



Buyer knowledge is commonly saved as data in buyer relationship administration methods (CRM). Information manually entered into such methods by a number of customers over time results in duplicate, partial, or ambiguous knowledge, that means there isn’t any single supply of fact for patrons, contacts, accounts, and so forth. And not using a distinctive mapping between CRM data and goal prospects, downstream enterprise processes grow to be more and more complicated and unnatural. Present strategies for locating and deduplication of data use a standard pure language processing method known as entity matching. Nevertheless, utilizing the newest advances in large-scale language fashions and generative AI, duplicate document identification and remediation could be considerably improved. On a well-liked benchmark dataset, we present that the accuracy of information deduplication charges will increase from 30 p.c utilizing NLP strategies to virtually 60 p.c utilizing our proposed technique.
I hope that by explaining this method right here, others will discover it helpful and put it to use for their very own deduplication wants. This may be helpful not just for buyer knowledge, however for different eventualities the place you need to determine duplicate data. I’ve written and printed a analysis paper on this, which you’ll find on Arxiv if you want to study extra.
The duty of figuring out duplicate data is commonly finished by means of a pairwise comparability of data and is named “entity matching” (EM). The overall steps on this course of are:
- Information Preparation
- Candidate Era
- blocking
- matching
- Clustering
Information Preparation
Information preparation is the cleansing of information and consists of duties corresponding to eradicating non-ASCII characters, capitalizing, and tokenizing textual content. This is a crucial and obligatory step for NLP matching algorithms later within the course of that don’t work nicely with case-insensitive or non-ASCII characters.
Candidate Era
In typical EM strategies, candidate data are created by combining each document in a desk with itself to generate a Cartesian product. Any mixtures of the row with itself are eliminated. In lots of NLP matching algorithms, evaluating row A to row B is similar as evaluating row B to row A. In these circumstances, solely one in all these pairs must be saved. However even after that, there are nonetheless many candidate data remaining. To scale back this quantity, a method known as “blocking” is commonly used.
blocking
The thought of blocking is to filter out data that you realize will not be duplicates of one another as a result of they’ve totally different values in a “blocking” column. For instance, in case you are contemplating buyer data, a column you would possibly block could be “metropolis”, as a result of you realize that even when all different particulars of the data are comparable sufficient, if they’re positioned in several cities they don’t seem to be the identical buyer. Upon getting generated candidate data, you employ blocking to filter out data which have totally different values within the blocked column.
matching
Following blocking, we take a look at all candidate data and use the fields from the 2 rows to compute conventional NLP similarity-based attribute worth metrics. These metrics can be utilized to find out whether or not they’re possible matches or not.
Clustering
Now that we’ve a listing of candidate matching data, we will group them into clusters.
The proposed technique has a number of steps, however most significantly, it not requires the “knowledge preparation” or “candidate era” steps of the standard technique. The brand new steps are as follows:
- Making a match assertion
- Create embedding vectors for matched sentences
- Clustering
Making a match assertion
First, create a “match assertion” by concatenating the attributes you are concerned about, separated by areas. For instance, say you will have a buyer document that appears like this:
When you create a “match assertion” by concatenating the name1, name2, name3, deal with, and metropolis attributes with areas between them, it can appear to be this:
“John Hartley Smith 20 Essential Avenue London”
Create an embedding vector
As soon as a match has been created, it’s encoded right into a vector area utilizing the chosen embedding mannequin.Text conversionThe output of this encoding is a floating-point vector of predefined dimensions, that are associated to the embedding mannequin used. All MPNET base v2 An embedding mannequin with a 768-dimensional vector area. This embedding vector is added to the document. That is finished for each document.
Clustering
As soon as the embedding vectors for all data have been calculated, the subsequent step is to create clusters of comparable data. To do that, we use the DBSCAN method. DBSCAN works by first deciding on a random document after which discovering data which can be near it utilizing a distance metric. There are two kinds of distance metrics that I’ve discovered to work:
- L2 norm distance
- Cosine similarity
For every of those metrics, we select an epsilon worth as the edge. All data which can be throughout the epsilon distance and have the identical worth within the “block” column are added to this cluster. As soon as a cluster is full, one other random document is chosen from the unvisited data and a cluster is created round it. This continues till all data have been visited.
