


An introduction to the do’s and don’ts when implementing a non-english Retrieval Augmented Technology (RAG) system
TLDR
This text offers an introduction to the concerns one ought to bear in mind when growing non-English RAG programs, full with particular examples and methods. A number of the key factors embody:
- Prioritize sustaining syntactic construction throughout information loading, as it’s essential for significant textual content segmentation.
- Format paperwork utilizing easy delimiters like nn to facilitate environment friendly textual content splitting.
- Go for rule-based textual content splitters, given the computational depth and subpar efficiency of ML-based semantic splitters in multilingual contexts.
- In choosing an embedding mannequin, think about each its multilingual capabilities and uneven retrieval efficiency.
- For multilingual initiatives, fine-tuning an embedding mannequin with a Massive Language Mannequin (LLM) can improve efficiency, and could also be wanted to attain adequate accuracy.
- Implementing an LLM-based retrieval analysis benchmark is strongly really helpful to fine-tune the hyperparameters of your RAG system successfully, and may be finished simply with present frameworks.
It’s no marvel that RAG has turn into the trendiest time period inside search know-how in 2023. Retrieval Augmented Technology (RAG) is reworking how organizations make the most of their huge amount of present information to energy clever ChatBots. These bots, able to conversations in pure language, can draw on a company’s collective information to operate as an always-available, in-house knowledgeable to ship related solutions, grounded in verified information. Whereas a substantial variety of assets can be found on constructing RAG programs, most are geared towards the English language, leaving a spot for smaller languages.
This 6-step easy-to-follow information will stroll you thru the do’s and don’ts when creating RAG programs for non-English languages.
RAG construction, a short recap
This text presumes familiarity with ideas like embeddings, vectors, and tokens. For these needing a short refresher on the structure of RAG programs, they primarily include two core elements:
- Indexing part (the main target of this text): This preliminary stage includes processing the enter information. The information is first loaded, appropriately formatted, then cut up. Later, it undergoes vectorization by embedding methods, culminating in its storage inside a information base for future retrieval.
- Generative part: On this part, a person’s question is enter to the retrieval system. This technique then extracts related data snippets from the information base. Leveraging a Massive Language Mannequin (LLM), the system interprets this information to formulate a coherent, pure language response, successfully addressing the person’s inquiry.
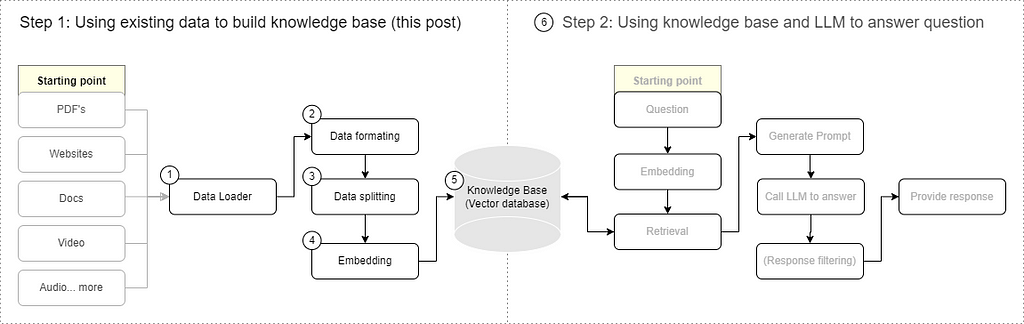
Now let’s get began!
Disclaimer:
This information doesn’t purpose to be an exhaustive guide on utilizing any specific software. As a substitute, its objective is to make clear the overarching selections that ought to information your software choice. In follow, I strongly advocate leveraging a longtime framework for setting up your system’s basis. For constructing RAG programs, I might personally advocate LlamaIndex as they supply detailed guides and options centered strictly on indexing and retrieval optimization.
Moreover, this information is written with the idea that we’re coping with languages that use the latin script and browse from left to proper. This consists of languages like German, French, Spanish, Czech, , Turkish, Vietnamese, Norwegian, Polish, and fairly a number of others. Languages outdoors of this group could have completely different wants and concerns.
