


TL;DR: Textual content immediate -> LLM -> Intermediate illustration (e.g. picture format) -> Steady diffusion -> Picture.
Current advances in text-to-image era utilizing diffusion fashions have yielded outstanding leads to synthesizing extremely sensible and various photos.Nevertheless, regardless of its nice options, widespread fashions corresponding to stable diffusionthey usually have bother following prompts precisely when spatial or frequent sense reasoning is required.
The next diagram exhibits 4 situations wherein secure diffusion can not produce photos that correspond precisely to a given immediate. denial, arithmeticand Attribute project, spatial relationship. In distinction, our technique LLM-grounded Ddiffusion(LMD), supplies higher and quicker understanding in text-to-image era in these situations.
Determine 1: LLM-based diffusion enhances the fast comprehension potential of text-to-image diffusion fashions.
One doable resolution to deal with this downside is, after all, to gather huge multimodal datasets with complicated captions and use large-scale language encoders to coach large-scale diffusion fashions. That is it. This strategy comes at a major price. Coaching each large-scale language fashions (LLMs) and diffusion fashions is time-consuming and costly.
our resolution
To effectively clear up this downside with minimal price (i.e., no coaching price), as a substitute, Equip diffusion fashions with enhanced spatial and customary sense reasoning utilizing off-the-shelf frozen LLMs With a brand new two-step era course of.
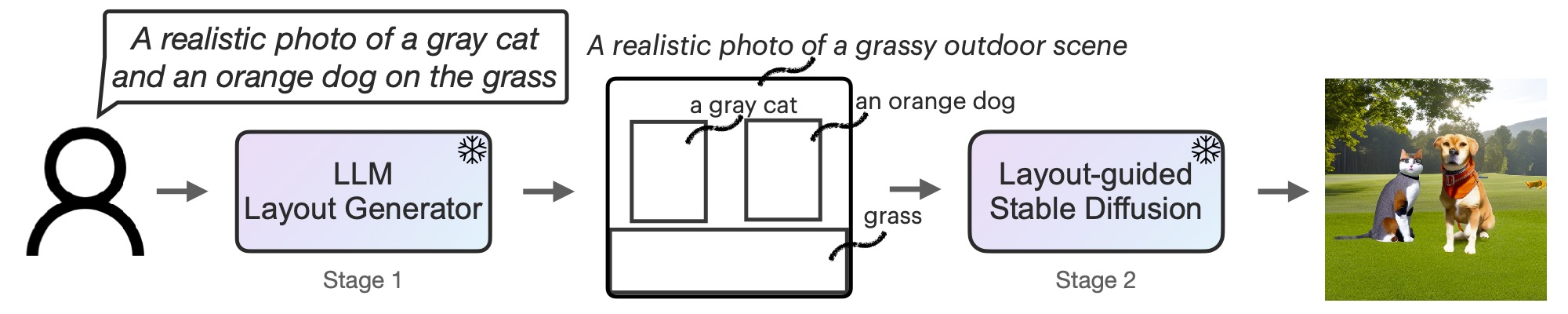
First, we adapt LLM as a text-guided format generator by way of in-context studying. When a picture immediate is supplied, LLM outputs the scene format within the type of a bounding field with a corresponding particular person description. Subsequent, use the brand new controller to govern the diffusion mannequin and generate photos in line with your format. Each levels make the most of a frozen pre-trained mannequin with none optimization of LLM or diffusion mannequin parameters.invite readers Read the paper on arXiv For extra data, see
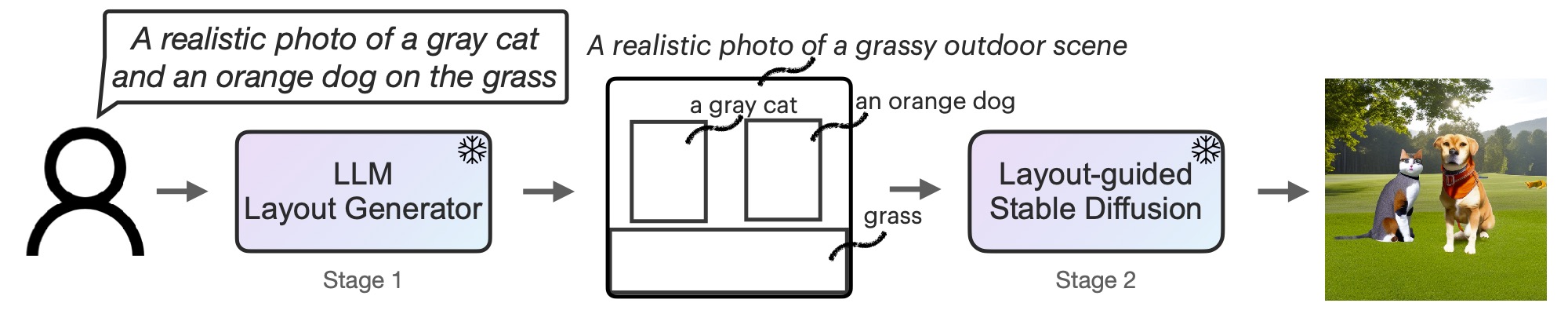
Determine 2: LMD is a text-to-image generative mannequin with a novel two-step generative course of. LLM + text-to-layout generator with in-context studying and secure diffusion primarily based on new layouts. No coaching is required for both stage.
Further options of LMD
Moreover, LMD naturally Dialogue-based multi-round scene specification, which permits for added clarification and subsequent modification of every immediate. Moreover, LMD can: Deal with prompts in languages that aren’t properly supported by the underlying diffusion mannequin.

