


Amazon Bedrock powers generative AI for greater than 100,000 organizations worldwide—from startups to world enterprises throughout each trade. It gives the confirmed infrastructure and complete capabilities to confidently construct purposes and brokers that work in manufacturing with the pliability, enterprise safety, and confirmed scalability that you must innovate boldly and ship AI that drives actual enterprise impression. As organizations scale their generative AI purposes powered by Amazon Bedrock throughout a number of basis fashions and manufacturing workloads, proactive operational administration turns into key to sustaining innovation velocity.
As generative AI adoption grows throughout groups, organizations can profit from a purpose-built operational monitoring resolution that delivers: 1) proactive, multi-layer monitoring that anticipates quota enhance wants as adoption grows by monitoring utilization patterns and accelerates operational difficulty triage for generative AI workloads powered by Amazon Bedrock; 2) context-aware help case automation that accelerates imply time to decision by equipping AWS help engineers with the knowledge they want; 3) duplicate case prevention that suppresses new case creation when an unresolved case of the identical alarm class already exists, avoiding distraction from lively investigations; 4) contextualized notifications that empower AI SRE groups to behave rapidly; and 5) continued deal with innovation by lowering guide operational overhead.
On this put up, we introduce Amazon Bedrock Ops Alert, a three-layer automated monitoring resolution that proactively detects operational points, dynamically adjusts alarm thresholds, classifies alarms by class, mechanically creates context-aware help instances, helps stop duplicate instances when an unresolved case of the identical alarm class is already lively, and delivers contextualized notifications to AI SRE groups. We stroll by way of the answer structure and how one can deploy it in your personal surroundings.
Scaling operational maturity for generative AI workloads
Amazon Bedrock gives service quotas for requests per minute (RPM) and tokens per minute (TPM) to assist handle useful resource allocation throughout clients. These quotas might be elevated by way of AWS Help instances as workloads develop. A typical preliminary method makes use of third-party dashboarding options backed by Amazon CloudWatch metrics, mixed with guide processes to observe quota consumption and request will increase when wanted. This method serves groups effectively throughout early adoption.
As adoption grows, organizations typically uncover that workload optimization addresses capability wants extra successfully than quota will increase. Cross-region inference helps organizations handle unplanned site visitors bursts through the use of compute throughout completely different AWS Areas. When utilizing an inference profile tied to a particular geography, Amazon Bedrock mechanically selects the optimum business AWS Area inside that geography to course of the inference request. World cross-region inference extends this past geographic boundaries by routing inference requests to help business AWS Areas worldwide, optimizing out there sources and offering greater mannequin throughput. With world inference profiles, workloads are not constrained by particular person Regional capability, offering entry to a a lot bigger pool of sources and roughly 10% value financial savings in comparison with geographic cross-region inference. Within the put up Unlock world AI inference scalability utilizing new world cross-Area inference on Amazon Bedrock with Anthropic’s Claude Sonnet 4.5, we element how world inference profiles dynamically route requests throughout the AWS world infrastructure to soak up demand that may in any other case require quota will increase.
Immediate caching is an non-compulsory characteristic that reduces inference response latency and enter token prices. By including parts of the context to a cache, the mannequin skips recomputation of inputs, permitting Amazon Bedrock to share within the compute financial savings and decrease response latencies. Immediate caching helps when workloads have lengthy and repeated contexts which can be regularly reused for a number of queries, lowering prices by as much as 90% and latency by as much as 85%, which immediately lowers tokens-per-minute consumption. Within the put up Successfully use immediate caching on Amazon Bedrock, we stroll by way of tips on how to construction prompts to maximise cache hits throughout a number of API calls. Extra strategies corresponding to batch inference and Clever Immediate Routing additional cut back per-request overhead by dynamically choosing probably the most cost-effective mannequin for every name.
As organizations undertake these optimization methods and increase throughout a number of basis fashions and manufacturing workloads, AI SRE groups look to enhance them with automated operational monitoring to maintain innovation velocity and cut back imply time to decision. Particularly, groups generally establish 4 areas for enchancment:
- Reactive operations: AI SRE groups typically study of operational points solely when enterprise customers report impression. This forces the crew to function reactively, with restricted time to analyze and reply earlier than the impression escalates.
- Alternative for case context enrichment: When quota points come up, help instances can profit from richer context, distinguishing easy quota will increase from points requiring deeper investigation, to assist help engineers resolve instances quicker.
- Multiplying operational effort: As organizations undertake new basis fashions for various use instances, every new mannequin requires its personal monitoring setup and quota enhance requests. This undifferentiated heavy lifting grows linearly with the mannequin portfolio.
- Shifting goal for alarm thresholds: Every authorised quota enhance requires the AI SRE crew to manually recalculate and replace CloudWatch alarm thresholds, creating operational overhead and the danger of configuration drift.
