


Most builders deal with prompts as consequentials. Create cheap content material, observe the output, and iterate as obligatory. This strategy works till reliability turns into vital. When the LLM is moved to a manufacturing system, a immediate and traditional What works and what works persistently It turns into an engineering concern. In response, the analysis group has formalized prompts right into a set of well-defined strategies, every designed to handle a particular failure mode, whether or not in construction, reasoning, or model. These strategies work fully on the immediate layer, so no tweaks, mannequin modifications, or infrastructure upgrades are required.
This text focuses on 5 such strategies. Position-specific prompts, detrimental prompting, JSON immediate, Attentive Reasoning Queries (ARQ)and Verbalized sampling. Quite than protecting well-known baselines like zero photographs and primary thought chains, we’re focusing right here on what modifications while you apply these strategies. We reveal every by evaluating the identical duties aspect by aspect, highlighting their influence on output high quality and explaining the underlying mechanisms.
Establishing dependencies
Right here we’ll arrange a minimal atmosphere for interacting with the OpenAI API. Outline a light-weight chat wrapper that makes use of getpass to securely load the API key at runtime, initialize the consumer, and ship system and person prompts to the mannequin (gpt-4o-mini). This retains the experimental loop clear and reusable whereas focusing solely on variations of the immediate.
Helper features (sections and dividers) are just for formatting the output and make it simpler to check baseline and improved prompts aspect by aspect. If you do not have an API key but, you possibly can create one from the official dashboard right here. https://platform.openai.com/api-keys
import json
from openai import OpenAI
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')
consumer = OpenAI()
MODEL = "gpt-4o-mini"
def chat(system: str, person: str, **kwargs) -> str:
"""Minimal wrapper across the chat completions endpoint."""
response = consumer.chat.completions.create(
mannequin=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
**kwargs,
)
return response.selections[0].message.content material
def part(title: str) -> None:
print()
print("=" * 60)
print(f" {title}")
print("=" * 60)
def divider(label: str) -> None:
print(f"n── {label} {'─' * (54 - len(label))}")Position-specific prompts
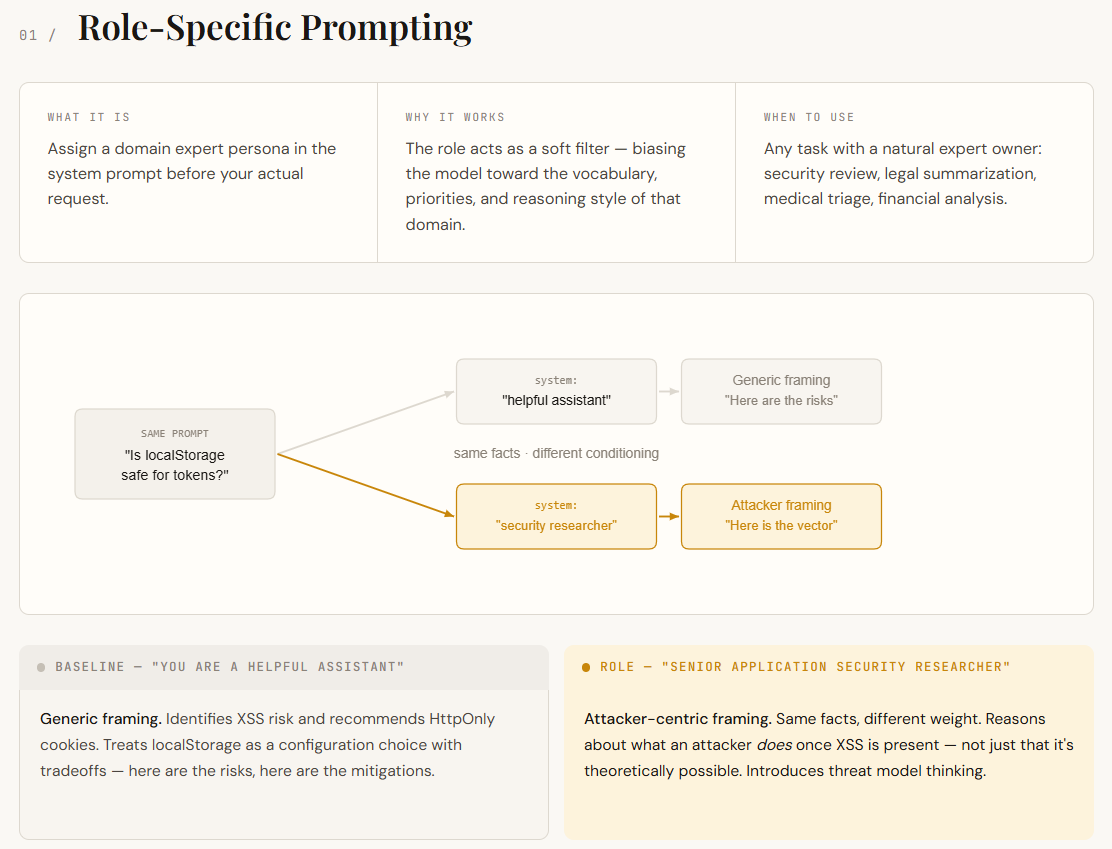