1. Information loader: The satan’s within the particulars

Step one in a RAG system includes utilizing a dataloader to deal with numerous codecs, from textual content paperwork to multimedia, extracting all related content material for additional processing. For text-based codecs, dataloaders usually carry out constantly throughout languages, as they don’t contain language-specific processing. With the appearance of multi-modal RAG programs, it’s nonetheless essential to pay attention to the lowered efficiency of speech to textual content fashions in comparison with their English counterparts. Fashions like Whisper v3 reveal spectacular multilingual capabilities, but it surely’s sensible to take a look at their efficiency on benchmarks like Mozilla Common Voice or the Fleurs dataset, and ideally consider these by yourself benchmark.
For the rest of this text, we’ll nonetheless consider text-based inputs.
Why retaining syntactic construction is essential
A key side of information loading is to protect the unique information’s syntactic integrity. The lack of parts similar to headers or paragraph constructions can impression the accuracy of subsequent data retrieval. This concern is heightened for non-English languages as a result of restricted availability of machine learning-based segmentation instruments.
Syntactic data performs an important position as a result of the effectiveness of RAG programs in delivering significant solutions relies upon partly on their potential to separate information into semantically correct subsections.
To spotlight the variations between an information loading method that retains the construction and one that doesn’t, let’s take the instance of utilizing a fundamental HTML dataloader versus a PDF loader on a medium article. Libraries similar to LangChain and LlamaIndex each depend on the very same libraries, however simply wrap the features in their very own doc courses (Requests+BS4 for net, PyPDF2 for PDFs).
HTML Dataloader: This technique retains the syntactic construction of the content material.
import requests
from bs4 import BeautifulSoup
url = "https://medium.com/llamaindex-blog/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83"
soup = BeautifulSoup(requests.get(url).textual content, 'html.parser')
filtered_tags = soup.find_all(['h1', 'h2', 'h3', 'h4', 'p'])
filtered_tags[:14]
<p class="be b dw dx dy dz ea eb ec ed ee ef dt"><span><a category="be b dw dx eg dy dz eh ea eb ei ec ed ej ee ef ek el em eo ep eq er es et eu ev ew ex ey ez fa bl fb fc" data-testid="headerSignUpButton" href="https://medium.com/m/signin?operation=register&redirect=httpspercent3Apercent2Fpercent2Fblog.llamaindex.aipercent2Fboosting-rag-picking-the-best-embedding-reranker-models-42d079022e83&supply=post_page---two_column_layout_nav-----------------------global_nav-----------" rel="noopener comply with">Join</a></span></p>
<p class="be b dw dx dy dz ea eb ec ed ee ef dt"><span><a category="af ag ah ai aj ak al am an ao ap aq ar as at" data-testid="headerSignInButton" href="https://medium.com/m/signin?operation=login&redirect=httpspercent3Apercent2Fpercent2Fblog.llamaindex.aipercent2Fboosting-rag-picking-the-best-embedding-reranker-models-42d079022e83&supply=post_page---two_column_layout_nav-----------------------global_nav-----------" rel="noopener comply with">Register</a></span></p>
<p class="be b dw dx dy dz ea eb ec ed ee ef dt"><span><a category="be b dw dx eg dy dz eh ea eb ei ec ed ej ee ef ek el em eo ep eq er es et eu ev ew ex ey ez fa bl fb fc" data-testid="headerSignUpButton" href="https://medium.com/m/signin?operation=register&redirect=httpspercent3Apercent2Fpercent2Fblog.llamaindex.aipercent2Fboosting-rag-picking-the-best-embedding-reranker-models-42d079022e83&supply=post_page---two_column_layout_nav-----------------------global_nav-----------" rel="noopener comply with">Join</a></span></p>
<p class="be b dw dx dy dz ea eb ec ed ee ef dt"><span><a category="af ag ah ai aj ak al am an ao ap aq ar as at" data-testid="headerSignInButton" href="https://medium.com/m/signin?operation=login&redirect=httpspercent3Apercent2Fpercent2Fblog.llamaindex.aipercent2Fboosting-rag-picking-the-best-embedding-reranker-models-42d079022e83&supply=post_page---two_column_layout_nav-----------------------global_nav-----------" rel="noopener comply with">Register</a></span></p>