Answer overview
Amazon Bedrock Ops Alert is an AWS CloudFormation-based resolution that implements complete generative AI observability by way of three complementary detection layers. Every layer gives completely different visibility into generative AI workloads, from speedy operational difficulty detection to predictive anomaly identification.
The answer makes use of Amazon CloudWatch alarms, AWS Lambda capabilities, Amazon Easy Notification Service (Amazon SNS), the Service Quotas API, and AWS Help API.
The next diagram illustrates the answer structure.
The workflow steps are as follows:
- Throughout deployment, a Lambda perform (Quota Calculator) queries the Service Quotas API for present RPM and TPM quota values and calculates alarm thresholds by making use of configured percentages.
- The calculated thresholds are saved in AWS Methods Supervisor Parameter Retailer, and AI SRE crew electronic mail contacts are saved in AWS Secrets and techniques Supervisor.
- Amazon Bedrock publishes runtime metrics (invocations, token counts, errors, throttles, and latency) to CloudWatch. Three unbiased monitoring layers consider these metrics:
- Layer 1 (Vital Error Detection) displays throttles, shopper errors, and server errors for speedy alerting.
- Layer 2 (Utilization Charge Monitoring) compares RPM, TPM, and latency towards the dynamically calculated thresholds.
- Layer 3 (Anomaly Detection) makes use of CloudWatch machine studying to establish uncommon patterns throughout metrics.
- When a baby alarm triggers, a composite alarm aggregates the state.
- The composite alarm publishes to an SNS matter (Uncooked Alarm Subject).
- The SNS matter invokes a Lambda notification processor perform, which polls the composite alarm to establish which baby alarms triggered and determines alarm severity (vital or warning).
- The notification processor queries the Service Quotas API for present RPM and TPM quota values.
- The notification processor queries CloudWatch for present utilization metrics, together with steady-state and peak RPM/TPM over the previous 14 days and common tokens per request. It additionally reads saved alarm thresholds from Parameter Retailer and compares peak utilization towards thresholds to find out the help case state of affairs.
- If automated help case creation is enabled, the perform classifies the alarm as quota-related or non-quota, checks for present unresolved instances utilizing category-aware duplicate detection (configurable lookback window, default 60 days), and both appends a communication to the prevailing case or creates a brand new AWS Help case. For quota-related alarms, the case consists of pre-filled quota knowledge with usage-validated content material. For non-quota alarm (corresponding to persistent errors or latency anomalies), offering context to help with root trigger evaluation.
- After help case processing completes, the perform sends formatted electronic mail notifications to stakeholders by way of a second SNS matter (Formatted Notification Subject), filtered by notification choice (all, vital, or warning). If a help case was created, the e-mail consists of the case ID and a direct hyperlink to the AWS Help console.
- The formatted notification is delivered as electronic mail to subscribed stakeholders.
- On a configurable schedule, an Amazon EventBridge rule triggers a Lambda perform (Alarm Updater).
- The Alarm Updater queries the Service Quotas API for present RPM and TPM quota values.
- The Alarm Updater recalculates alarm thresholds by making use of configured percentages, and updates CloudWatch alarms with new thresholds.
- The up to date thresholds are saved in Parameter Retailer with timestamps for monitoring historical past.
Three-layer monitoring structure
The answer implements three monitoring layers utilizing CloudWatch alarms that work independently to detect operational points at completely different levels.
Layer 1: Vital error detection
The primary layer displays error metrics that point out operational points:
- ClientErrors alarm: Screens the InvocationClientErrors metric to establish requests rejected resulting from client-side points corresponding to exceeded quota limits, validation errors, or invalid parameters.
- ServerErrors alarm: Screens the InvocationServerErrors metric to establish service-side errors which will require investigation.
- Throttles alarm: Screens the InvocationThrottles metric to establish requests explicitly throttled when the speed restrict is reached.
These alarms use configurable thresholds and analysis durations. Setting the error threshold to 0 with a single analysis interval triggers speedy alerts when an error happens, whereas greater values present tolerance for transient points.
Layer 2: Utilization charge monitoring
The second layer displays utilization metrics towards dynamically calculated thresholds, offering proactive alerts earlier than reaching your quota restrict:
- HighInvocationRate alarm: Screens the Invocations metric and triggers when the API request charge breaches the configured RPM threshold share of your quota.
- HighTPMQuotaUsage alarm: Screens the EstimatedTPMQuotaUsage metric and triggers when estimated tokens per minute quota consumption breaches the configured TPM threshold share of your quota (consists of cache write tokens and output burndown multipliers).
- HighLatency alarm: Screens the InvocationLatency metric and triggers when response time breaches the configured latency threshold.
The answer mechanically calculates alarm thresholds by querying the Service Quotas API and making use of configurable percentages. For instance, with an 80% threshold and a 100 RPM quota, the RPM alarm triggers at 80 requests per minute. For TPM, the identical 80% threshold on a 1,000,000 TPM quota provides an 800,000 efficient tokens threshold. The TPM alarm makes use of the EstimatedTPMQuotaUsage metric that tracks estimated TPM quota consumption, together with cache write tokens and output burndown multipliers.