Language fashions are educated on a variety of combos of disciplines, together with safety, advertising and marketing, authorized, and engineering. Should you do not specify a task, the mannequin will extract from all roles, supplying you with a usually appropriate however considerably common reply. Position-specific prompts remedy this drawback by assigning a persona within the system immediate (for instance, “You’re a senior utility safety researcher”). This acts like a filter, pushing the mannequin to reply utilizing its area’s language, priorities, and inference model.
On this instance, each responses establish XSS dangers and suggest HttpOnly cookies. The underlying truth is similar. The distinction lies in how the fashions body the issue. The baseline treats localStorage as a configuration selection with tradeoffs. Position-specific responses deal with this as an assault floor. That’s, we infer not solely that XSS is theoretically attainable, but in addition what an attacker may do within the presence of XSS. The shift in body from “listed below are the dangers” to “here is what an attacker would do about these dangers” is the precise conditioning impact. No new info was offered. The prompts merely modified which components of the mannequin’s information have been weighted.
part("TECHNIQUE 1 -- Position-Particular Prompting")
QUESTION = "Our net app shops session tokens in localStorage. Is that this an issue?"
baseline_1 = chat(
system="You're a useful assistant.",
person=QUESTION,
)
role_specific = chat(
system=(
"You're a senior utility safety researcher specializing in "
"net authentication vulnerabilities. You assume when it comes to assault "
"floor, menace fashions, and OWASP tips."
),
person=QUESTION,
)
divider("Baseline")
print(baseline_1)
divider("Position-specific (safety researcher)")
print(role_specific)detrimental immediate
Detrimental prompts concentrate on telling the mannequin what to not do. By default, LLM follows the patterns discovered throughout coaching and RLHF, including descriptive openings, analogies, hedges (“in context”), and shutting summaries. Whereas this makes the response really feel helpful, it usually provides pointless noise in a technical context. Detrimental prompts work by eradicating these defaults. It not solely describes the specified output, but in addition limits undesired habits, leading to a narrower mannequin output house and extra correct response.
You may instantly see the distinction within the output. Baseline responses vary from longer, structured explanations with analogies, headers, and redundant conclusions. The detrimental immediate model offers the identical core info in a a lot shorter format (direct, concise, and with out dietary supplements). Nothing vital is misplaced. Prompts merely take away the mannequin’s tendency to overexplain and inflate responses.
