


It’s no secret that the tempo of AI analysis is exponentially accelerating. One of many largest tendencies of the previous couple of years has been utilizing transformers to take advantage of huge-scale datasets. It appears like this development has lastly reached the sector of lip-sync fashions. The EMO release by Alibaba set the precedent for this (I imply take a look at the 200+ GitHub points begging for code launch). However the bar has been raised even larger with Microsoft’s VASA-1 last month.
They’ve obtained a variety of hype, however thus far nobody has mentioned what they’re doing. They appear like virtually equivalent works on the face of it (pun meant). Each take a single picture and animate it utilizing audio. Each use diffusion and each exploit scale to provide phenomenal outcomes. However truly, there are just a few variations below the hood. This text will take a sneak peek at how these fashions function. We additionally check out the moral issues of those papers, given their apparent potential for misuse.
A mannequin can solely be nearly as good as the information it’s educated on. Or, extra succinctly, Rubbish In = Rubbish Out. Most present lip sync papers make use of 1 or two, moderately small datasets. The 2 papers we’re discussing completely blow away the competitors on this regard. Let’s break down what they use. Alibaba state in EMO:
We collected roughly 250 hours of speaking head movies from the web and supplemented this with the HDTF [34] and VFHQ [31] datasets to coach our fashions.
Precisely what they imply by the extra 250 hours of collected knowledge is unknown. Nevertheless, HDTF and VFHQ are publicly obtainable datasets, so we are able to break these down. HDTF consists of 16 hours of knowledge over 300 topics of 720–1080p video. VFHQ doesn’t point out the size of the dataset by way of hours, but it surely has 15,000 clips and takes up 1.2TB of knowledge. If we assume every clip is, on common, at the least 10s lengthy then this could be a further 40 hours. This implies EMO makes use of at the least 300 hours of knowledge. For VASA-1 Microsoft say:
The mannequin is educated on VoxCeleb2 [13] and one other high-resolution discuss video dataset collected by us, which incorporates about 3.5K topics.
Once more, the authors are being secretive about a big a part of the dataset. VoxCeleb2 is publicly obtainable. Trying on the accompanying paper we are able to see this consists of 2442 hours of knowledge (that’s not a typo) throughout 6000 topics albeit in a decrease decision than the opposite datasets we talked about (360–720p). This may be ~2TB. Microsoft makes use of a dataset of three.5k extra topics, which I believe are far larger high quality and permit the mannequin to provide high-quality video. If we assume that is at the least 1080p and a few of it’s 4k, with comparable durations to VoxCeleb2 then we are able to count on one other 5–10TB.
For the next, I’m making some educated guesses: Alibaba probably makes use of 300 hours of high-quality video (1080p or larger), whereas Microsoft makes use of ~2500 hours of low-quality video, and possibly someplace between 100–1000 hours of very high-quality video. If we attempt to estimate the dataset dimension by way of space for storing we discover that EMO and VASA-1 every use ~10TB of face video knowledge to coach their mannequin. For some comparisons try the next chart:

Each fashions make use of diffusion and transformers to utilise the huge datasets. Nevertheless, there are some key variations in how they work.
We are able to break down VASA-1 into two elements. One is a picture formation mannequin that takes some latent illustration of the facial features and pose and produces a video body. The opposite is a mannequin that generates these latent pose and expression vectors from audio enter. The picture formation mannequin

Picture Formation Mannequin
VASA-1 depends closely on a 3D volumetric illustration of the face, constructing upon earlier work from Samsung referred to as MegaPortraits. The thought right here is to first estimate a 3D illustration of a supply face, warp it utilizing the anticipated supply pose, make edits to the expression utilizing information of each the supply and goal expressions on this canonical house, after which warp it again utilizing a goal pose.