Layer 3: Anomaly detection
The third layer makes use of CloudWatch anomaly detection as the brink sort to establish uncommon patterns throughout metrics:
- InvocationAnomaly alarm: Screens the Invocations metric utilizing anomaly detection to establish uncommon request quantity adjustments.
- InputTokenAnomaly alarm: Screens the InputTokenCount metric utilizing anomaly detection to establish irregular enter token utilization.
- OutputTokenAnomaly alarm: Screens the OutputTokenCount metric utilizing anomaly detection to establish irregular output token utilization.
- LatencyAnomaly alarm: Screens the InvocationLatency metric utilizing anomaly detection to establish efficiency degradation traits.
CloudWatch machine studying analyzes historic knowledge to ascertain regular conduct baselines, then alerts when present metrics exceed the higher threshold of the anticipated vary. The answer displays solely upward deviations: utilization drops are optimistic alerts that don’t require intervention. This method detects points that static thresholds miss, corresponding to gradual quota consumption will increase or sudden utilization surges.
Automated threshold administration
The answer dynamically adapts to quota adjustments by way of automated threshold recalculation:
- Preliminary calculation: Throughout deployment, a Lambda perform queries the Service Quotas API and calculates alarm thresholds based mostly on present quotas and configured percentages.
- Scheduled updates: An EventBridge rule triggers threshold recalculation on a configurable schedule (default: each 1 day).
- Computerized alarm updates: When authorised quota will increase change the quota values, the answer updates CloudWatch alarms with new thresholds.
- Threshold historical past: Calculated thresholds are saved in Parameter Retailer, a functionality of AWS Methods Supervisor, with timestamps.
This automation alleviates guide threshold upkeep when additional quota enhance requests are authorised. AI SRE groups not want to trace quota adjustments and manually replace alarm configurations: the system self-corrects.
The next desk describes how alarm thresholds are derived from Service Quotas values.
| Threshold | Formulation | Instance |
| RPM threshold | RPM quota × (RequestsPerMinuteThresholdPercent / 100) | 10,000 RPM quota × 80% = 8,000 |
| TPM threshold | TPM quota × (TokensPerMinuteThresholdPercent / 100) | 6,250,000 TPM quota × 80% = 5,000,000 |
The TPM threshold share is utilized on to the TPM quota. The utilization validation compares 14-day peak TPM towards this threshold when figuring out the help case state of affairs.
Automated help case creation
The answer optionally automates AWS Help case creation when operational points are detected. This characteristic requires an AWS Enterprise or Enterprise Help plan for Help API entry.
The workflow operates as follows:
- The composite alarm triggers when a baby alarm enters ALARM state.
- A Lambda perform polls the composite alarm standing, checking for eligible baby alarms.
- The perform reads saved alarm thresholds from Parameter Retailer and compares 14-day peak utilization towards thresholds to find out the help case state of affairs.
- The perform classifies the alarm as quota-related or non-quota and checks the Help API for present unresolved instances utilizing category-aware duplicate detection (configurable lookback window, default 60 days).
- If an unresolved case of the identical class exists, the system appends a communication to the prevailing case with full alarm particulars, up to date metrics, and urgency context. If no duplicate exists, the system creates a brand new help case with scenario-appropriate content material, both a quota enhance request with usage-validated particulars, or a service investigation request with out quota particulars.
The system classifies alarms into two classes and determines the suitable response.
Quota-related alarms set off a “Quota Request” help case with usage-validated content material:
- RPM-specific alarms (HighInvocationRate, InvocationAnomaly) request an RPM quota enhance solely.
- TPM-specific alarms (HighTPMQuotaUsage, InputTokenAnomaly, OutputTokenAnomaly) request a TPM quota enhance solely.
- Undetermined quota alarms (Throttles, ClientErrors) request each RPM and TPM quota will increase, offering context to assist establish which restrict was reached.
Non-quota alarms (ServerErrors, HighLatency, LatencyAnomaly) set off an “Investigation Request” help case offering alarm context and utilization knowledge to help with root trigger evaluation, with out quota enhance particulars.
The next desk summarizes the alarm classification and quota routing.
| Classification | Alarms | Case Sort | Quota Requested |
| RPM-specific alarms | HighInvocationRate, InvocationAnomaly | Quota Request | RPM quota enhance solely |
| TPM-specific alarms | HighTPMQuotaUsage, InputTokenAnomaly, OutputTokenAnomaly | Quota Request | TPM quota enhance solely |
| Undetermined quota alarms | Throttles, ClientErrors | Quota Request | Each RPM and TPM quota will increase |
| Non-quota alarms | ServerErrors, HighLatency, LatencyAnomaly | Investigation Request | No quota enhance requested |
Utilization-validated state of affairs resolution tree
Earlier than making a quota-related help case, the answer compares 14-day peak utilization metrics towards saved alarm thresholds to find out the suitable response. This utilization validation makes positive that help instances embrace the correct context and tone for the help engineer.
