


The event of large-scale language fashions, significantly ChatGPT, has amazed those that have experimented with it, together with myself, with its unimaginable linguistic capabilities and talent to carry out all kinds of duties. Nonetheless, many researchers, together with myself, are each stunned and confused by this potential. Regardless that I do know the structure of my mannequin and the precise values of its weights, I’m having bother understanding why a specific sequence of inputs results in a specific sequence of outputs.
On this weblog publish, we are going to demystify GPT2-small utilizing the interpretability of the mechanism within the easy case of repeated token prediction.
Conventional mathematical instruments for describing machine studying fashions usually are not completely appropriate for language fashions.
Think about SHAP, a instrument that helps clarify machine studying fashions. They’re adept at figuring out which options had a big affect on predicting top quality wines. Nonetheless, it is very important keep in mind that language fashions make predictions on the token stage, whereas SHAP values are primarily calculated on the function stage, so that they will not be appropriate for tokens.
Moreover, language fashions (LLMs) have numerous parameters and inputs, making a high-dimensional area. Computing SHAP values is pricey even in low-dimensional areas, and much more so within the high-dimensional areas of LLMs.
Regardless of permitting for top computational prices, the reason offered by SHAP may be superficial. For instance, discovering that the time period “Potter” influenced the output prediction essentially the most as a result of point out of “Harry” talked about above doesn’t present a lot perception. Subsequently, components of the mannequin and the precise mechanisms concerned in such predictions stay unclear.
Mechanistic Interpretability presents a unique strategy. It isn’t nearly figuring out vital options and inputs for mannequin prediction. As an alternative, it sheds gentle on the underlying mechanisms and inference processes, serving to us perceive how fashions make predictions and choices.
We use GPT2-small for the straightforward activity of predicting sequences of repeated tokens.The library we are going to use this time is transformer lensis designed for mechanical interpretability GPT-2 fashion language mannequin.
gpt2_small: HookedTransformer = HookedTransformer.from_pretrained("gpt2-small")
Use the above code to load the GPT2-Small mannequin and predict the tokens on the sequence generated by a specific perform. This sequence incorporates two an identical token sequences, adopted by bos_token. For instance, if seq_len is 3, it turns into “ABCDABCD” + bos_token. For readability, the sequence from the start to seq_len is named the primary half, and the remaining sequence excluding bos_token is named the second half.
def generate_repeated_tokens(
mannequin: HookedTransformer, seq_len: int, batch: int = 1
) -> Int[Tensor, "batch full_seq_len"]:
'''
Generates a sequence of repeated random tokensOutputs are:
rep_tokens: [batch, 1+2*seq_len]
'''
bos_token = (t.ones(batch, 1) * mannequin.tokenizer.bos_token_id).lengthy() # generate bos token for every batch
rep_tokens_half = t.randint(0, mannequin.cfg.d_vocab, (batch, seq_len), dtype=t.int64)
rep_tokens = t.cat([bos_token,rep_tokens_half,rep_tokens_half], dim=-1).to(gadget)
return rep_tokens
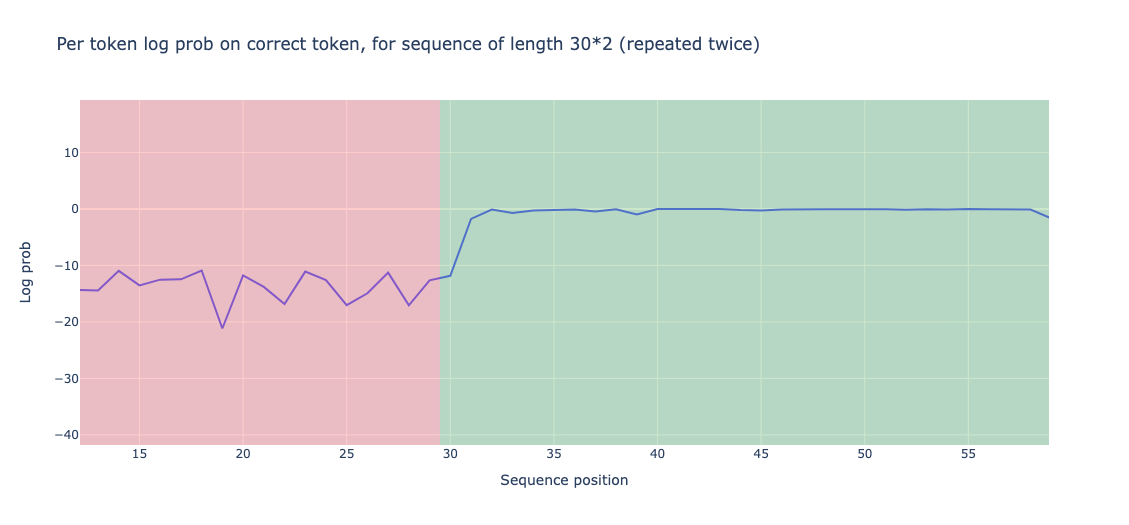
Permitting the mannequin to run on the generated tokens yields some attention-grabbing observations. The mannequin performs considerably higher within the second half of the sequence than within the first half. That is measured by the log likelihood of an accurate token. To be exact, the efficiency within the first half is -13.898 and the efficiency within the second half is -0.644.

