


DeepSeek-AI has launched a preview model of the DeepSeek-V4 sequence. It’s a two-mixed-of-experts (MoE) language mannequin constructed round one core problem, making a million-token context window sensible and inexpensive throughout inference.
The sequence consists of DeepSeek-V4-Professional with 1.6T whole parameters and 49B activations per token, and DeepSeek-V4-Flash with 284B whole parameters and 13B activations per token. Each fashions natively help a context size of 1 million tokens. DeepSeek-V4-Professional was pre-trained with 33T tokens and DeepSeek-V4-Flash was pre-trained with 32T tokens. Mannequin checkpoints for all 4 variants: DeepSeek-V4-Professional, DeepSeek-V4-Professional-Base, DeepSeek-V4-Flash, and DeepSeek-V4-Flash-Base are revealed on Hugging Face.
Architectural challenges of lengthy contexts
The usual Transformer vanilla consideration mechanism has quadratic complexity with respect to sequence size, and doubling the context roughly quadruples the eye complexity and reminiscence. At 1 million tokens, this turns into prohibitive with out architectural intervention. DeepSeek-V4 addresses this downside by 4 coordinated improvements: a hybrid consideration structure, a brand new residual connection design, a distinct optimizer, and FP4 quantization-aware coaching.
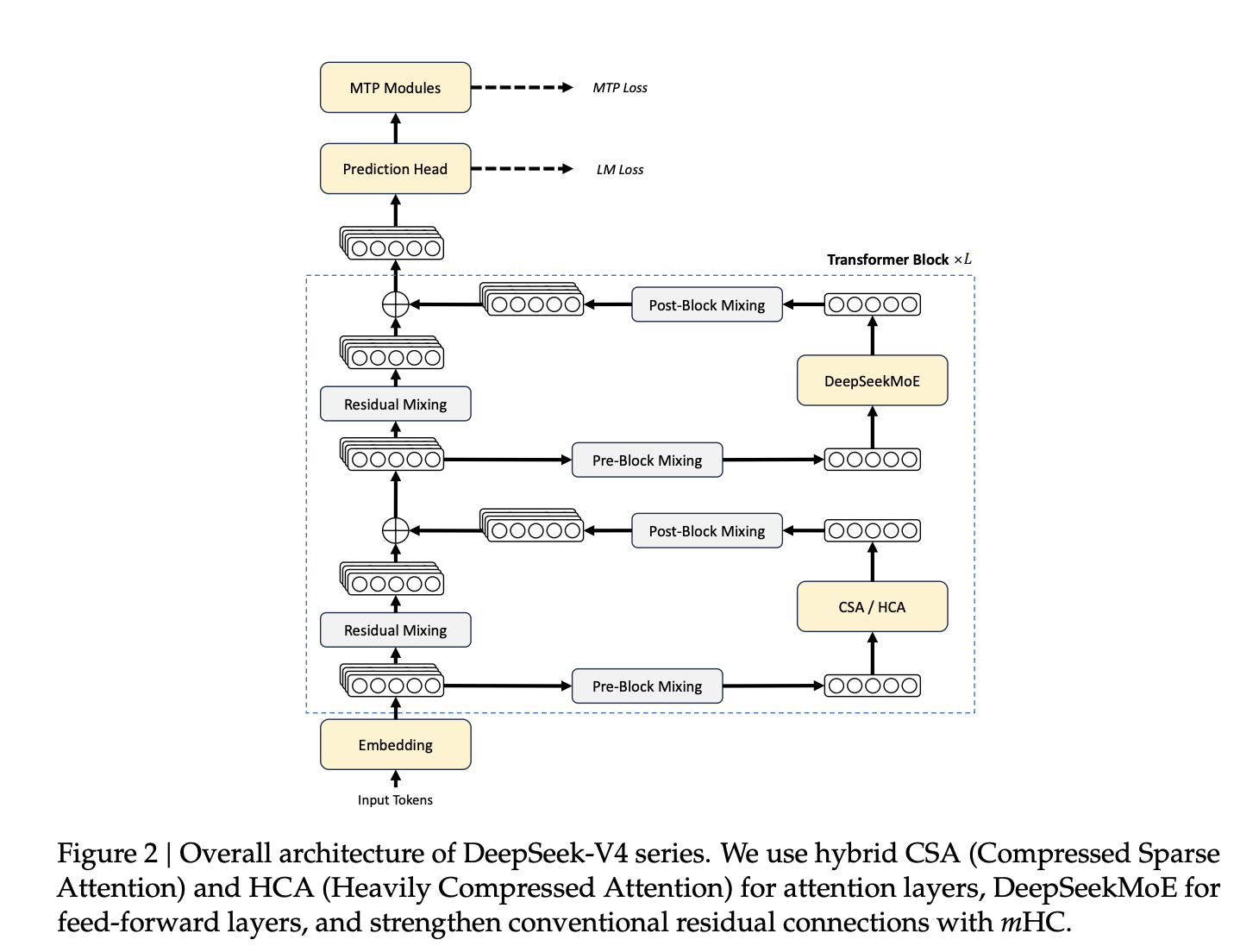
Hybrid Consideration: CSA and HCA