The next diagram illustrates the state of affairs resolution tree.
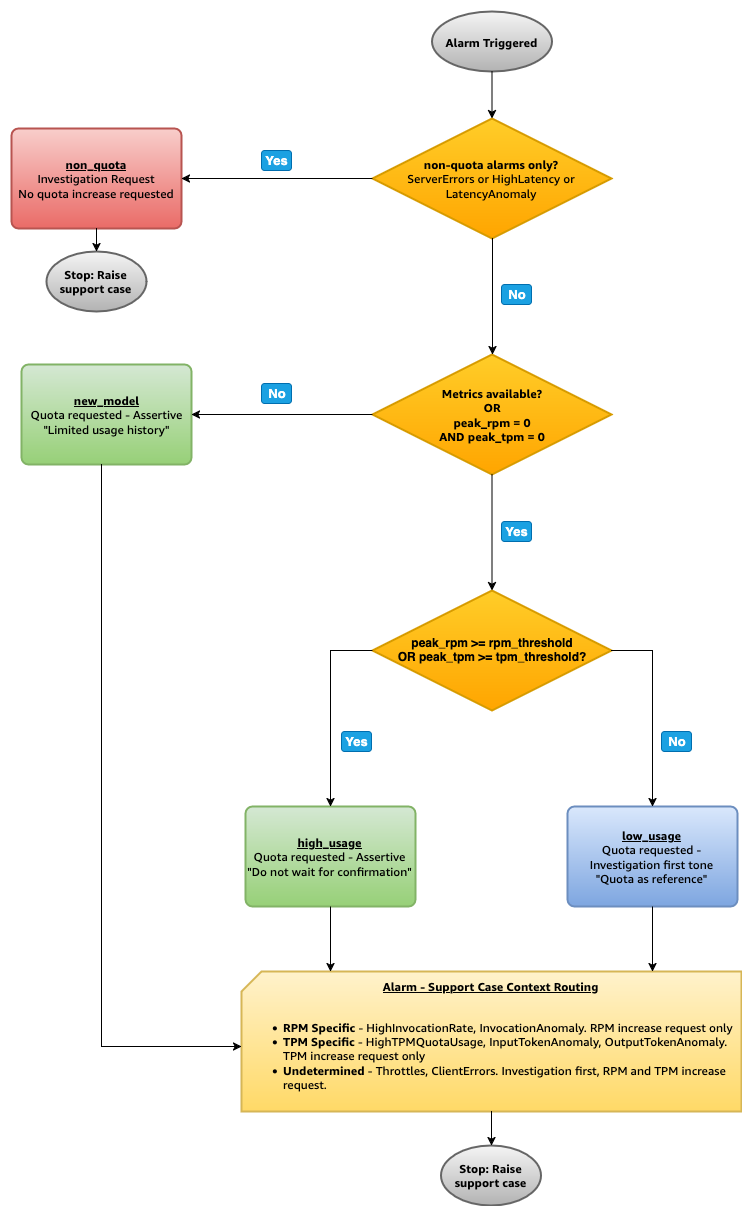
Utilization-validated state of affairs particulars
The next sections describe every state of affairs intimately, together with the set off situations, help case content material, and examples.
Non-quota: ServerErrors, HighLatency, or LatencyAnomaly triggered, and no different alarm varieties. No quota enhance particulars included. The case gives the help engineer with alarm context, utilization metrics, and triggering situations to help with root trigger evaluation.
| Discipline | Element |
| Case sort | Investigation Request |
| Alarms | ServerErrors-Vital (InvocationServerErrors), HighLatency-Warning (InvocationLatency), LatencyAnomaly-Warning (InvocationLatency) |
| Quota requested | No quota enhance requested |
| Rationale | These alarms point out server error corresponding to 5xx errors or latency degradation, not quota limits |
Examples
ServerErrors alarm triggered:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-ServerErrors-Vital-{ModelName} |
| Metric | InvocationServerErrors (Sum per minute) |
| Severity | CRITICAL |
| Choice | Triggered alarms are non-quota → non_quota (utilization metrics not evaluated) |
| Consequence | Investigation Request with no quota enhance particulars |
New mannequin: A quota-related alarm triggered, however the mannequin has zero utilization historical past (peak RPM = 0, peak TPM = 0) or metrics and thresholds couldn’t be retrieved. The help case bypasses the utilization guard and consists of quota enhance particulars, noting the mannequin is newly deployed with restricted utilization historical past. The case notes that the mannequin is newly deployed with restricted utilization historical past and consists of quota enhance particulars for the help engineer’s assessment.