You can even calculate prediction accuracy, outlined because the ratio of accurately predicted tokens (an identical to the generated tokens) to the full variety of tokens. The accuracy of the primary half of the sequence is 0.0, which isn’t stunning since we’re coping with random tokens that don’t have any actual that means. However, the accuracy within the second half was 0.93, which was considerably increased than the primary half.
Seek for induction heads
The above commentary could also be defined by the presence of an inductive circuit. It is a circuit that scans the sequence of earlier situations of the present token, identifies tokens that beforehand adopted it, and predicts that the identical sequence will repeat. For instance, if we encounter ‘A’, we scan the earlier ‘A’ or tokens similar to ‘A’ within the embedding area, determine the following token ‘B’, and determine the following token after ‘A’. Predict tokens. ‘ turns into ‘B’ or a token just like ‘B’ within the embedding area.

This prediction course of may be divided into two steps:
- Determine earlier an identical (or related) tokens. All tokens later within the sequence should “listen” to the token “seq_len” that comes earlier than it. For instance, if “seq_len” is 3, “A” in place 4 should take note of “A” in place 1. The eye head that performs this activity may be known as “.induction head”
- Determine the following token ‘B’. That is the method of copying info from the earlier token (equivalent to “A”) to the following token (equivalent to “B”). This info is used to “recreate” “B” when “A” seems once more. The eye head that performs this activity may be known as “.earlier token head”
These two heads type an entire inductive circuit. The time period “induction head” is usually used to explain all the “induction circuit”.For extra details about inductive circuits, I extremely advocate this text Head of Learning in Context and Implementation It is a masterpiece!
Now, let’s determine the eye head and the earlier head utilizing GPT2-small.
The next code is used to search out the induction head. First, run the mannequin in 30 batches. Subsequent, calculate the imply worth of the diagonal utilizing the seq_len offset of the sample of curiosity matrix. This technique permits you to measure the eye that the present token provides to tokens that beforehand appeared in seq_len.
def induction_score_hook(
sample: Float[Tensor, "batch head_index dest_pos source_pos"],
hook: HookPoint,
):
'''
Calculates the induction rating, and shops it within the [layer, head] place of the `induction_score_store` tensor.
'''
induction_stripe = sample.diagonal(dim1=-2, dim2=-1, offset=1-seq_len) # src_pos, des_pos, one place proper from seq_len
induction_score = einops.scale back(induction_stripe, "batch head_index place -> head_index", "imply")
induction_score_store[hook.layer(), :] = induction_scoreseq_len = 50
batch = 30
rep_tokens_30 = generate_repeated_tokens(gpt2_small, seq_len, batch)
induction_score_store = t.zeros((gpt2_small.cfg.n_layers, gpt2_small.cfg.n_heads), gadget=gpt2_small.cfg.gadget)
rep_tokens_30,
return_type=None,
pattern_hook_names_filter,
induction_score_hook
)]
)
Subsequent, let’s study the induction rating. We will see that some heads, equivalent to layer 5 and head 5, have a excessive induction rating of 0.91.