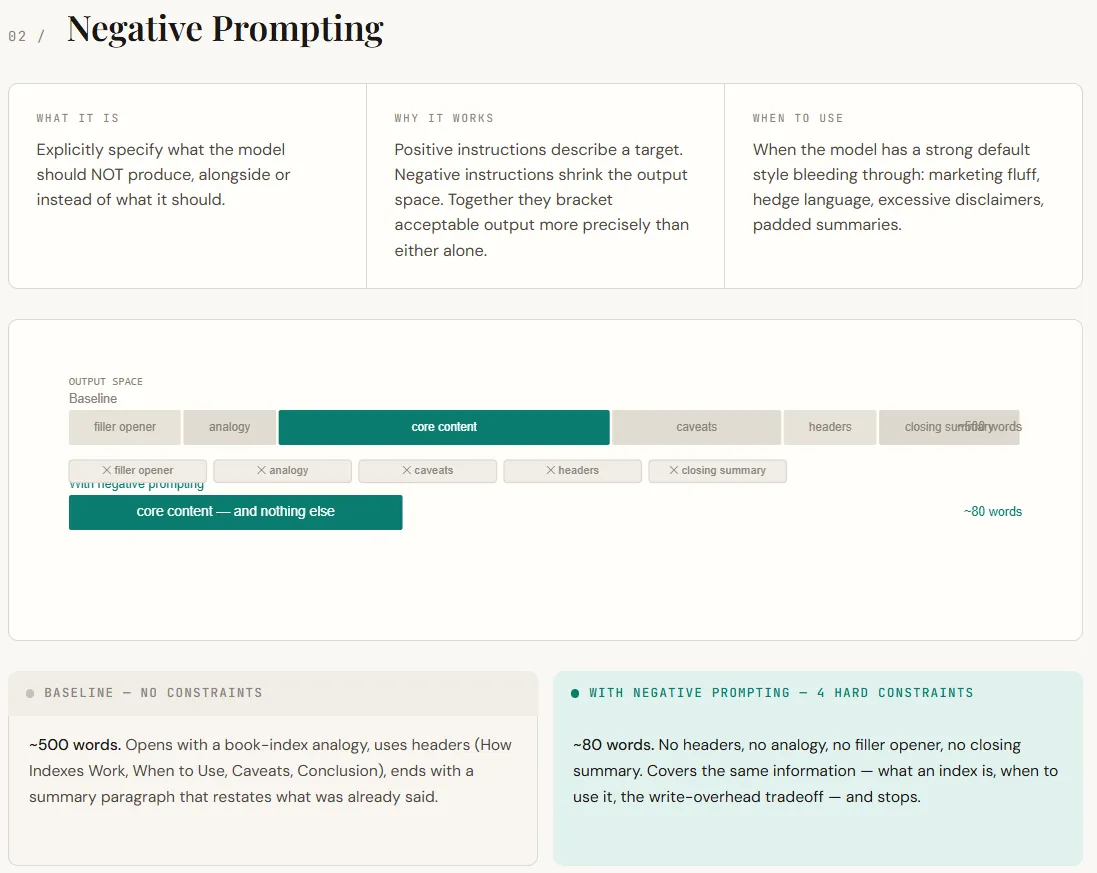
part("TECHNIQUE 2 -- Detrimental Prompting")
TOPIC = "Clarify what a database index is and while you'd use one."
baseline_2 = chat(
system="You're a useful assistant.",
person=TOPIC,
)
detrimental = chat(
system=(
"You're a senior backend engineer writing inside documentation.n"
"Guidelines:n"
"- Do NOT use advertising and marketing language or filler phrases like 'nice query' or 'definitely'.n"
"- Do NOT embody caveats like 'it relies upon' with out instantly resolving them.n"
"- Do NOT use analogies except they're obligatory. Should you use one, maintain it to at least one sentence.n"
"- Do NOT pad the response -- when you've made the purpose, cease.n"
),
person=TOPIC,
)
divider("Baseline")
print(baseline_2)
divider("With detrimental prompting")
print(detrimental)JSON immediate (schema-constrained output)
JSON prompts develop into vital when the LLM output must be utilized in code slightly than simply being learn by people. Free-form solutions are inconsistent. The construction is totally different, vital particulars are buried in paragraphs, and small modifications in wording break the parsing logic. Defining a JSON schema on the immediate turns the construction into a tough constraint. This not solely standardizes the output format, but in addition forces the mannequin to arrange its inferences into well-defined fields similar to professionals and cons, sentiment, and scores.
The distinction is apparent while you have a look at the output. Though baseline responses are straightforward to learn, they’re troublesome to parse as a result of they’re unstructured and the narrative textual content is combined with professionals, cons, and feelings. Nevertheless, the JSON immediate model returns clear, well-defined fields which you could load and use straight in your code with none post-processing. Info that was beforehand implicit is now explicitly separated, making it simpler to retailer, question, and evaluate output at scale.

part("TECHNIQUE 3 -- JSON Prompting")
REVIEW = """
Truthfully combined emotions about this laptop computer. The show is gorgeous -- simply the most effective I've
seen at this worth vary -- and the keyboard is surprisingly comfy for lengthy periods.
Battery life, then again, barely will get me by a 6-hour workday, which is
disappointing. Fan noise beneath load can also be fairly aggressive. For mild work it is nice,
however I would not suggest it for anybody who must run heavy software program.