In additional element, this course of appears as follows:
- Take the supply picture (the person within the diagram above) and predict a easy 1D vector which represents this man.
- Additionally predict a 4D tensor (Width, Peak, Depth, RGB) as a volumetric illustration of him.
- Predict for each the supply and driver (the girl above) their pose and facial features. Word that solely the pose estimation is pre-trained, all of the others are educated fully from scratch.
- Create two warping fields utilizing neural networks. One converts the person’s volumetric illustration right into a canonical house (this simply means a front-facing, impartial expression) utilizing our estimate of his id, pose and facial features. The opposite converts his canonical 3D face right into a posed 3D face utilizing estimates of the girl’s pose and expression, in addition to the person’s id.
- “Render” the posed man’s face again into 2D.
For particulars on how precisely they do that, that’s how do you challenge into 3D, how is the warping achieved and the way is the 2D picture created from the 3D quantity, please check with the MegaPortraits paper.
This extremely complicated course of could be simplified in our minds at this level to only think about a mannequin that encodes the supply ultimately after which takes parameters for pose and expression, creating a picture based mostly on these.
Audio-to-latent Era
We now have a method to generate video from a sequence of expressions and pose latent codes. Nevertheless, not like MegaPortraits, we don’t need to management our movies utilizing one other individual’s expressions. As a substitute, we wish management from audio alone. To do that, we have to construct a generative mannequin that takes audio as enter and outputs latent vectors. This must scale as much as enormous quantities of knowledge, have lip-sync and likewise produce various and believable head motions. Enter the diffusion transformer. Not conversant in these fashions? I don’t blame you, there are a variety of advances right here to maintain up with. I can advocate the next article:
However in a nutshell, diffusion transformers (DiTs) substitute the traditional UNET in image-based diffusion fashions with a transformer. This change permits studying on knowledge with any construction, due to tokenization, and it is usually identified to scale extraordinarily effectively to massive datasets. For instance, OpenAI’s SORA mannequin is believed to be a diffusion transformer.

The thought then is to start out from random noise in the identical form because the latent vectors and step by step denoise them to provide significant vectors. This course of can then be conditioned on extra alerts. For our functions, this consists of audio, extracted into function vectors utilizing Wav2Vec2 (see FaceFormer for a way precisely this works). Extra alerts are additionally used. We gained’t go into an excessive amount of element however they embrace eye gaze route and emotion. To make sure temporal stability, the beforehand generated movement latent codes are additionally used as conditioning.

EMO takes a barely completely different strategy with its era course of, although it nonetheless depends on diffusion at its core. The mannequin diagram appears a bit crowded, so I feel its greatest to interrupt it into smaller components.
Utilizing Steady Diffusion
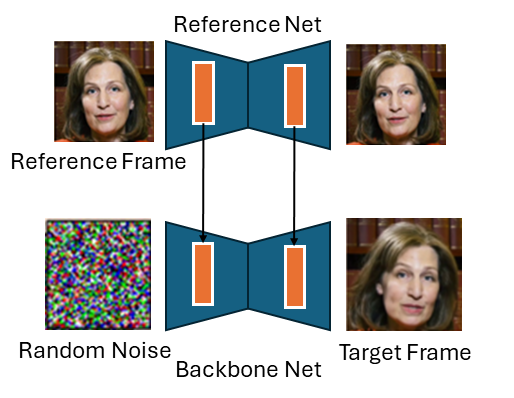
The very first thing to note is that EMO makes heavy use of the pretrained Steady Diffusion 1.5 mannequin. There’s a strong development in imaginative and prescient at massive at present in the direction of constructing on prime of this mannequin. Within the above diagram, the reference web and the spine community are each situations of the SD1.5 UNET archietecture and are initialised with these weights. The element is missing, however presumably the VAE encoder and decoder are additionally taken from Steady Diffusion. The VAE elements are frozen, which means that all the operations carried out within the EMO mannequin are achieved within the latent house of that VAE. Using the identical archieture and identical beginning weights is helpful as a result of it permits activations from intermediate layers to be simply taken from one community and utilized in one other (they may roughly signify the identical factor in each community).
Coaching the First Stage
The purpose of the primary stage is to get a single picture mannequin that may generate a novel picture of an individual, given a reference body of that individual. That is achieved utilizing a diffusion mannequin. A fundamental diffusion mannequin could possibly be used to generate random photos of individuals. In stage one, we need to, ultimately, situation this era course of on id. The best way the authors do that is by encoding a reference picture of an individual utilizing the reference web, and introducing the activations in every layer into the spine community which is doing the diffusion. See the (poorly drawn) diagram beneath.

At this stage, we now have a mannequin that may generate random frames of an individual, given a single picture of that individual. We now want to regulate it ultimately.
Coaching the Second Stage
We need to management the generated frames utilizing two alerts, movement and audio. The audio half is the better to clarify, so I’ll cowl this primary.

