


On this article, learn to determine, perceive, and mitigate race situations in multi-agent orchestration programs.
Matters lined embrace:
- What are race situations like in a multi-agent surroundings?
- Architectural patterns to forestall shared state conflicts
- Sensible methods reminiscent of idempotency, locking, and concurrency testing
Let’s get straight to the purpose.
Dealing with race situations in multi-agent orchestration
Picture by editor
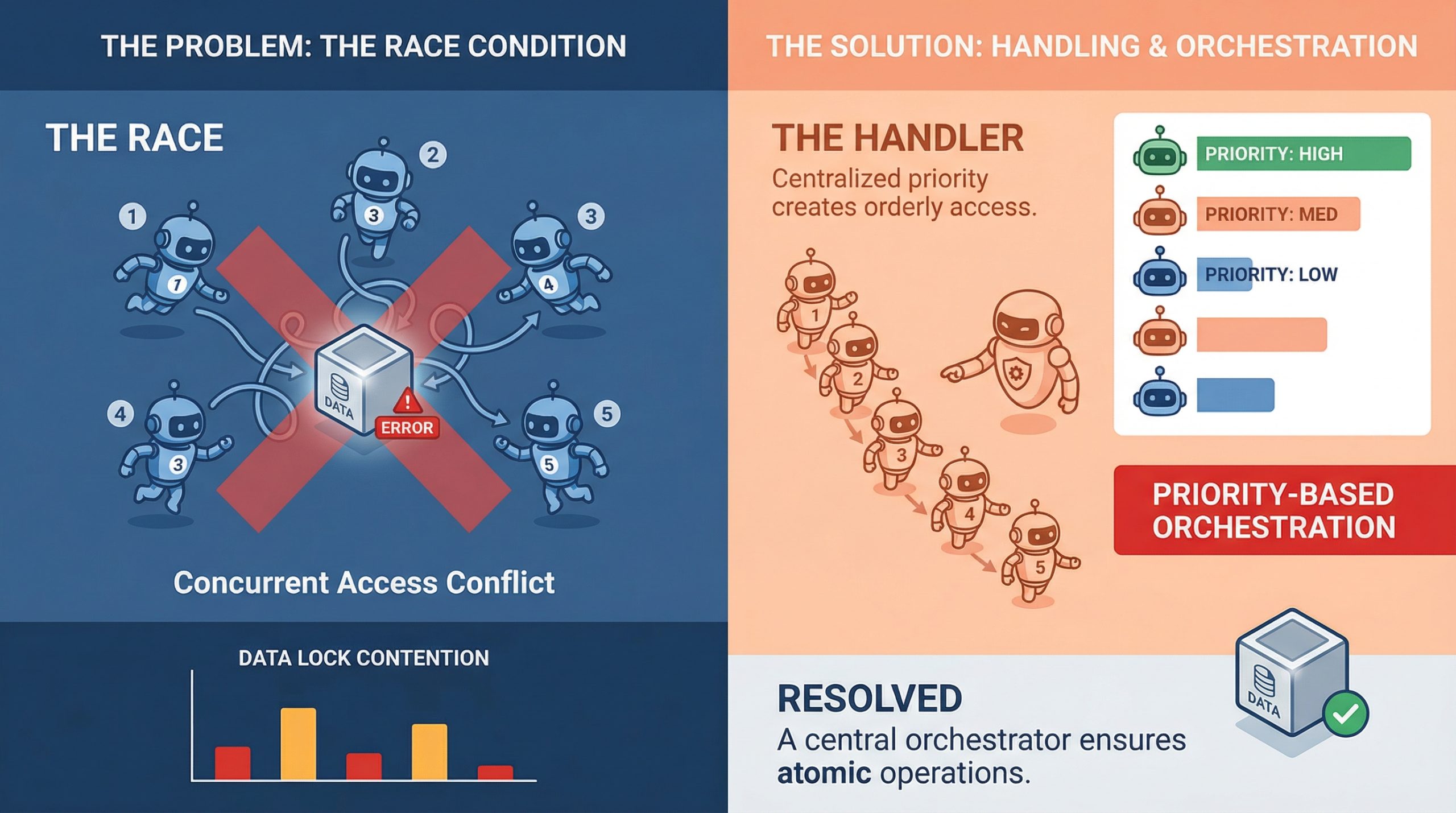
When you’ve ever seen two brokers confidently write to the identical useful resource on the similar time, producing one thing fully meaningless, you already know what a race situation truly seems like. That is a type of bugs that does not present up in unit exams, works completely in staging, after which explodes in manufacturing throughout peak site visitors hours.
