


Singing voice conversion (SVC) is an interesting area inside audio processing that goals to remodel one singer’s voice into one other singer’s voice whereas preserving the content material and melody of the tune. This expertise can be utilized for a variety of purposes, from enhancing musical leisure to creative creation. A significant problem on this area is the gradual processing pace, particularly in his diffusion-based SVC methodology. Though these strategies produce high-quality, natural-looking audio, they’re hampered by lengthy and iterative sampling processes, making them poorly fitted to real-time purposes.
Varied generative fashions have tried to deal with the challenges of SVC, together with autoregressive fashions, generative adversarial networks, circulation regularization, and diffusion fashions. Every methodology makes an attempt to disentangle and encode singer-independent and singer-dependent options from audio information, with various levels of success when it comes to audio high quality and processing effectivity.
The introduction of CoMoSVC, a brand new methodology developed by Hong Kong College of Science and Know-how and Microsoft Analysis Asia leveraging consistency fashions, represents a big development in SVC. This strategy goals to concurrently obtain high-quality audio era and quick sampling. At its core, CoMoSVC takes a diffusion-based trainer mannequin particularly designed for SVC and additional refines the method by a distilled scholar mannequin based mostly on the property of self-consistency. This innovation permits one-step sampling, which is a serious advance in addressing the gradual inference pace of conventional strategies.
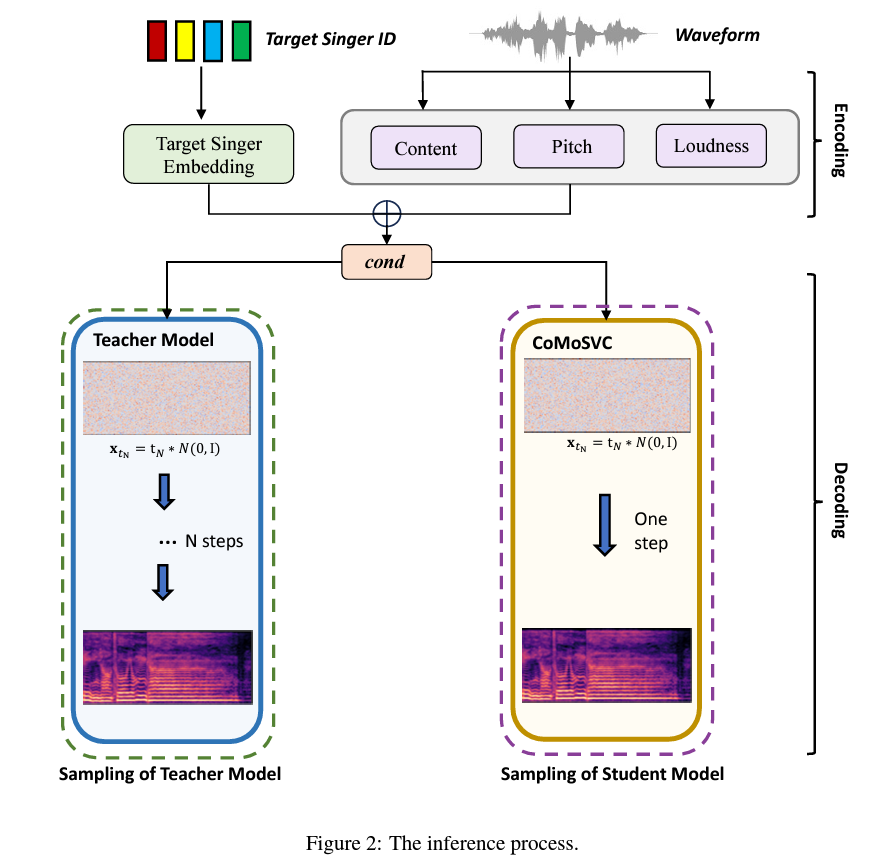
Digging deeper into the methodology, CoMoSVC works by a two-step course of: encoding and decoding. Within the encoding stage, options are extracted from the waveform and the singer’s identification is encoded into the embedding. The place CoMoSVC actually innovates is within the decoding stage. Use these embeddings to generate a spectrogram of Mel’s after which render it to audio. A distinguishing characteristic of CoMoSVC is the scholar mannequin extracted from the pre-trained trainer mannequin. This mannequin permits for speedy, one-step audio sampling whereas sustaining prime quality, a feat not attainable with earlier strategies.
By way of efficiency, CoMoSVC reveals outstanding outcomes. It considerably outperforms state-of-the-art diffusion-based SVC techniques in inference pace, as much as 500 occasions sooner. Nonetheless, you possibly can keep comparable and even higher audio high quality and efficiency. Goal and subjective evaluations of CoMoSVC reveal its capability to attain comparable or superior conversion efficiency. This steadiness of pace and high quality makes CoMoSVC his breakthrough growth in SVC expertise.
In conclusion, CoMoSVC is a vital milestone in singing voice conversion expertise. Addresses the important drawback of gradual inference pace with out compromising audio high quality. By innovatively combining a teacher-student mannequin framework and a consistency mannequin, CoMoSVC establishes a brand new customary on this area and offers a quick and high-performance answer that has the potential to revolutionize purposes in music leisure and different fields. Gives high quality voice conversion. This development solves long-standing challenges in SVC and opens new prospects for real-time, environment friendly voice conversion purposes.
Please verify paper and project. All credit score for this examine goes to the researchers of this venture.Do not forget to comply with us twitter.take part 35,000+ ML SubReddits, 41,000+ Facebook communities, Discord channeland linkedin groupsHmm.
If you like what we do, you’ll love our newsletter.
![]()
Muhammad Athar Ganaie, consulting intern at MarktechPost, is an advocate of environment friendly deep studying with a concentrate on sparse coaching. A grasp’s diploma in electrical engineering with a specialization in software program engineering combines superior technical information with sensible purposes. His present work is a paper on “Enhancing the Effectivity of Deep Reinforcement Studying,” which demonstrates his dedication to enhancing the capabilities of AI. Athar’s analysis lies on the intersection of “sparse coaching of DNNs” and “deep reinforcement studying.”

{kind=link}