"""
SCHEMA = """
combined",
"ranking": <integer 1-5>,
"professionals": ["<string>", ...],
"cons": ["<string>", ...],
"recommended_for": "<string describing supreme person>",
"not_recommended_for": "<string describing person who ought to keep away from>"
"""
baseline_3 = chat(
system="You're a useful assistant.",
person=f"Summarize this product assessment:nn{REVIEW}",
)
json_output = chat(
system=(
"You're a product assessment parser. Extract structured info from critiques.n"
"You MUST return solely a legitimate JSON object. No preamble, no clarification, no markdown fences.n"
f"The JSON should match this schema precisely:n{SCHEMA}"
),
person=f"Parse this assessment:nn{REVIEW}",
)
divider("Baseline (free-form)")
print(baseline_3)
divider("JSON prompting (uncooked output)")
print(json_output)
divider("Parsed & usable in code")
parsed = json.hundreds(json_output)
print(f"Sentiment : {parsed['overall_sentiment']}")
print(f"Ranking : {parsed['rating']}/5")
print(f"Execs : {', '.be a part of(parsed['pros'])}")
print(f"Cons : {', '.be a part of(parsed['cons'])}")
print(f"Beneficial for : {parsed['recommended_for']}")
print(f"Keep away from if : {parsed['not_recommended_for']}")Attentive Reasoning Queries (ARQ)
Attentive Reasoning Queries (ARQs) are constructed on thought chain prompts, however take away their greatest weak spot: unstructured reasoning. In a typical CoT, the mannequin decides what to concentrate on. This will result in gaps and irrelevant particulars. ARQ replaces this with a hard and fast set of domain-specific questions that the mannequin should reply in sequence. This ensures that each one vital points are coated and transfers management from the mannequin to the immediate designer. Quite than merely guiding how a mannequin thinks, ARQ defines what it wants to think about.
Within the output, the variations present up as self-discipline and scope. Baseline CoT responses establish vital points however drift into much less related areas, lacking deeper evaluation in some locations. Nevertheless, the ARQ model systematically addresses every of the required factors, together with clear separation of vulnerabilities, dealing with of edge circumstances, and analysis of efficiency influence. Every query acts as a checkpoint, making your solutions extra structured, full, and simpler to audit.
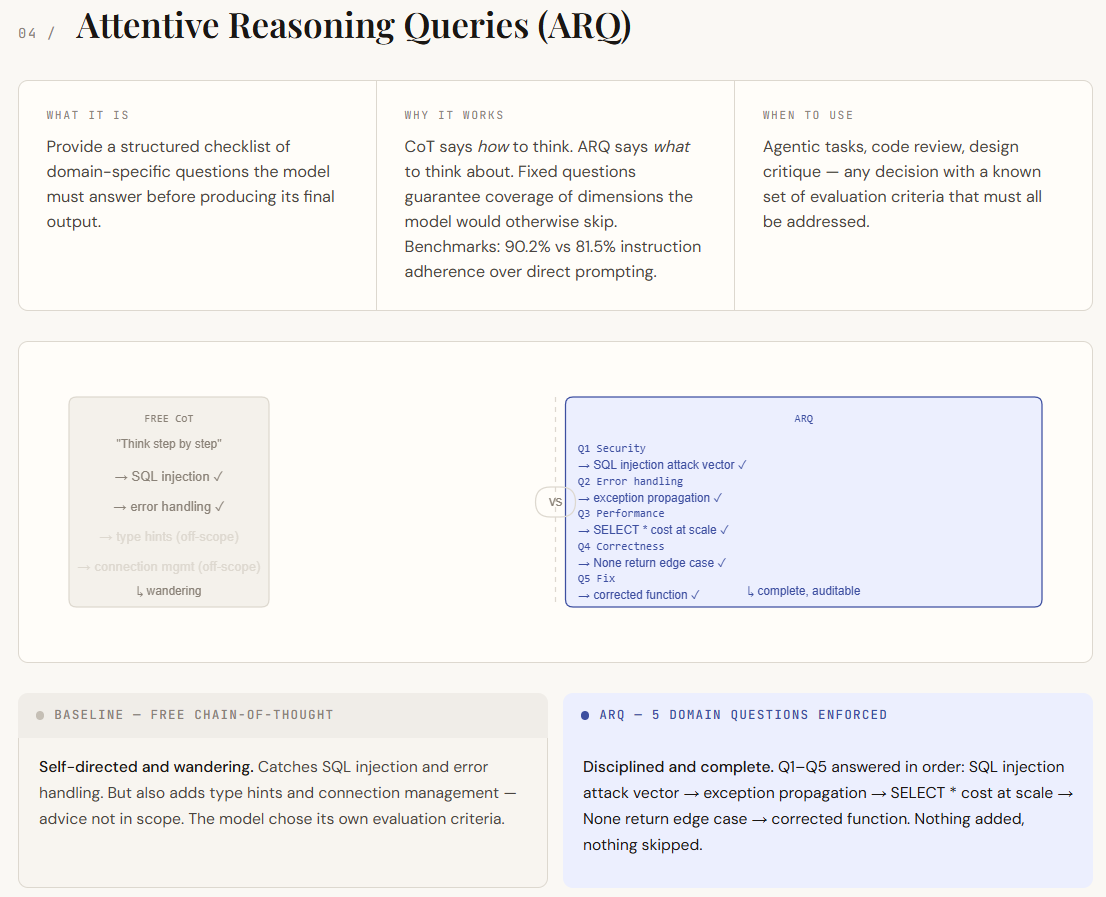
part("TECHNIQUE 4 -- Attentive Reasoning Queries (ARQ)")
CODE_TO_REVIEW = """