<h1 class="pw-post-title gp gq gr be gs gt gu gv gw gx gy gz ha hb hc hd he hf hg hh hello hj hk hl hm hn ho hp hq hr bj" data-testid="storyTitle" id="f2a9">Boosting RAG: Choosing the Greatest Embedding & Reranker fashions</h1>
<p class="be b iq ir bj"><a category="af ag ah ai aj ak al am an ao ap aq ar is" data-testid="authorName" href="https://ravidesetty.medium.com/?supply=post_page-----42d079022e83--------------------------------" rel="noopener comply with">Ravi Theja</a></p>
<p class="be b iq ir dt"><span><a category="iv iw ah ai aj ak al am an ao ap aq ar eu ix iy" href="https://medium.com/m/signin?actionUrl=httpspercent3Apercent2Fpercent2Fmedium.compercent2F_percent2Fsubscribepercent2Fuserpercent2F60738cbbc7df&operation=register&redirect=httpspercent3Apercent2Fpercent2Fblog.llamaindex.aipercent2Fboosting-rag-picking-the-best-embedding-reranker-models-42d079022e83&person=Ravi+Theja&userId=60738cbbc7df&supply=post_page-60738cbbc7df----42d079022e83---------------------post_header-----------" rel="noopener comply with">Comply with</a></span></p>
<p class="be b bf z jh ji jj jk jl jm jn jo bj">LlamaIndex Weblog</p>
<p class="be b du z dt"><span class="lq">--</span></p>
<p class="be b du z dt"><span class="pw-responses-count lr ls">5</span></p>
<p class="be b bf z dt">Hear</p>
<p class="be b bf z dt">Share</p>
<p class="pw-post-body-paragraph nl nm gr nn b no np nq nr ns nt nu nv nw nx ny nz oa ob oc od oe of og oh oi gk bj" id="4130"><sturdy class="nn gs">UPDATE</sturdy>: The pooling technique for the Jina AI embeddings has been adjusted to make use of imply pooling, and the outcomes have been up to date accordingly. Notably, the <code class="cw oj okay ol om b">JinaAI-v2-base-en</code> with <code class="cw oj okay ol om b">bge-reranker-large</code>now reveals a Hit Price of 0.938202 and an MRR (Imply Reciprocal Rank) of 0.868539 and with<code class="cw oj okay ol om b">CohereRerank</code> reveals a Hit Price of 0.932584, and an MRR of 0.873689.</p>
<p class="pw-post-body-paragraph nl nm gr nn b no np nq nr ns nt nu nv nw nx ny nz oa ob oc od oe of og oh oi gk bj" id="8267">When constructing a Retrieval Augmented Technology (RAG) pipeline, one key part is the Retriever. We now have quite a lot of embedding fashions to select from, together with OpenAI, CohereAI, and open-source sentence transformers. Moreover, there are a number of rerankers accessible from CohereAI and sentence transformers.</p>
PDF information loader, instance during which syntactic data is misplaced (saved article as PDF, then re-loaded)
from PyPDF2 import PdfFileReader
pdf = PdfFileReader(open('information/Boosting_RAG_Picking_the_Best_Embedding_&_Reranker_models.pdf','rb'))
pdf.getPage(0).extractText()
'Boosting RAG: Choosing the BestnEmbedding & Reranker modelsn
Ravi Theja·FollownPublished inLlamaIndex Weblog·7 min learn·Nov 3n
389 5nUPDATE: The pooling technique for the Jina AI embeddings has been adjustedn
to make use of imply pooling, and the outcomes have been up to date accordingly.n
Notably, the JinaAI-v2-base-en with bge-reranker-largenow reveals a Hitn
Price of 0.938202 and an MRR (Imply Reciprocal Rank) of 0.868539 andn
withCohereRerank reveals a Hit Price of 0.932584, and an MRR of 0.873689.n
When constructing a Retrieval Augmented Technology (RAG) pipeline, one keyn
part is the Retriever. We now have quite a lot of embedding fashions ton
select from, together with OpenAI, CohereAI, and open-source sentencen
Open in appnSearch Writen'
Upon preliminary overview, the PDF dataloader’s output seems extra readable, however nearer inspection reveals a lack of structural data — how would one inform what’s a header, and the place a bit ends? In distinction, the HTML file retains all of the related construction.
Ideally, you wish to retain all unique formatting within the information loader, and solely resolve on filtering and reformatting within the subsequent step. Nevertheless, that may contain constructing customized information loaders in your use case, and in some circumstances be inconceivable. I like to recommend to easily begin with an ordinary information loader, however spend a couple of minutes to examine examples of the loaded information rigorously and perceive what construction has been misplaced.