| Discipline | Element |
| Case sort | Quota Request |
| Alarms | Any of: ClientErrors-Vital, Throttles-Vital, HighInvocationRate-Warning, HighTPMQuotaUsage-Warning, InvocationAnomaly-Warning, InputTokenAnomaly-Warning, OutputTokenAnomaly-Warning |
| Quota requested | RPM-specific alarms → RPM solely. TPM-specific alarms → TPM solely. Undetermined quota alarms (Throttles, ClientErrors) → Each RPM and TPM |
| Rationale | The help case bypasses the utilization guard as a result of the mannequin has no utilization historical past to validate towards |
Instance
InputTokenAnomaly alarm triggered on a freshly deployed mannequin:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-InputTokenAnomaly-Warning-{ModelName} |
| Metric | InputTokenCount (Sum per minute) |
| Classification | TPM-specific alarm → TPM quota enhance solely |
| RPM quota | 200 |
| Peak RPM | 0 (no utilization historical past) |
| TPM quota | 500,000 |
| Peak TPM | 0 (no utilization historical past) |
| Choice | peak_rpm = 0 AND peak_tpm = 0 → new_model |
| Consequence | Quota Request. TPM enhance particulars included |
Excessive utilization (peak meets or exceeds threshold): A quota-related alarm triggered AND 14-day peak RPM meets or exceeds the RPM threshold OR 14-day peak TPM meets or exceeds the TPM threshold. The help case consists of quota enhance particulars with utilization knowledge confirming sustained consumption traits. For CRITICAL severity, the case features a word indicating that utilization is approaching charge limits.
| Discipline | Element |
| Case sort | Quota Request |
| Alarms | Any of: ClientErrors-Vital, Throttles-Vital, HighInvocationRate-Warning, HighTPMQuotaUsage-Warning, InvocationAnomaly-Warning, InputTokenAnomaly-Warning, OutputTokenAnomaly-Warning |
| Quota requested | RPM-specific alarms → RPM solely. TPM-specific alarms → TPM solely. Undetermined quota alarms (Throttles, ClientErrors) → Each RPM and TPM |
| Rationale | Peak utilization meets or exceeds the alarm threshold, confirming sustained quota utilization traits |
Examples
Throttles alarm triggered:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-Throttles-Vital-{ModelName} |
| Metric | InvocationThrottles (Sum per minute) |
| Classification | Undetermined quota alarm → Each RPM and TPM quota will increase |
| Severity | CRITICAL |
| RPM quota | 10,000 |
| RPM threshold | 8,000 (80% of quota) |
| Peak RPM | 9,500 |
| TPM quota | 6,250,000 |
| TPM threshold | 5,000,000 (80% of quota) |
| Peak TPM | 3,000,000 |
| Choice | peak_rpm (9,500) >= rpm_threshold (8,000) → high_usage |
| Consequence | Quota Request. Each RPM and TPM enhance particulars included. “Expedited processing” |
HighTPMQuotaUsage alarm triggered:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-HighTPMQuotaUsage-Warning-{ModelName} |
| Metric | EstimatedTPMQuotaUsage (Sum per minute) |
| Classification | TPM-specific alarm → TPM quota enhance solely |
| RPM quota | 200 |
| RPM threshold | 160 (80% of quota) |
| Peak RPM | 150 |
| TPM quota | 200,000 |
| TPM threshold | 160,000 (80% of quota) |
| Peak TPM | 210,000 |
| Choice | peak_tpm (210,000) >= tpm_threshold (160,000) → high_usage |
| Consequence | Quota Request. TPM enhance particulars included |
Low utilization (peak beneath threshold): A quota-related alarm triggered however 14-day peak RPM is beneath the RPM threshold AND 14-day peak TPM is beneath the TPM threshold. Since utilization metrics recommend a transient occasion slightly than sustained quota consumption traits, the answer sends an electronic mail notification to the AI SRE crew to analyze root trigger first and collaborate with the help engineer, if wanted. The help case consists of quota enhance particulars as reference solely, in case the investigation confirms the necessity.