def get_user(user_id):
question = f"SELECT * FROM customers WHERE id = {user_id}"
outcome = db.execute(question)
return outcome[0] if outcome else None
"""
ARQ_QUESTIONS = """
Earlier than giving your ultimate assessment, reply every of the next questions so as:
Q1 [Security]: Does this code have any injection vulnerabilities?
If sure, describe the precise assault vector.
Q2 [Error handling]: What occurs if db.execute() throws an exception?
Is that acceptable?
Q3 [Performance]: Does this question retrieve extra knowledge than obligatory?
What's the value at scale?
This autumn [Correctness]: Are there edge circumstances within the return logic that might
trigger a silent bug downstream?
Q5 [Fix]: Write a corrected model of the perform that addresses
all points discovered above.
"""
baseline_cot = chat(
system="You're a senior software program engineer. Suppose step-by-step.",
person=f"Evaluate this Python perform:nn{CODE_TO_REVIEW}",
)
arq_result = chat(
system="You're a senior software program engineer conducting a security-aware code assessment.",
person=f"Evaluate this Python perform:nn{CODE_TO_REVIEW}nn{ARQ_QUESTIONS}",
)
divider("Baseline (free CoT)")
print(baseline_cot)
divider("ARQ (structured reasoning guidelines)")
print(arq_result)Verbalized sampling
Verbalized sampling addresses an vital limitation of LLM. LLMs are inclined to confidently return a single reply even when a number of interpretations are attainable. This occurs as a result of alignment coaching prioritizes decisive outcomes. Because of this, the mannequin hides inside uncertainties. Verbalized sampling solves this drawback by explicitly asking for a number of hypotheses with confidence rankings and supporting proof. Quite than forcing a single reply, quite a lot of believable outcomes are introduced throughout the immediate with out altering the mannequin.
The output strikes the outcomes from a single label to a structured diagnostic view. The baseline offers one classification with out indicating any uncertainty. Nevertheless, the verbalized model lists a number of ranked hypotheses, every with an evidence and how one can take a look at or reject it. This makes the output extra actionable, turning it into a choice assist slightly than simply a solution. Though the arrogance rating itself isn’t an actual chance, it successfully signifies relative probability and is commonly enough for prioritization and downstream workflows.