Understanding what syntactic that’s misplaced is essential, because it guides potential enhancements if the system’s downstream retrieval efficiency wants enhancement, permitting for focused refinements.
2. Information formatting: Boring… however essential

The second step, formatting, serves the first objective of uniforming the info out of your information loaders in a means that prepares the info for the subsequent step of textual content splitting. As the next part explains, dividing the enter textual content right into a myriad of smaller chunks might be essential. A profitable formatting units up the textual content in a means that gives the absolute best circumstances for dividing the content material into semantically significant chunks. Merely put, your aim is to rework the possibly advanced syntactic construction retrieved from a html or a markdown file, right into a plain textual content file with fundamental delimiters similar to /n (line change) and /n/n (finish of part) to information the textual content splitter.
A easy operate to format the BS4 HTML object right into a dictionary with title and textual content might seem like the under:
def format_html(tags):
formatted_text = ""
title = ""
for tag in tags:
if 'pw-post-title' in tag.get('class', []):
title = tag.get_text()
elif tag.identify == 'p' and 'pw-post-body-paragraph' in tag.get('class', []):
formatted_text += "n"+ tag.get_text()
elif tag.identify in ['h1', 'h2', 'h3', 'h4']:
formatted_text += "nn" + tag.get_text()
return {title: formatted_text}
formatted_document = format_html(filtered_tags)
{'Boosting RAG: Choosing the Greatest Embedding & Reranker fashions': "n
UPDATE: The pooling technique for the Jina AI embeddings has been adjusted to make use of imply pooling, and the outcomes have been up to date accordingly. Notably, the JinaAI-v2-base-en with bge-reranker-largenow reveals a Hit Price of 0.938202 and an MRR (Imply Reciprocal Rank) of 0.868539 and withCohereRerank reveals a Hit Price of 0.932584, and an MRR of 0.873689.n
When constructing a Retrieval Augmented Technology (RAG) pipeline, one key part is the Retriever. We now have quite a lot of embedding fashions to select from, together with OpenAI, CohereAI, and open-source sentence transformers. Moreover, there are a number of rerankers accessible from CohereAI and sentence transformers.n
However with all these choices, how will we decide one of the best combine for top-notch retrieval efficiency? How do we all know which embedding mannequin suits our information finest? Or which reranker boosts our outcomes probably the most?n
On this weblog submit, we’ll use the Retrieval Analysis module from LlamaIndex to swiftly decide one of the best mixture of embedding and reranker fashions. Let's dive in!n
Let’s first begin with understanding the metrics accessible in Retrieval Evaluationnn
... }
For advanced RAG programs the place there could be a number of right solutions relative to the context, storing extra data like doc titles or headers as metadata alongside the textual content chunks is useful. This metadata can be utilized later for filtering, and if accessible, formatting parts like headers ought to affect your chunking technique. A library like LlamaIndex natively work with the idea of metadata and textual content wrapped collectively in Node objects, and I extremely advocate utilizing this or an analogous framework
Now that we’ve finished our formatting appropriately, let’s dive into the important thing points of textual content splitting!
3: Textual content splitting: Dimension issues

When making ready information for embedding and retrieval in a RAG system, splitting the textual content into appropriately sized chunks is essential. This course of is guided by two primary elements, Mannequin Constraints and Retrieval Effectiveness.
Mannequin Constraints
Embedding fashions have a most token size for enter; something past this restrict will get truncated. Pay attention to your chosen mannequin’s limitations and be sure that every information chunk doesn’t exceed this max token size.
Multilingual fashions, particularly, typically have shorter sequence limits in comparison with their English counterparts. As an illustration, the broadly used Paraphrase multilingual MiniLM-L12 v2 mannequin has a most context window of simply 128 tokens.
Additionally, think about the textual content size the mannequin was educated on — some fashions would possibly technically settle for longer inputs however had been educated on shorter chunks, which might have an effect on efficiency on longer texts. One such is instance, is the Multi QA base from SBERT as seen under,

Retrieval effectiveness
Whereas chunking information to the mannequin’s most size appears logical, it may not at all times result in one of the best retrieval outcomes. Bigger chunks supply extra context for the LLM however can obscure key particulars, making it more durable to retrieve exact matches. Conversely, smaller chunks can improve match accuracy however would possibly lack the context wanted for full solutions. Hybrid approaches use smaller chunks for search however embody surrounding context at question time for stability.