| Discipline | Element |
| Case sort | Quota Request |
| Alarms | Any of: ClientErrors-Vital, Throttles-Vital, HighInvocationRate-Warning, HighTPMQuotaUsage-Warning, InvocationAnomaly-Warning, InputTokenAnomaly-Warning, OutputTokenAnomaly-Warning |
| Quota requested | RPM-specific alarms → RPM solely (as reference). TPM-specific alarms → TPM solely (as reference). Undetermined quota alarms (Throttles, ClientErrors) → Each RPM and TPM (as reference) |
| Rationale | Utilization metrics recommend a transient occasion slightly than sustained utilization traits. Quota particulars are offered as reference in case the investigation confirms the necessity |
Examples
InvocationAnomaly alarm triggered:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-InvocationAnomaly-Warning-{ModelName} |
| Metric | Invocations (Sum per minute) |
| Classification | RPM-specific alarm → RPM quota enhance solely |
| RPM quota | 10,001 |
| RPM threshold | 8,000 (80% of quota) |
| Peak RPM | 5,578 |
| TPM quota | 6,250,000 |
| TPM threshold | 5,000,000 (80% of quota) |
| Peak TPM | 3,404,691 |
| Choice | peak_rpm (5,578) < rpm_threshold (8,000) AND peak_tpm (3,404,691) < tpm_threshold (5,000,000) → low_usage |
| Consequence | Quota Request with investigate-first tone. RPM enhance particulars included as reference |
ClientErrors alarm triggered:
| Discipline | Worth |
| Alarm | {CustomerName}-Bedrock-ClientErrors-Vital-{ModelName} |
| Classification | Undetermined quota alarm → Each RPM and TPM quota will increase |
| Severity | CRITICAL |
| RPM quota | 200 |
| RPM threshold | 160 (80% of quota) |
| Peak RPM | 50 |
| TPM quota | 200,000 |
| TPM threshold | 160,000 (80% of quota) |
| Peak TPM | 80,000 |
| Choice | peak_rpm (50) < rpm_threshold (160) AND peak_tpm (80,000) < tpm_threshold (160,000) → low_usage |
| Consequence | Quota Request with investigate-first tone. Each RPM and TPM enhance particulars included as reference |
This validation confirms that quota enhance requests mirror precise utilization patterns, whereas nonetheless offering quota particulars as reference for the help engineer’s investigation.
