


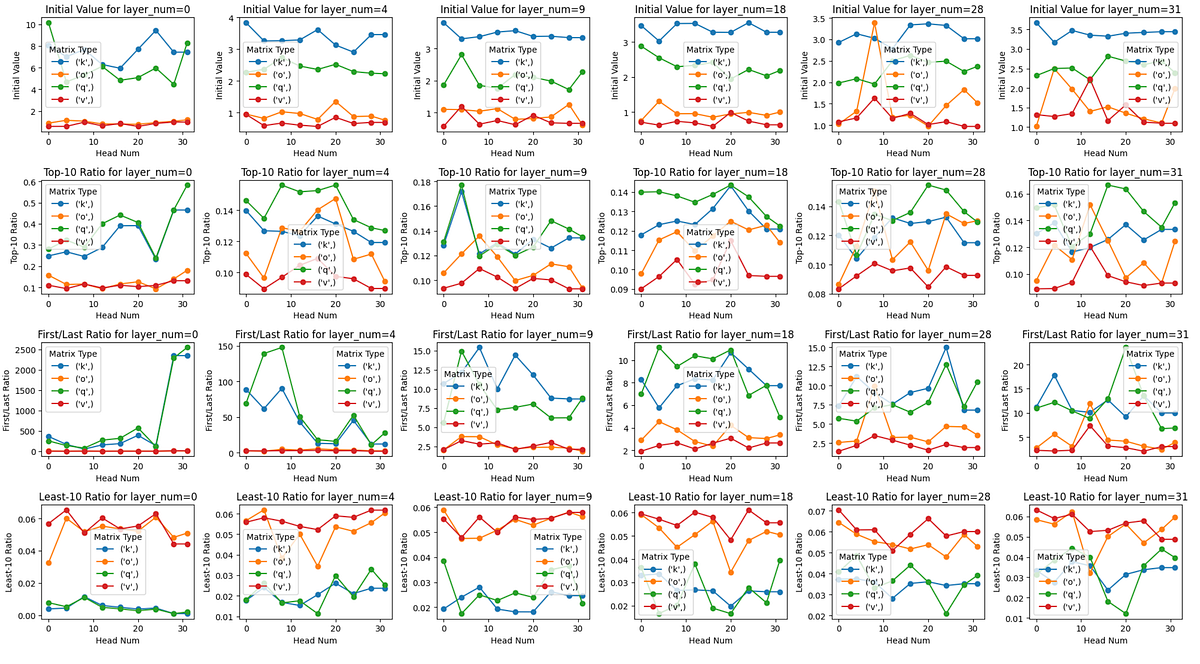
Now, let’s get to the principle topic of this text: analyzing the (Q, Okay, V, O) matrices of the Llama-3–8B-Instruct mannequin with their singular values.
code
First, let’s import all of the packages we’d like for this evaluation.
import transformers
import torch
import numpy as np
from transformers import AutoConfig, LlamaModel
from safetensors import safe_open
import os
import matplotlib.pyplot as plt
Subsequent, obtain the mannequin and reserve it domestically. /tmplisting.
MODEL_ID = "meta-llama/Meta-Llama-3-8B-Instruct"
!huggingface-cli obtain {MODEL_ID} --quiet --local-dir /tmp/{MODEL_ID}
You probably have GPUs in abundance, the next code will not be related to you. Nonetheless, in case you are GPU poor like me, the next code is extraordinarily helpful for loading solely particular layers of the LLama-3–8B mannequin.
def load_specific_layers_safetensors(mannequin, model_name, layer_to_load):
state_dict = {}
recordsdata = [f for f in os.listdir(model_name) if f.endswith('.safetensors')]
for file in recordsdata:
filepath = os.path.be part of(model_name, file)
with safe_open(filepath, framework="pt") as f:
for key in f.keys():
if f"layers.{layer_to_load}." in key:
new_key = key.substitute(f"mannequin.layers.{layer_to_load}.", 'layers.0.')
state_dict[new_key] = f.get_tensor(key)missing_keys, unexpected_keys = mannequin.load_state_dict(state_dict, strict=False)
if missing_keys:
print(f"Lacking keys: {missing_keys}")
if unexpected_keys:
print(f"Sudden keys: {unexpected_keys}")
The explanation we do that is that the free tier of Google Colab GPUs just isn’t sufficient to load LLama-3–8B. fp16 Precision. As well as, this evaluation contains fp32 Accuracy is np.linalg.svd Subsequent, we outline the principle perform that will get the singular values of a given worth. matrix_type , layer_number and head_number.
def get_singular_values(model_path, matrix_type, layer_number, head_number):
"""
Computes the singular values of the required matrix within the Llama-3 mannequin.Parameters:
model_path (str): Path to the mannequin
matrix_type (str): Sort of matrix ('q', 'okay', 'v', 'o')
layer_number (int): Layer quantity (0 to 31)
head_number (int): Head quantity (0 to 31)
Returns:
np.array: Array of singular values
"""
assert matrix_type in ['q', 'k', 'v', 'o'], "Invalid matrix kind"
assert 0 <= layer_number < 32, "Invalid layer quantity"
assert 0 <= head_number < 32, "Invalid head quantity"
# Load the mannequin just for that particular layer since we have now restricted RAM even after utilizing fp16
config = AutoConfig.from_pretrained(model_path)
config.num_hidden_layers = 1
mannequin = LlamaModel(config)
load_specific_layers_safetensors(mannequin, model_path, layer_number)
# Entry the required layer
# At all times index 0 since we have now loaded for the particular layer
layer = mannequin.layers[0]
# Decide the dimensions of every head
num_heads = layer.self_attn.num_heads
head_dim = layer.self_attn.head_dim
# Entry the required matrix
weight_matrix = getattr(layer.self_attn, f"{matrix_type}_proj").weight.detach().numpy()
if matrix_type in ['q','o']:
begin = head_number * head_dim
finish = (head_number + 1) * head_dim
else: # 'okay', 'v' matrices
# Modify the head_number primarily based on num_key_value_heads
# That is achieved since llama3-8b use Grouped Question Consideration
num_key_value_groups = num_heads // config.num_key_value_heads
head_number_kv = head_number // num_key_value_groups
begin = head_number_kv * head_dim
finish = (head_number_kv + 1) * head_dim
# Extract the weights for the required head
if matrix_type in ['q', 'k', 'v']:
weight_matrix = weight_matrix[start:end, :]
else: # 'o' matrix
weight_matrix = weight_matrix[:, start:end]
# Compute singular values
singular_values = np.linalg.svd(weight_matrix, compute_uv=False)
del mannequin, config
return record(singular_values)
It’s value noting that we will extract the weights for a given head of the Okay, Q, and V matrices by performing row-wise slicing, which is carried out as follows: Hugging Face.

(d_out,d_in)Supply: Picture by writer.As for the O matrix, because of linear algebra we will slice it column-wise to extract the weights of a given head with O weights, as you possibly can see in additional element within the following diagram:


{kind=link}