- Audio: As with VASA-1, audio is encoded within the type of wav2vec2 options. These are included into the spine community utilizing cross consideration. This cross consideration replaces the textual content immediate cross consideration already current within the Steady Diffusion 1.5 mannequin.
- Movement: Movement is added utilizing movement frames, to foretell the body at time t, the earlier n frames are used to offer context for the movement. The movement frames are encoded in the identical approach because the reference body. The intermediate function activations of the reference web are used to situation the spine mannequin. The inclusion of those movement referenece activations is completed utilizing a specifically designed cross-attention layer, taken from AnimateDiff. From these n frames, the subsequent f are predicted utilizing the diffusion mannequin.
Along with this, two different elements are used. One gives a masks, taken because the union of all bounding packing containers throughout the coaching video. This masks defines what area of the video is allowed to be modified. The opposite is a small addition of a pace situation is used. The pose velocity is split into buckets (assume gradual, medium, quick) and likewise included. This enables us to specify the pace of the movement at inference time.
Inference
The mannequin is now in a position to take the next and produces a brand new set of frames:
- A reference body
- The earlier n frames
- The audio
- The top movement pace
- A bounding field of pixels that may be modified
For the primary body, it’s not said, however I assume the reference body is repeated and handed because the final n frames. After this level, the mannequin is autoregressive, the outputs are then used because the earlier frames for enter.
The moral implications of those works are, in fact, very important. They require solely a single picture so as to create very life like artificial content material. This might simply be used to misrepresent folks. Given the latest controversy surrounding OpenAI’s use of a voice that sounds suspiciously like Scarlett Johansen without her consent, the problem is especially related for the time being. The 2 teams take reasonably completely different approaches.
EMO
The dialogue within the EMO paper may be very a lot missing. The paper doesn’t embrace any dialogue of the moral implications or any proposed strategies of stopping misuse. The challenge web page says solely:
“This challenge is meant solely for tutorial analysis and impact demonstration”
This looks like a really weak try. Moreover, Alibaba embrace a GitHub repo which (might) make the code publicly obtainable. It’s necessary to contemplate the professionals and cons of doing this, as we discuss in a previous article. Total, the EMO authors haven’t proven an excessive amount of consideration for ethics.
VASA-1
VASA-1’s authors take a extra complete strategy to stopping misuse. They embrace a bit within the paper devoted to this, highlighting the potential makes use of in deepfake detection in addition to the optimistic advantages.

Along with this, additionally they embrace a reasonably attention-grabbing assertion:
Word: all portrait photos on this web page are digital, non-existing identities generated by StyleGAN2 or DALL·E-3 (aside from Mona Lisa). We’re exploring visible affective ability era for digital, interactive characters, NOT impersonating any individual in the true world. That is solely a analysis demonstration and there’s no product or API launch plan.
The strategy is definitely one Microsoft have began to soak up just a few papers. They solely create artificial movies utilizing artificial folks and don’t launch any of their fashions. Doing so prevents any attainable misuse, as no actual persons are edited. Nevertheless, it does increase points round the truth that the facility to create such movies in concentrated into the arms of big-tech corporations which have the infrastructure to coach such fashions.
Additional Evaluation
For my part this line of labor opens up a brand new set of moral points. Whereas it had been beforehand attainable to create pretend movies of individuals, it normally required a number of minutes of knowledge to coach a mannequin. This largely restricted the potential victims to individuals who create numerous video already. Whereas this allowed for the creation of political misinformation, the constraints helped to stifle another functions. For one, if somebody creates a variety of video, it’s attainable to inform what their regular content material appears like (what do they normally discuss, what their opinions are, and so on.) and may be taught to identify movies which are uncharacteristic. This turns into tougher if a single picture can be utilized. What’s extra, anybody can turn into a sufferer of those fashions. Even a social media account with a profile image could be sufficient knowledge to construct a mannequin of an individual.
Moreover, as a unique class of “deepfake” there’s not a lot analysis on the way to detect these fashions. Strategies that will have labored to catch video deepfake fashions would turn into unreliable.
We have to make sure that the hurt brought on by these fashions is proscribed. Microsoft’s strategy of limiting entry and solely utilizing artificial folks helps for the brief time period. However long run we’d like sturdy regulation of the functions of those fashions, in addition to dependable strategies to detect content material generated by them.
Each VASA-1 and EMO are unimaginable papers. They each exploit diffusion fashions and large-scale datasets to provide extraordinarily top quality video from audio and a single picture. A number of key factors stand out to me:
- It’s not fairly a case of scale is all you want. Each fashions use intelligent tips (VASA-1’s use of MegaPortiats and EMO’s reference & spine nets). Nevertheless, it does appear to be the case that “scale is one thing you want”.
- Diffusion is king. Each of those fashions, in addition to most state-of-the-art era in imaginative and prescient, use diffusion. It appears that evidently VAE’s and GAN’s are virtually really lifeless.
- The sphere of lip-sync fashions is more likely to turn into the area of the massive corporations solely quickly. If tendencies proceed, there is no such thing as a approach teachers will be capable of construct fashions that sustain with these.

{kind=link}