Whereas there isn’t a definitive reply relating to chunk measurement, the concerns for chunk measurement stay constant whether or not you’re engaged on multilingual or English initiatives. I might advocate studying additional on the subject from assets similar to Evaluating the Ideal Chunk Size for RAG System using Llamaindex or Building RAG-based LLM Applications for Production.
Textual content splitting: Strategies for splitting textual content
Textual content may be cut up utilizing numerous strategies, primarily falling into two classes: rule-based (specializing in character evaluation) and machine learning-based fashions. ML approaches, from easy NLTK & Spacy tokenizers to superior transformer fashions, typically rely upon language-specific coaching, primarily in English. Though easy fashions like NLTK & Spacy help a number of languages, they primarily tackle sentence splitting, not semantic sectioning.
Since ML primarily based sentence splitters at present work poorly for many non-English languages, and are compute intensive, I like to recommend beginning with a easy rule-based splitter. In the event you’ve preserved related syntactic construction from the unique information, and formatted the info appropriately, the end result might be of excellent high quality.
A standard and efficient technique is a recursive character textual content splitter, like these utilized in LangChain or LlamaIndex, which shortens sections by discovering the closest cut up character in a prioritized sequence (e.g., nn, n, ., ?, !).
Taking the formatted textual content from the earlier part, an instance of utilizing LangChains recursive character splitter would look like:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("intfloat/e5-base-v2")
def token_length_function(text_input):
return len(tokenizer.encode(text_input, add_special_tokens=False))
text_splitter = RecursiveCharacterTextSplitter(
# Set a very small chunk measurement, simply to point out.
chunk_size = 128,
chunk_overlap = 0,
length_function = token_length_function,
separators = ["nn", "n", ". ", "? ", "! "]
)
split_texts = text_splitter(formatted_document['Boosting RAG: Picking the Best Embedding & Reranker models'])
Right here it’s essential to notice that one ought to outline the tokenizer because the embedding mannequin supposed to make use of, since completely different fashions ‘depend’ the phrases in a different way. The operate will now, in a prioritized order, cut up any textual content longer than 128 tokens first by the nn we launched at finish of sections, and if that isn’t potential, then by finish of paragraphs delimited by n and so forth. The primary 3 chunks will be:
Token of textual content: 111
UPDATE: The pooling technique for the Jina AI embeddings has been adjusted to make use of imply pooling, and the outcomes have been up to date accordingly. Notably, the JinaAI-v2-base-en with bge-reranker-largenow reveals a Hit Price of 0.938202 and an MRR (Imply Reciprocal Rank) of 0.868539 and withCohereRerank reveals a Hit Price of 0.932584, and an MRR of 0.873689.
-----------
Token of textual content: 112
When constructing a Retrieval Augmented Technology (RAG) pipeline, one key part is the Retriever. We now have quite a lot of embedding fashions to select from, together with OpenAI, CohereAI, and open-source sentence transformers. Moreover, there are a number of rerankers accessible from CohereAI and sentence transformers.
However with all these choices, how will we decide one of the best combine for top-notch retrieval efficiency? How do we all know which embedding mannequin suits our information finest? Or which reranker boosts our outcomes probably the most?
-----------
Token of textual content: 54
On this weblog submit, we’ll use the Retrieval Analysis module from LlamaIndex to swiftly decide one of the best mixture of embedding and reranker fashions. Let's dive in!
Let’s first begin with understanding the metrics accessible in Retrieval Analysis
Now that we have now efficiently cut up the textual content in a semantically significant means, we will transfer onto the ultimate a part of embedding these chunks for storage.
4. Embedding Fashions: Navigating the jungle

Choosing the proper embedding mannequin is important for the success of a Retrieval Augmented Technology (RAG) system, and one thing that’s much less straight ahead than for the English language. A complete useful resource for evaluating fashions is the Massive Text Embedding Benchmark (MTEB), which incorporates benchmarks for over 100 languages.
The mannequin of your selection should both be multilingual or particularly tailor-made to the language you’re working with (monolingual). Keep in mind, the most recent high-performing fashions are sometimes English-centric and will not work nicely with different languages.