The central architectural innovation is a hybrid mechanism that mixes Compressed Sparse Attendant (CSA) and Heavyly Compressed Attendance (HCA) interleaved throughout the Transformer layer.
CSA compresses all key/worth (KV) caches. meter It makes use of a discovered token-level compressor to transform tokens right into a single entry and applies DeepSeek sparse consideration (DSA), the place every question token corresponds to the topmost solely.okay Chosen compressed KV entry. A element referred to as Lightning Indexer handles sparse choice by scoring queries in opposition to compressed KV blocks. Each CSA and HCA embody sliding window consideration branches that cowl the most recent data. nwin Token for native dependency modeling.
HCA is extra aggressive. Consolidate all KV entries. m’ Token — the place Mu ≫ Mu Mix them right into a single compressed entry after which pay intensive consideration to their illustration. No want for sparse choice steps. The compression ratio itself reduces the KV cache dimension.
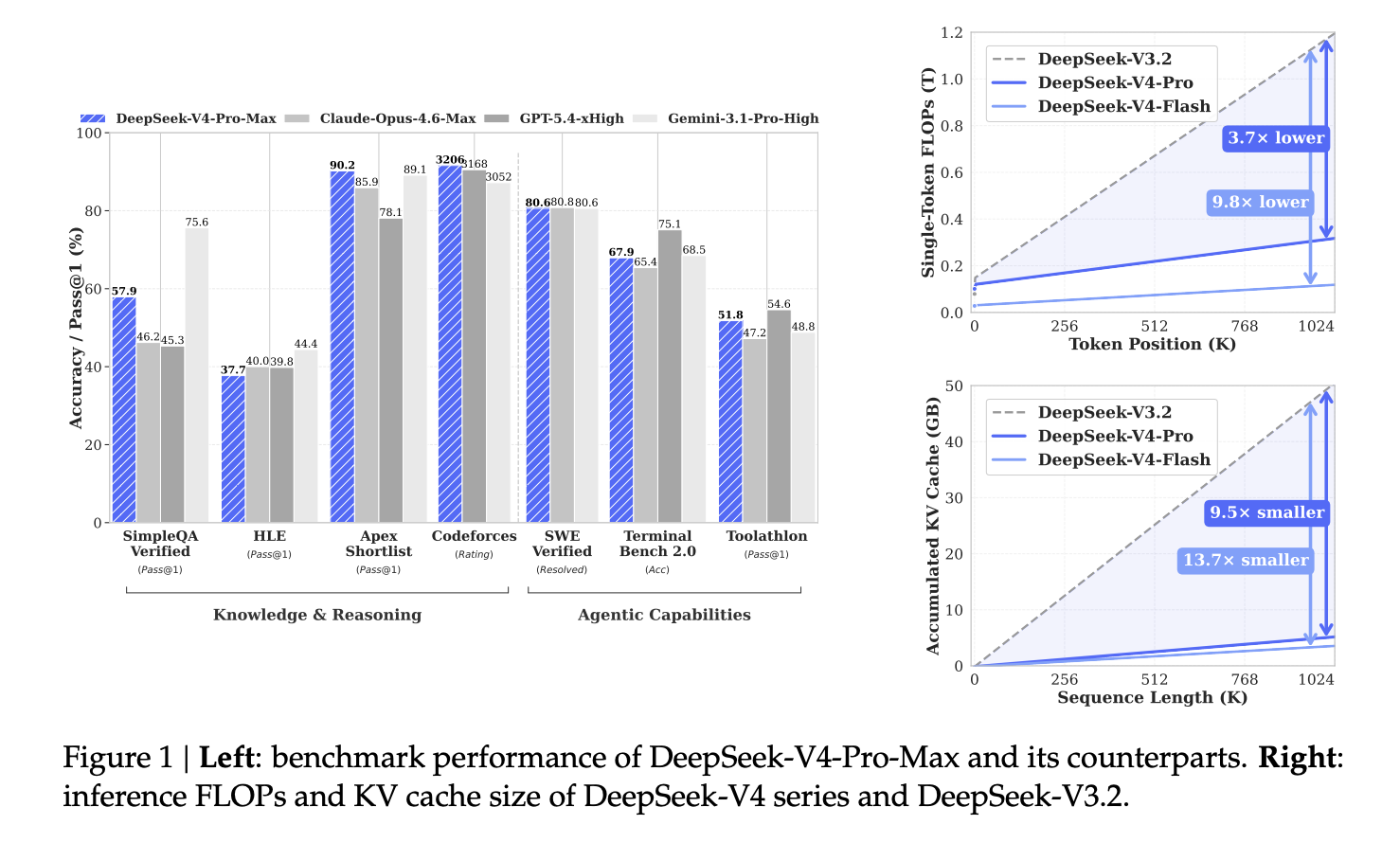
Effectivity is tremendously improved. Within the 1 million token configuration, DeepSeek-V4-Professional requires solely 27% of the single-token inference FLOPs (equal to FP8 FLOPs) and 10% of the KV cache dimension of DeepSeek-V3.2. DeepSeek-V4-Flash achieves 10% single token FLOP and seven% KV cache in comparison with DeepSeek-V3.2.
Manifold Constraint Hyperconnection (mHC)