Help case administration and electronic mail notifications
The answer makes use of category-aware duplicate detection to assist stop redundant instances. When a brand new alarm triggers and an unresolved case of the identical class (Quota Request or Investigation Request) already exists, the system appends a communication to the prevailing case as an alternative of making a replica. The appended communication consists of full alarm particulars, up to date utilization metrics, and quota enhance requests (if relevant), prefixed with urgency context signaling that the state of affairs is escalating. This makes positive the help engineer is knowledgeable of recent alerts with out creating conflicting instances. A quota request case for one alarm sort doesn’t block an investigation request case for a distinct alarm sort, and the alternative can also be true.
Help case parameters are saved in Parameter Retailer and might be up to date with out redeploying the CloudFormation stack. You may allow or disable automated case creation, regulate quota enhance percentages (0–100%), and configure electronic mail notification filtering (all alerts, vital solely, or warning solely).
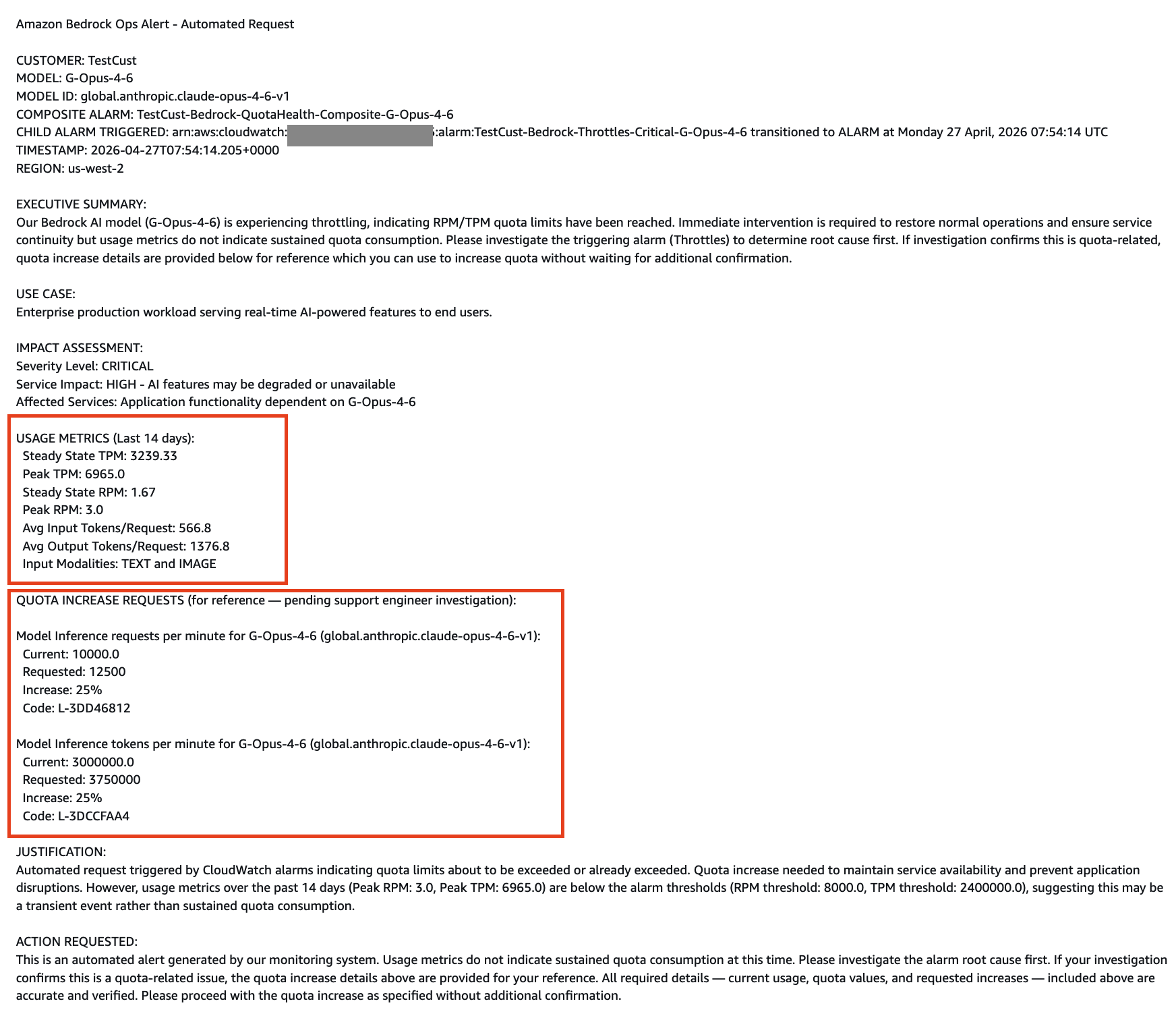
The next screenshot reveals an automatic “Quota Request” help case created for a quota-related alarm, pre-filled with usage-validated quota knowledge and enhance request particulars. This pre-filled context helps the help engineer resolve the case quicker by offering the knowledge wanted upfront. This screenshot demonstrates the help case format generated by the answer.
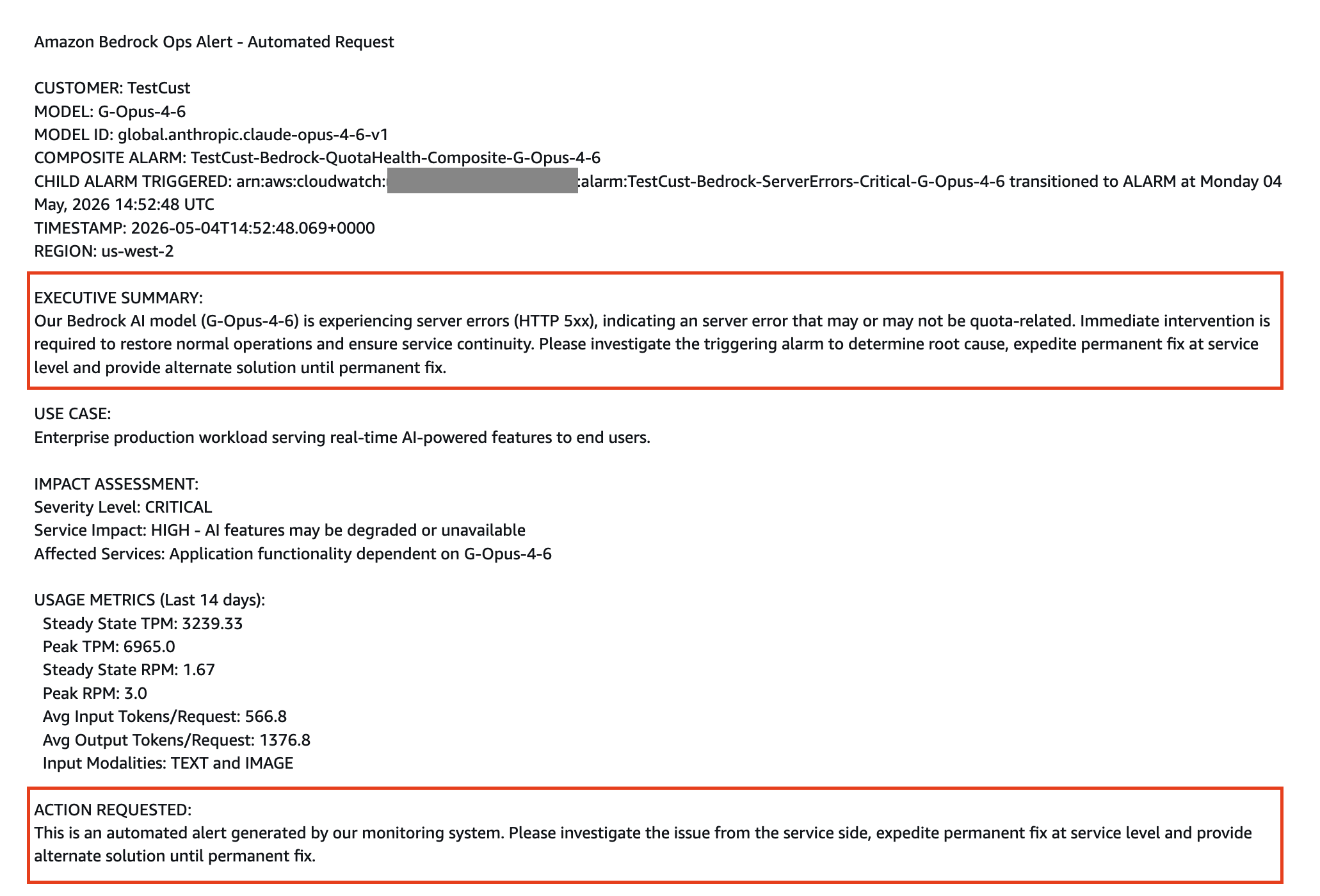
The next screenshot reveals an automatic “Investigation Request” help case created for a non-quota alarm (corresponding to server errors or latency points), offering related alarm context and metrics to allow environment friendly root trigger investigation. This screenshot demonstrates the help case format generated by the answer.
