


Audio classification has made nice strides with the adoption of deep studying fashions. Initially dominated by Convolutional Neural Networks (CNNs), the sphere has moved in direction of Transformer-based architectures that provide improved efficiency and the power to deal with a wide range of duties with a unified strategy. Transformers have outperformed CNNs in efficiency, ushering in a paradigm shift in deep studying, particularly for options that require broad contextual understanding and the power to deal with numerous enter knowledge sorts.
A significant problem in audio classification is the computational complexity related to Transformers, particularly because of the self-attention mechanism, which grows linearly with the size of the sequence. This makes processing lengthy audio sequences inefficient and requires different strategies to keep up efficiency whereas lowering the computational burden. Addressing this difficulty is crucial to develop fashions that may effectively deal with the rising quantity and complexity of audio knowledge for a wide range of purposes, from speech recognition to environmental sound classification.
At the moment, probably the most outstanding methodology for audio classification is the Audio Spectrogram Transformer (AST). AST makes use of a self-attention mechanism to seize the worldwide context of audio knowledge, however suffers from being computationally costly. State Area Fashions (SSMs) have been explored as a possible different that may scale linearly with sequence size. SSMs corresponding to Mamba have proven promise in language and imaginative and prescient duties by changing self-attention with time-varying parameters to seize international context extra effectively. Regardless of success in different domains, SSMs haven’t but been broadly adopted in audio classification, providing a possibility for innovation on this area.
Researchers on the Korea Superior Institute of Science and Expertise introduced Audio Mamba (AuM), a brand new self-attention-free mannequin based mostly on a state-space mannequin for audio classification. The mannequin makes use of a bidirectional strategy to effectively course of audio spectrograms and handles lengthy sequences with out the quadratic scaling related to Transformers. The AuM mannequin goals to remove the computational burden of self-attention and leverage SSM to enhance effectivity whereas sustaining excessive efficiency. By addressing the inefficiencies of Transformers, AuM offers a promising different for audio classification duties.
Audio Mamba’s structure converts the enter audio waveform right into a spectrogram and splits it into patches. These patches are transformed into embedding tokens and processed utilizing a bidirectional state-space mannequin. The mannequin works in each ahead and backward instructions, effectively captures international context, and maintains linear time complexity, leading to improved processing pace and reminiscence utilization in comparison with ASTs. The structure incorporates a number of modern design decisions, together with strategically inserting learnable classification tokens within the heart of the sequence and utilizing positional embeddings to reinforce the mannequin’s means to grasp the spatial construction of the enter knowledge.
Audio Mamba carried out competitively on a spread of benchmarks, together with AudioSet, VGGSound, and VoxCeleb. The mannequin achieved outcomes corresponding to or higher than AST, particularly on duties involving lengthy audio sequences. For instance, on the VGGSound dataset, Audio Mamba considerably outperformed AST by over 5%, reaching 42.58% accuracy in comparison with AST’s 37.25%. On the AudioSet dataset, AuM achieved a imply common precision (mAP) of 32.43%, beating AST’s 29.10%. These outcomes spotlight that AuM can carry out properly whereas remaining computationally environment friendly, making it a strong answer for a spread of audio classification duties.
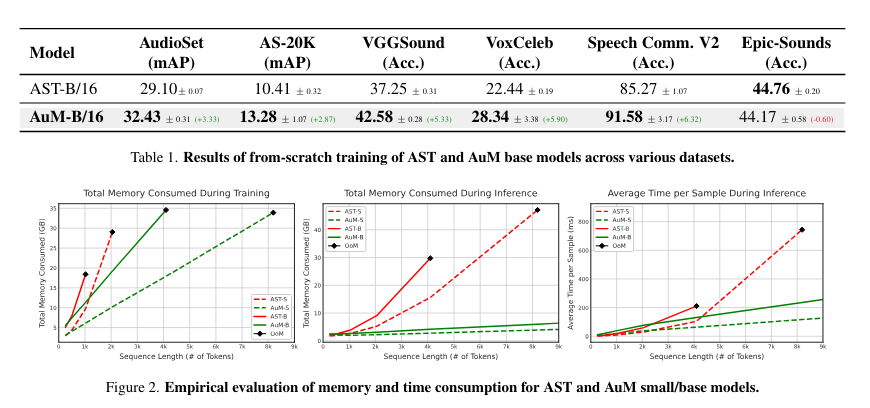
Analysis outcomes present that AuM can considerably scale back reminiscence and processing time. For instance, when coaching with a 20-second audio clip, AuM outperforms the AST’s smaller mannequin whereas consuming related reminiscence. Moreover, for 4096 tokens, AuM’s inference time is 1.6x sooner than AST, demonstrating its effectivity in processing lengthy sequences. The discount in computational necessities with out sacrificing accuracy demonstrates AuM’s suitability for real-world purposes the place useful resource constraints are an vital consideration.
In abstract, the introduction of Audio Mamba marks a significant development in audio classification by addressing the restrictions of Transformer self-attention. The mannequin’s effectivity and aggressive efficiency spotlight its potential as a viable different for processing lengthy audio sequences. The researchers imagine that Audio Mamba’s strategy could pave the best way for the event of future audio and multimodal studying purposes. The flexibility to course of lengthy audio is turning into more and more vital, particularly with the rise of self-supervised multimodal studying and era leveraging in-the-wild knowledge and computerized speech recognition. Moreover, AuM will be employed in self-supervised studying setups corresponding to audio masks autoencoders, in addition to multimodal studying duties corresponding to audio-visual pre-training and contrastive language audio pre-training, contributing to advances within the area of audio classification.
Please test paper. All credit score for this analysis goes to the researchers of this venture. Additionally, do not forget to observe us. twitter. take part Telegram Channel, Discord Channeland LinkedIn GroupsUp.
For those who like our work, you’ll love our Newsletter..
Please be part of us 43,000+ ML subreddits | As well as, our AI Event Platform
![]()
Nikhil is an Intern Marketing consultant at Marktechpost. He’s pursuing a twin diploma in Built-in Supplies from Indian Institute of Expertise Kharagpur. Nikhil is an avid advocate of AI/ML and is continually exploring its purposes in areas corresponding to biomaterials and biomedicine. Together with his in depth expertise in supplies science, Nikhil enjoys exploring new developments and creating alternatives to contribute.

{kind=link}