DeepSeek-V4 replaces conventional residual connections with Manifold-Constrained Hyper-Connections (mHC). Hyperconnections (HCs) generalize the remaining connections by increasing the remaining stream width by an element of 1. nH.C. (set to 4 for each fashions), introduces the discovered enter, residual, and output mapping matrices. Naive HC turns into unstable when stacking many layers.
mHC solves this by constraining the residual mapping matrix. BI Birkhoff polytope — A manifold of doubly stochastic matrices the place all rows and columns sum to 1 and all entries are nonnegative. This limits the spectral norm of the mapping to 1 and prevents sign amplification in each the ahead path and backward propagation. Constraints are enforced by the Sinkhorn-Knopp algorithm. t_max = 20 iterations. Mapping parameters are dynamically generated for every enter for expressiveness.
Muon Optimizer and FP4 QAT
DeepSeek-V4 employs the Muon optimizer for many of its parameters. Muon makes use of Newton-Schulz iterations to almost orthogonalize the gradient replace matrix earlier than making use of it as a weight replace. This implementation makes use of a hybrid two-phase schedule. Carry out 8 iterations with coefficients (3.4445, -4.7750, 2.0315) for quick convergence, then 2 iterations with coefficients (2, -1.5, 0.5) for stabilization. AdamW is retained for the embedding module, prediction head, static bias and gating coefficients of the mHC module, and all RMSNorm weights.