I’ve used this strategy in my work to determine duplicate data with buyer knowledge. It gave me some excellent matches. To be extra goal, I additionally ran some experiments with a benchmark dataset known as “Musicbrainz 200K”, and the outcomes had been quantifiable and higher than commonplace NLP strategies.
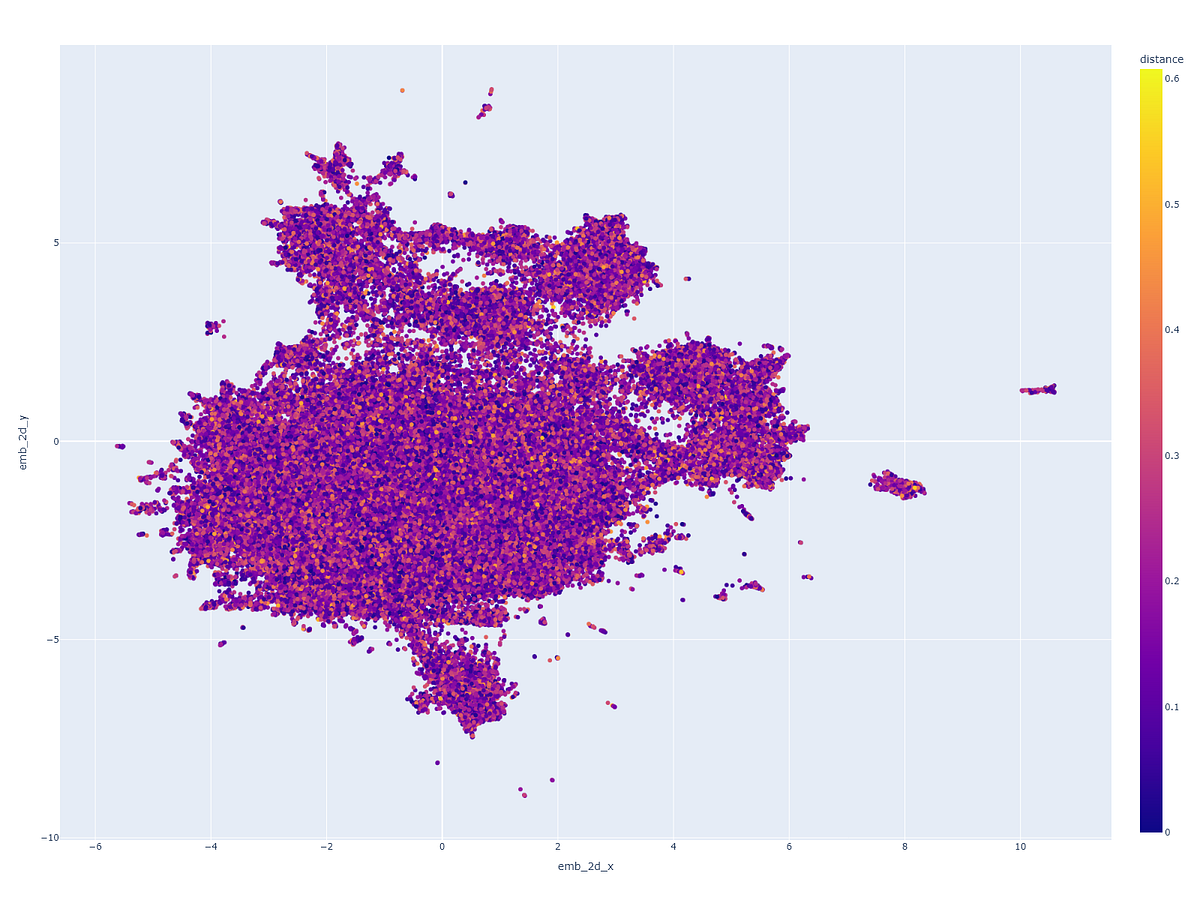
Visualizing the clustering
I created a nearest neighbor cluster map for the Musicbrainz 200K dataset and rendered it in 2D utilizing the UMAP discount algorithm.
useful resource
I’ve created numerous notebooks that will help you do that out for your self.

{kind=link}