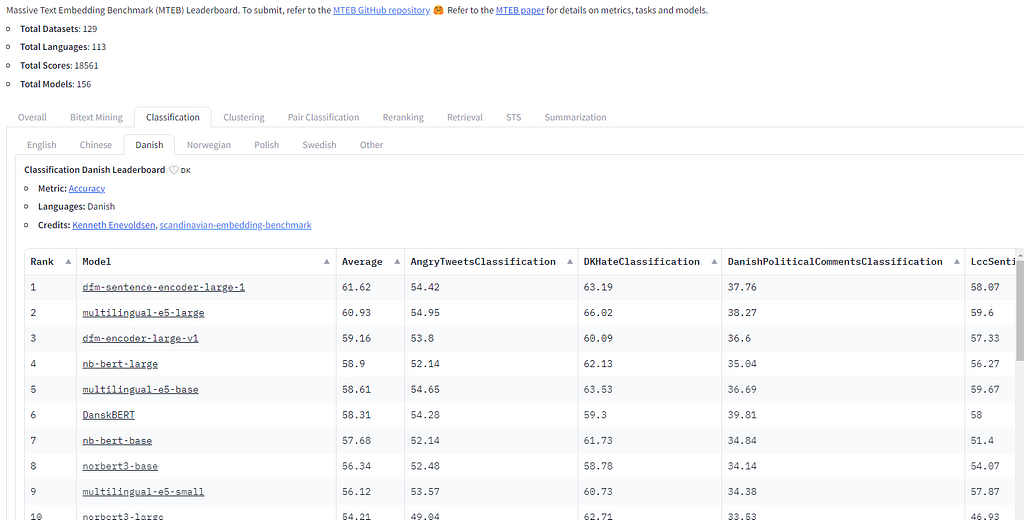
If accessible, seek advice from language-specific benchmarks related to your activity. As an illustration, in classification duties, there are over 50 language-specific benchmarks, aiding in choosing probably the most environment friendly mannequin for languages starting from Danish to Spanish. Nevertheless, it’s essential to notice that these benchmarks could circuitously point out a mannequin’s effectivity in retrieving related data for a RAG system, as a result of retrieval is completely different from classification, clustering or one other activity. The duty is to search out fashions educated for uneven search, as these not educated for this particular activity would possibly inaccurately prioritize shorter passages over longer, extra related ones.
The mannequin ought to excel in asymmetric retrieval, matching brief queries to longer textual content chunks. The explanation why is that, in a RAG system, you typically match a short question to extra intensive passages to extract significant solutions. The MTEB benchmarks associated to uneven search are listed below the Retrieval. A problem is that as of November 2023, MTEB’s Retrieval benchmark consists of solely English, Chinese language, and Polish.
When coping with languages like Norwegian, the place there might not be particular retrieval benchmarks, you would possibly ponder whether to decide on the best-performing mannequin from classification benchmarks or a normal multilingual mannequin proficient in English retrieval?
As for sensible recommendation, a easy rule of thumb is to go for the top-performing multilingual mannequin within the MTEB Retrieval benchmark. Beware that the retrieval rating itself, is nonetheless nonetheless primarily based on English, so benchmarking by yourself language is required to qualify the efficiency (step 6). As of December 2023, the E5-multilingual household is a robust selection for an open supply mannequin. The mannequin is fine-tuned for uneven search, and by tagging texts as ‘question’ or ‘passage’ earlier than embedding, it optimizes the retrieval course of by contemplating the character of the enter. This method ensures a simpler match between queries and related data in your information base, enhancing the general efficiency of your RAG system. As seen on the benchmark, the cohere-embed-multilingual-v3.0 seemingly has higher efficiency, however needs to be paid for.
The step of embedding is usually finished as a part of storing the paperwork in a vector DB, however a easy instance of embedding all of the cut up sentences utilizing the E5 household may be finished as under utilizing the Sentence Transformer library.
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer('intfloat/e5-large')
prepended_split_texts = ["passage: " + text for text in split_texts]
embeddings = mannequin.encode(prepended_split_texts, normalize_embeddings=True)
print(f'We now have {len(embeddings)} embeddings, every of measurement {len(embeddings[0])}')
We now have 12 embeddings, every of measurement 1024
If off the shelf embeddings prove to not present adequate efficiency in your particular retrieval area, worry not. With the appearance of LLMs it has now turn into possible to auto-generate training-data out of your present corpus, and improve the efficiency of as much as 5–10% by fine-tuning an present embedding by yourself information, LlamaIndex provides a guide here or SBERTs GenQ approach the place primarily the Bi-Encoder coaching half is related.
