5 .
Pydantic is a Python library that implements the JSON Schema specification. We use Pydantic to construct strong, maintainable software program in Python. Python is a dynamically typed language, so information scientists do not essentially must Variable sorts —These are sometimes Suggestion In code, for instance, fruits are specified as follows:
fruit = dict(
title="apple",
colour="pink",
weight=4.2
)
…Then again, a operate declaration that returns the “fruit” from some information would seemingly seem like this:
def extract_fruit(s):
...
return fruit
Then again, Pydantic makes use of correctly annotated variables and Enter traceYour code will probably be extra readable, maintainable, and general extra strong.
class Fruit(BaseModel):
title: str
colour: Literal['red', 'green']
weight: Annotated[float, Gt(0)]def extract_fruit(s: str) -> Fruit:
...
return fruit
OpenAI in motion Highly recommended Utilizing Pydantic to specify your schema is preferable versus specifying a “uncooked” JSON Schema instantly. There are a number of causes for this. First, Pydantic is assured to evolve to the JSON Schema specification, saving you the additional step of pre-validation. Second, for giant schemas, it leads to much less redundancy, permitting you to jot down cleaner, quicker code. Lastly, openai Python packages truly do the housekeeping corresponding to configuration additionalProperties To False Then again, if you wish to outline your schema “manually” utilizing JSON: Manual setuprun it for each object in your schema (in any other case you may get some fairly nasty API errors).
As talked about earlier, the ChatCompletions API supplies a restricted subset of the complete JSON Schema specification. Keywords not yet supportedlike minimal and most As for the numbers minItems and maxItems For arrays — a really helpful annotation for decreasing hallucinations and limiting output measurement.
Sure formatting options are additionally unavailable. For instance, passing the next Pydantic schema will lead to an API error: response_format Chat Complement:
class NewsArticle(BaseModel):
headline: str
subheading: str
authors: Checklist[str]
date_published: datetime = Discipline(None, description="Date when article was revealed. Use ISO 8601 date format.")
It’s going to fail openai The package deal doesn’t have any formatting datetime So as an alternative date_published As str Carry out format validation (e.g. ISO 8601 compliance) after the actual fact.
Different main limitations embrace:
- Hallucinations can nonetheless happen For instance, if you wish to extract the product ID, you’d outline it within the response schema as follows:
product_ids: Checklist[str]; Whereas the output is assured to provide an inventory of strings (product IDs), the strings themselves could also be hallucinated, so on this use case you could must validate the output in opposition to a predefined set of product IDs. - The output is restricted in
4096Token or the smaller quantity you setmax_tokensAs a result of it is a parameter, the schema will probably be adopted precisely, but when the output is simply too massive it is going to be truncated and produce invalid JSON, which is very annoying for very massive information. Batch API work! - Deeply nested schemas with many object properties There could also be an API error. Depth and width limits It is determined by your schema, however generally it is best to stay to a flat and easy construction – that is vital not solely to keep away from API errors, but additionally to squeeze as a lot efficiency as doable out of the LLM (which typically has issue coping with deeply nested constructions).
- Extremely dynamic or arbitrary schemas usually are not doable – nonetheless Recursion is supportedyou can not create extremely dynamic schemas, corresponding to lists of arbitrary key-value objects.
[{"key1": "val1"}, {"key2": "val2"}, ..., {"keyN": "valN"}]On this case, the hot button is Should In such eventualities, the most suitable choice is to not use structured output in any respect, as an alternative choosing commonplace JSON mode and offering directions concerning the output construction throughout the system prompts.
With all this in thoughts, let us take a look at some ideas and methods for enhancing efficiency when utilizing structured output, together with some use circumstances.
Use non-obligatory parameters for flexibility
For instance you are constructing an internet scraping software whose aim is to gather particular elements from internet pages. For every internet web page, you present a person immediate with the uncooked HTML and a system immediate with particular scraping directions, and outline the next Pydantic mannequin:
class Webpage(BaseModel):
title: str
paragraphs: Elective[List[str]] = Discipline(None, description="Textual content contents enclosed inside <p></p> tags.")
hyperlinks: Elective[List[str]] = Discipline(None, description="URLs specified by `href` subject inside <a></a> tags.")
photos: Elective[List[str]] = Discipline(None, description="URLs specified by the `src` subject throughout the <img></img> tags.")
Then, name the API as follows:
response = consumer.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": "You are to parse HTML and return the parsed page components."