Electronic mail notifications are despatched after help case processing completes. If a help case was created, the e-mail consists of the case ID and a direct hyperlink to the AWS Help console, giving the AI SRE crew speedy visibility into the automated case and supporting coordinated follow-up. Electronic mail content material is tailor-made for the AI SRE crew perspective, whereas help case content material is tailor-made for the help engineer.
Outcomes
Amazon Bedrock Ops Alert delivers the next outcomes:
- Improved operational effectivity: The AI SRE crew shift from guide monitoring to higher-value work.
- Clever alarm classification: Non-quota alarms (server errors, latency anomalies) are routed to investigation instances as an alternative of quota enhance requests, offering help engineers with focused case context and accelerating root trigger decision.
- Utilization-validated help instances: The answer compares peak utilization towards thresholds earlier than creating help instances, validating that quota enhance requests mirror precise utilization patterns and embrace applicable context for the help engineer.
- Decreased imply time to decision: Automated case creation reduces guide effort for every incident from hours to minutes.
- Proactive quota administration: Quota enhance requests are initiated earlier than utilization reaches charge limits in manufacturing purposes.
- No guide threshold upkeep: Alarms keep correct as authorised quota will increase change the goal, with no engineer intervention required.
- Scalable basis: Extra Bedrock fashions might be monitored by deploying extra stack cases, supporting an increasing generative AI portfolio.
Deploy the answer
For step-by-step deployment directions, together with stipulations, packaging, CloudFormation stack deployment, parameter reference, testing, and cleanup, see the Deployment Guide within the GitHub repository.
Conclusion
Generative AI monitoring is not like conventional infrastructure monitoring. As generative AI adoption blurs the boundaries between enterprise and know-how groups, with non-engineering groups now utilizing custom-built generative AI purposes powered by Amazon Bedrock-hosted basis fashions, organizations must rethink their operational monitoring technique to match this new actuality.
On this put up, we launched Amazon Bedrock Ops Alert, a multi-layer operational monitoring resolution composed of AWS native providers, to handle the operational wants of working generative AI workloads at scale. The three-layer monitoring structure, consisting of vital error detection, utilization charge monitoring, and anomaly sample recognition, gives complete visibility into generative AI workloads throughout operational points, utilization traits, and strange conduct. The answer’s clever alarm classification routes client-side points, latency considerations, and quota-related alerts to the suitable help case sort, every enriched with the context a help engineer must act rapidly. Earlier than making a help case, the utilization validation guard compares latest peak utilization towards saved thresholds to substantiate the case is warranted, and duplicate case prevention suppresses new instances when an unresolved case of the identical alarm class is already lively, conserving investigations centered. Contextualized electronic mail notifications maintain the AI SRE crew knowledgeable and aligned with the automated case all through. By automating CloudWatch alarm threshold recalculation, the answer additionally removes the guide effort of investigating the brand new quota worth, calculating the suitable alarm threshold, and updating alarms after every authorised quota enhance, conserving alarms correct and assuaging the danger of stale thresholds.
Collectively, these capabilities shift operations from reactive monitoring to proactive operational monitoring, lowering imply time to decision, anticipating additional quota enhance wants as adoption grows, and liberating AI SRE groups to deal with constructing generative AI purposes slightly than monitoring infrastructure.
You may lengthen this resolution by integrating with incident administration techniques, monitoring a number of Bedrock fashions with separate stack deployments, customizing alarm patterns for particular use instances, and implementing predictive scaling based mostly on historic utilization patterns.
To get began, go to the Amazon Bedrock Ops Alert repository on GitHub. To study extra about Amazon Bedrock quotas, see Amazon Bedrock endpoints and quotas. To discover Amazon Bedrock, go to the Amazon Bedrock element web page.
Disclaimer: This resolution is offered as-is for academic functions. You might be chargeable for evaluating, testing, and validating all options in non-production environments earlier than deploying to manufacturing techniques. Conduct complete testing together with efficiency validation, safety assessments, and compliance verification to ensure options meet your particular necessities and regulatory obligations.
In regards to the authors

{kind=link}