5. Vector databases: The house of embeddings

After loading, formatting, splitting your information, and choosing an embedding mannequin, the subsequent step in your RAG system setup is to embed the info and retailer these vector embeddings for retrieval. Most platforms, together with LangChain and LlamaIndex, present built-in native storage options, utilizing vector databases like Qdrant, Milvus, Chroma DB or supply direct integration with cloud-based storage choices similar to Pinecone or ActiveLoop. The selection of vector storage is usually unaffected by whether or not your information is in English or one other language. For a complete understanding of storage and search choices, together with vector databases, I like to recommend exploring present assets, similar to this detailed introduction: All You Have to Know About Vector Databases and Easy methods to Use Them to Increase Your LLM Apps. This information will offer you the mandatory insights to successfully handle the storage side of your RAG system.
At this level, you might have efficiently created the information base that may function the mind of the retrieval system.

6. The generative part: Go learn elsewhere 😉
The second half of the RAG system, the generative part, is equally essential in guaranteeing a profitable resolution. Strictly talking, it’s a search optimization downside with a sprinkle of LLM on high, the place the concerns are much less language-dependent. Which means guides for English retrieval optimization are typically relevant to different languages as nicely, therefore it isn’t included right here.
In its easiest type, the generative part includes an easy course of: taking a person’s query, embedding it utilizing the chosen embedding mannequin from step 4, performing a vector similarity search within the newly created database, and eventually feeding the related textual content chunks to the LLM. This enables the system to reply to the question in pure language. Nevertheless, to attain a high-performing RAG system, a number of changes on the retrieval facet are essential similar to re-ranking, filtering and far more. For additional insights, I like to recommend exploring articles similar to 10 methods to enhance the efficiency of retrieval augmented era programs or Enhancing Retrieval efficiency in RAG pipelines with Hybrid Search
Outro: Evaluating your RAG system

So what do you do from right here, what’s the proper configuration in your actual downside, and language?
Because it could be clear at this level, deciding on the optimum settings in your RAG system could be a advanced activity as a result of quite a few variables concerned. A customized question & context benchmark is crucial to judge completely different configurations, particularly since a pre-existing benchmark in your particular multilingual dataset and use case may be very unlikely to exist.
Fortunately, with Massive Language Fashions (LLMs), making a tailor-made benchmark dataset has turn into possible. A benchmark for retrieval programs usually includes search queries and their corresponding context (the textual content chunks we cut up in step 4). If in case you have the uncooked information, LLMs can automate the era of fictional queries associated to your dataset. Tools like LlamaIndex provide built-in functions for this purpose. By producing customized queries, you possibly can systematically check how changes within the embedding mannequin, chunk measurement, or information formatting impression the retrieval efficiency in your particular situation.
Making a consultant analysis benchmark has a good quantity of do’s and dont’s concerned, and in early 2024 I’ll comply with up with a separate submit on the way to create a nicely performing retrieval benchmark — keep tuned!
Thanks for taking the time to learn this submit, I hope you might have discovered the article helpful.
Keep in mind to throw some 👏👏👏 if the content material was of assist, and be happy to succeed in out in case you have questions or feedback to the submit.
References:
- Evaluating the Ideal Chunk Size for RAG System using Llamaindex
- Building RAG-based LLM Applications for Production
- Easy methods to chunk textual content a comparative evaluation
- Massive Text Embedding Benchmark (MTEB)
- SBERT on Asymmetric retrieval
- Finetuning embeddings using LlamaIndex
- Finetuning embeddings using SBERTs GenQ approach
- All You Have to Know About Vector Databases and Easy methods to Use Them to Increase Your LLM Apps
- 10 methods to enhance the efficiency of retrieval augmented era programs
- Enhancing Retrieval efficiency in RAG pipelines with Hybrid Search
- Evaluating retrieval performance of RAG systems using LlamaIndex
Past English: Implementing a multilingual RAG resolution was initially printed in In direction of Information Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.

{kind=link}