},
{
"role": "user",
"content": """
<html>
<title>Structured Outputs Demo</title>
<body>
<img src="test.gif"></image>
<p>Hello world!</p>
</body>
</html>
"""
}
],
response_format=Webpage
)
…I acquired the next response:
{
'photos': ['test.gif'],
'hyperlinks': None,
'paragraphs': ['Hello world!'],
'title': 'Structured Outputs Demo'
}
Response schema supplied to APIs with structured output Should Returns all specified fields, however permits for “emulating” non-obligatory fields to permit higher flexibility. Elective Sort annotations may also be used: Union[List[str], None] — are syntactically similar. In each circumstances, they’re translated to: anyOf The key phrases observe the JSON Schema specification. Within the above instance, <a></a> If the tag doesn’t exist on the internet web page, the API hyperlinks It’s set within the subject None .
Utilizing enumerations to cut back hallucinations
As talked about earlier than, regardless that the LLM is assured to observe the response schema supplied, it could nonetheless have hallucinatory interpretations of the particular values. Recent Publications We discovered that forcing a hard and fast schema on the output truly prompted LLMs to hallucinate and scale back their reasoning talents.
One method to overcome these limitations is to leverage enumerations wherever doable. Enumerations restrict the output to a really particular set of tokens, zeroing out all different prospects. For instance, say you are attempting to rerank outcomes for the similarity of 1 product to a different. Chosen merchandise Consists of description And distinctive product_id and Prime 5 Merchandise These have been obtained utilizing a vector similarity search (e.g. utilizing the cosine distance metric). Every of those prime 5 merchandise additionally incorporates a corresponding textual content description and a singular ID. Within the response I simply need to get the rerankings 1-5 as an inventory (e.g.: [1, 4, 3, 5, 2] ), you’re going to get a re-ranked listing of product ID strings, which can be illusory or invalid. Configure your Pydantic mannequin as follows…
class Rank(IntEnum):
RANK_1 = 1
RANK_2 = 2
RANK_3 = 3
RANK_4 = 4
RANK_5 = 5class RerankingResult(BaseModel):
ordered_ranking: Checklist[Rank] = Discipline(description="Supplies ordered rating 1-5.")
…and execute the API as follows:
response = consumer.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """
You are to rank the similarity of the candidate products against the target product.
Ranking should be orderly, from the most similar, to the least similar.
"""
},
{
"role": "user",
"content": """
## Target Product
Product ID: X56HHGHH
Product Description: 80" Samsung LED TV## Candidate Products
Product ID: 125GHJJJGH
Product Description: NVIDIA RTX 4060 GPU
Product ID: 76876876GHJ
Product Description: Sony Walkman
Product ID: 433FGHHGG
Product Description: Sony LED TV 56"
Product ID: 777888887888
Product Description: Blueray Sony Player
Product ID: JGHHJGJ56
Product Description: BenQ PC Monitor 37" 4K UHD
"""
}
],
response_format=RerankingResult
)
The top result’s merely this:
{'ordered_ranking': [3, 5, 1, 4, 2]}
So, LLM in contrast Sony’s LED TV (merchandise quantity “3” on the listing) and BenQ’s PC monitor (merchandise quantity “5”) as the 2 most related product candidates, i.e. ordered_ranking listing!
On this put up, we did a deep dive into structured output. We launched JSON Schema and Pydantic fashions, and linked these to OpenAI’s ChatCompletions API. We walked by way of some examples and confirmed a number of the greatest methods to resolve them utilizing structured output. To summarize the important thing factors:
- Structured output supported by the OpenAI API and different third-party frameworks is A subset of the JSON Schema specification — Figuring out extra about capabilities and limitations helps you make good design selections.
- use Pidantic Alternatively, we extremely advocate utilizing the same framework that carefully tracks the JSON Schema specification, which can allow you to jot down legitimate and clear code.
- Hallucinations are nonetheless anticipated to happen, however there are numerous methods to cut back them just by selecting response schema designs. For instance: Utilizing Enumerations The place acceptable.
Concerning the Writer
Armin Katowicz Serves as Secretary of the Board of Administrators Stockholm AIVice President and Senior ML/AI Engineer. EQT GroupHe has 18 years of engineering expertise throughout Australia, Southeast Asia, Europe and the US, and holds quite a few patents and main peer-reviewed AI publications.

{kind=link}