Determine 3: By incorporating LLM for fast comprehension, our technique can interpret dialogue-based scene specs and prompts in languages that the underlying diffusion mannequin doesn’t help (Chinese language within the instance above). era will be carried out.
If in case you have an LLM that helps multi-round dialogs (corresponding to GPT-3.5 or GPT-4), LMD permits customers to question the LLM after preliminary format era within the dialog and supply extra data or explanations to the LLM. and generate photos. Format up to date with subsequent responses from LLM. For instance, a person can request so as to add an object to the scene or change the place or description of an current object (left half of Determine 3).
Moreover, by giving an instance of a non-English immediate with an English format and background description throughout in-context studying, the LMD will settle for enter for the non-English immediate and create a format with subsequent containers and background descriptions in English. will generate. Generate format to picture. As proven in the proper half of Determine 3, this enables era from prompts in languages that the underlying diffusion mannequin doesn’t help.
Visualization
We confirm the prevalence of our design by evaluating it to the essential diffusion mannequin (SD 2.1) used internally by LMD. We invite readers to our work for additional analysis and comparability.
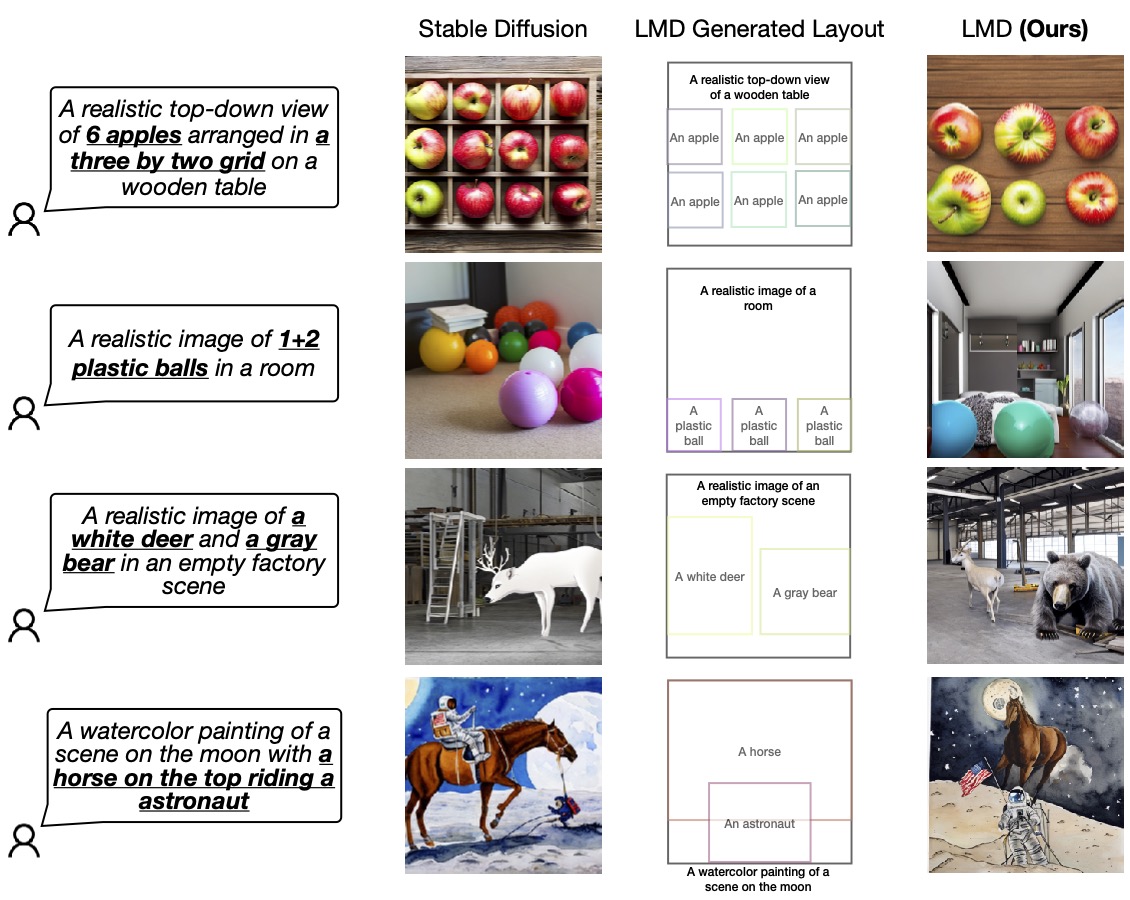
Determine 4: LMD outperforms primary diffusion fashions in precisely producing photos following prompts that require each verbal and spatial reasoning. LMD additionally permits counterfactual text-to-image era, which the essential diffusion mannequin can not generate (final row).
For extra data on LLM Floor Diffusion (LMD), Visit our website and Read the paper on arXiv.
bibtex
If LLM-based diffusion has impressed your work, please cite it as follows:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Immediate Understanding of Textual content-to-Picture Diffusion Fashions with Giant Language Fashions},
writer={Lian, Lengthy and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
12 months={2023}
}

{kind=link}