You can even view the featured sample for this head. You possibly can see that there’s a clear diagonal line as much as the seq_len offset.

Equally, you may determine the earlier token head. For instance, head 11 in layer 4 reveals a powerful sample of the earlier token.

How do MLP layers set attributes?
Think about the query, “Does the MLP layer matter?” We all know that GPT2-Small contains each an consideration layer and an MLP layer. To analyze this, I suggest to make use of an ablation method.
Ablation, because the identify suggests, systematically removes sure mannequin elements and observes how efficiency modifications because of this.
Exchange the output of the MLP layer within the second half of the sequence with the output within the first half and observe how this impacts the ultimate loss perform. Use the next code to calculate the distinction between the loss after changing the output of the MLP layer and the unique lack of the late sequence.
def patch_residual_component(
residual_component,
hook,
pos,
cache,
):
residual_component[0,pos, :] = cache[hook.name][pos-seq_len, :]
return residual_componentablation_scores = t.zeros((gpt2_small.cfg.n_layers, seq_len), gadget=gpt2_small.cfg.gadget)
gpt2_small.reset_hooks()
logits = gpt2_small(rep_tokens, return_type="logits")
loss_no_ablation = cross_entropy_loss(logits[:, seq_len: max_len],rep_tokens[:, seq_len: max_len])
for layer in tqdm(vary(gpt2_small.cfg.n_layers)):
for place in vary(seq_len, max_len):
hook_fn = functools.partial(patch_residual_component, pos=place, cache=rep_cache)
ablated_logits = gpt2_small.run_with_hooks(rep_tokens, fwd_hooks=[
(utils.get_act_name("mlp_out", layer), hook_fn)
])
loss = cross_entropy_loss(ablated_logits[:, seq_len: max_len], rep_tokens[:, seq_len: max_len])
ablation_scores[layer, position-seq_len] = loss - loss_no_ablation
We reached superb outcomes. Apart from the primary token, ablation doesn’t lead to important logit variations. This means that the MLP layer could not have a big contribution if the tokens are repeated.

Contemplating that the MLP layers don’t considerably contribute to the ultimate prediction, we will manually construct the inductive circuit utilizing head 5, the top of layer 5, and head 11, the top of layer 4. Bear in mind these are the induction head and head 11. Earlier token head. Do it with the next code.
def K_comp_full_circuit(
mannequin: HookedTransformer,
prev_token_layer_index: int,
ind_layer_index: int,
prev_token_head_index: int,
ind_head_index: int
) -> FactoredMatrix:
'''
Returns a (vocab, vocab)-size FactoredMatrix,
with the primary dimension being the question facet
and the second dimension being the important thing facet (going through the earlier token head)'''
W_E = gpt2_small.W_E
W_Q = gpt2_small.W_Q[ind_layer_index, ind_head_index]
W_K = mannequin.W_K[ind_layer_index, ind_head_index]
W_O = mannequin.W_O[prev_token_layer_index, prev_token_head_index]
W_V = mannequin.W_V[prev_token_layer_index, prev_token_head_index]
Q = W_E @ W_Q
Okay = W_E @ W_V @ W_O @ W_K
return FactoredMatrix(Q, Okay.T)
Calculating the highest 1 accuracy of this circuit yields a worth of 0.2283. That is very good for a circuit that solely consists of two heads.
For detailed implementation please verify my article Note.

{kind=link}