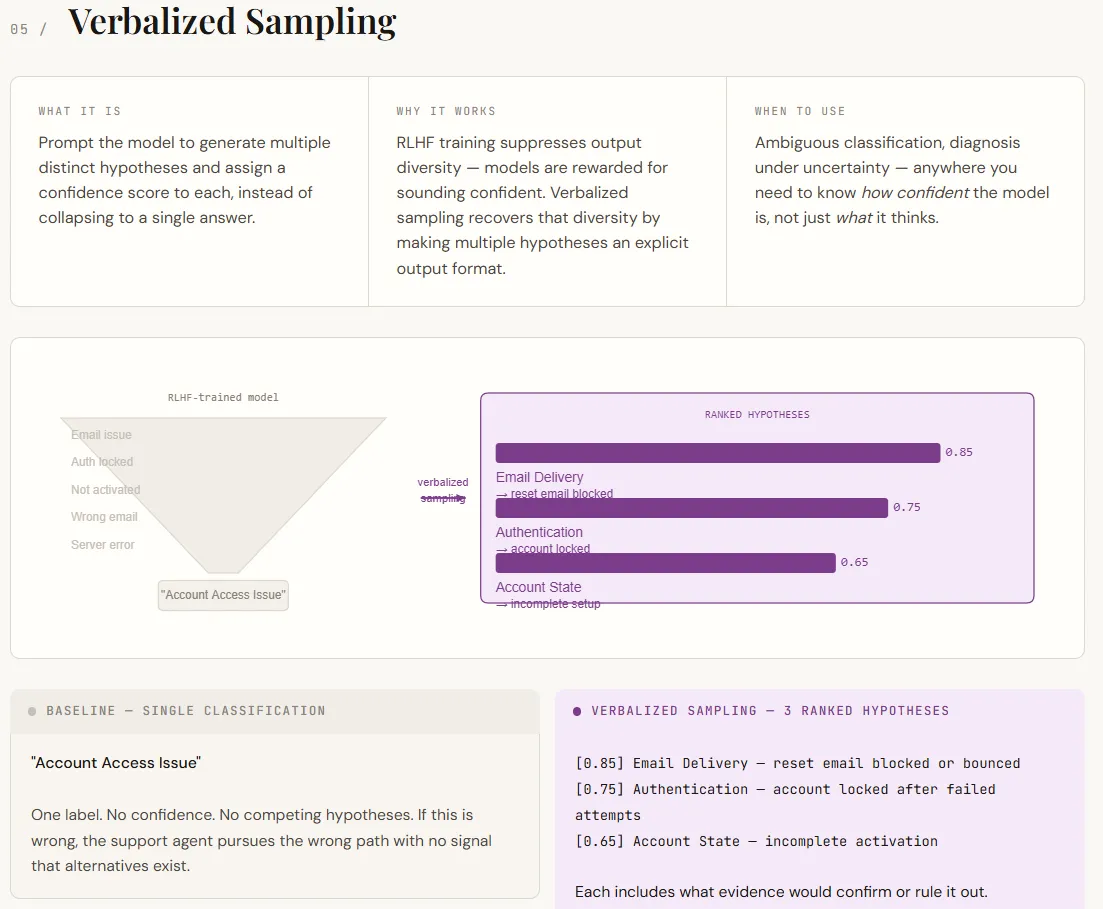
part("TECHNIQUE 5 -- Verbalized Sampling")
SUPPORT_TICKET = """
Hello, I arrange my account final week however I am unable to log in anymore. I attempted resetting
my password however the electronic mail by no means arrives. I additionally tried a unique browser. Nothing works.
"""
baseline_5 = chat(
system="You're a assist ticket classifier. Classify the problem.",
person=f"Ticket:n{SUPPORT_TICKET}",
)
verbalized = chat(
system=(
"You're a assist ticket classifier.n"
"For every ticket, generate 3 distinct hypotheses concerning the root trigger. "
"For every speculation:n"
" - State the class (Authentication, E-mail Supply, Account State, Browser/Consumer, Different)n"
" - Describe the particular failure moden"
" - Assign a confidence rating from 0.0 to 1.0n"
" - State what extra info would verify or rule it outnn"
"Order hypotheses by confidence (highest first). "
"Then present a advisable first motion for the assist agent."
),
person=f"Ticket:n{SUPPORT_TICKET}",
)
divider("Baseline (single reply)")
print(baseline_5)
divider("Verbalized sampling (a number of hypotheses + confidence)")
print(verbalized)Please test Here is the complete code using notebook. Please be at liberty to observe us too Twitter Remember to affix us 130,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.
Have to associate with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and many others.?connect with us
The put up A Developer’s Information to Systematic Prompts: Mastering Detrimental Constraints, Structured JSON Output, and Verbalized Sampling of A number of Hypotheses appeared first on MarkTechPost.

{kind=link}