To extend deployment effectivity, FP4 (MXFP4) Quantization-Conscious Coaching (QAT) is utilized to MoE skilled weights and CSA’s Lightning Indexer Question Key (QK) paths. Throughout inference and RL rollout, actual FP4 weights are used immediately as a substitute of simulated quantization, lowering reminiscence site visitors and sampling latency.
Stability for coaching at scale
Coaching a MoE mannequin with trillion parameters introduces important instability. Two strategies have confirmed efficient. Predictive Routing Decouples Spine and Routing Community Updates: Routing Index in Steps t Calculated utilizing historic parameters θt−Δtbreaking the cycle through which routing selections reinforce outliers within the MoE layer. The SwiGLU clamp constrains the linear element of SwiGLU as follows: [−10, 10] We restrict the higher restrict of gate parts to 10 to immediately suppress anomalous activations. Each strategies have been utilized all through the coaching of each fashions.
Publish-training: Specialist skilled and policy-aligned evaluation
The post-training pipeline replaces DeepSeek-V3.2’s blended RL stage with On-Coverage Distillation (OPD). Unbiased area specialists are first educated in arithmetic, coding, agent duties, and instruction with supervised fine-tuning (SFT), adopted by reinforcement studying with group relative coverage optimization (GRPO). Greater than 10 instructor fashions are then distilled right into a single unified pupil mannequin, minimizing the inverse KL divergence between every instructor’s output distribution on the coed and student-generated trajectories utilizing full-vocabulary logit distillation for steady gradient estimation.
The ensuing mannequin helps three modes of inference effort: No-thinking (quick, no specific thought chains), Excessive-thinking (deliberate reasoning), and Max-thinking (most reasoning effort with devoted system prompts and size penalties throughout RL coaching).
Benchmark outcomes
DeepSeek-V4-Professional-Max achieves a Codeforces score of 3206, which is greater than GPT-5.4-xHigh (3168) and Gemini-3.1-Professional-Excessive (3052). In SimpleQA Verified, it obtained a rating of 57.9 Move@1, which is behind Gemini-3.1-Professional-Excessive (75.6) however higher than Claude Opus 4.6 Max (46.2) and GPT-5.4-xHigh (45.3). In SWE-Verified, DeepSeek-V4-Professional-Max achieves 80.6% decision, barely behind Claude Opus 4.6 Max (80.8%), whereas Gemini-3.1-Professional-Excessive additionally scores 80.6%.
Within the lengthy context benchmark, DeepSeek-V4-Professional-Max scores with an accuracy of 83.5 MMR on OpenAI MRCR 1M and 62.0 on CorpusQA 1M, outperforming Gemini-3.1-Professional-Excessive (76.3 and 53.8, respectively), however higher than Claude Opus 4.6 Max (92.9 and 71.7) in each instances. It has not reached this degree.
Essential factors
- Hybrid CSA and HCA focus reduces KV cache to 10% of DeepSeek-V3.2 at 1 million tokens.
- Manifold-Constrained Hyper-Connections (mHC) exchange remaining connections for extra steady deep coaching.
- The Muon optimizer replaces AdamW in most parameters and supplies sooner convergence and coaching stability.
- Publish-training makes use of coverage distillation by 10+ area specialists as a substitute of conventional blended RL.
- DeepSeek-V4-Flash-Base performs higher than DeepSeek-V3.2-Base regardless of having one-third fewer parameters enabled.
Please examine paper and model weights. Additionally, be happy to comply with us Twitter Remember to affix us 130,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.
Must accomplice with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and many others.?connect with us
The article DeepSeek AI releases DeepSeek-V4: Compressed Sparse Consideration and Extremely Compressed Consideration Permits 1 Million Token Context appeared first on MarkTechPost.

{kind=link}