In multi-agent programs the place parallel execution is vital, race situations usually are not edge circumstances. They’re scheduled company. Understanding the best way to take care of them is much less about constructing defenses and extra about constructing programs that count on disruption by default.
What race situations truly appear to be in multi-agent programs
A race situation happens when two or extra brokers try to learn, modify, or write shared state on the similar time. The final result depends on which one gets there first. In a single-agent pipeline, that is manageable. A system with 5 brokers working concurrently is a very completely different downside.
The problem is {that a} race situation shouldn’t be all the time an apparent crash. Generally they’re silent. Agent A reads the doc, agent B updates it after 0.5 seconds, and agent A writes again the previous model with out throwing an error wherever. The system appears superb. Knowledge is compromised.
What makes this worse, particularly in machine studying pipelines, is that brokers typically function on mutable shared objects, reminiscent of shared reminiscence shops, vector databases, instrument output caches, and easy job queues. Any of those can develop into rivalry factors if a number of brokers begin pulling on the similar time.
Why multi-agent pipelines are particularly susceptible
Conventional concurrent programming has included instruments for coping with race situations for many years, together with threads, mutexes, semaphores, and atomic operations. Multi-agent large-scale language mannequin (LLM) programs are new; and they are often built on top of asynchronous frameworksmessage brokers, orchestration layers, and so on., don’t all the time have fine-grained management over execution order.
There may be additionally the problem of non-determinism. LLM agent It doesn’t always take the same amount of time to complete a task. One agent might end in 200ms whereas one other takes 2 seconds, and the orchestrator should deal with that appropriately. In any other case, the brokers will begin moving into one another and you’ll find yourself in a corrupted state or write conflicts that the system will silently settle for.
Once more, the agent’s communication sample is essential. If brokers share state by central objects or shared database rows moderately than passing messages, giant write contentions are nearly assured. That is as a lot a design sample situation as it’s a concurrency situation, and fixing this situation sometimes begins on the architectural stage earlier than touching the code.
Locking, queuing, and event-driven design
essentially the most direct technique To handle conflicts for shared resources That is achieved by a lock. Optimistic locking works effectively when conflicts are uncommon. Every agent reads the model tag together with the info, and if the model has modified by the point the write is tried, the write will fail and be retried. Pessimistic locking is extra aggressive and reserves sources earlier than studying. Each approaches have trade-offs, and which one is healthier depends upon how typically the brokers truly collide.
Queuing is one other dependable method, particularly in job task. As a substitute of a number of brokers polling a shared job listing immediately, duties are pushed right into a queue and brokers can eat them one after the other. Redis Streams, RabbitMQ, Alternatively, basic Postgres advisory locks can handle this just as well.. Queues develop into serialization factors and take rivalry out of the equation for sure entry patterns.
Occasion-driven architectures will proceed to evolve. Brokers react to occasions moderately than studying from shared state. Agent A completes the work and publishes an occasion. Agent B listens to that occasion and will get a response from it. This loosens the coupling and naturally reduces the overlap window during which two brokers can change the identical factor on the similar time.
Idempotency is your finest pal
Even with sturdy locking and queuing in place, issues can nonetheless happen. The community goes down, a timeout happens, and the agent retries the failed operation. If these retries usually are not idempotent, duplicate writes, double processing duties, or compound errors will happen, making debugging after the actual fact troublesome.
Idempotency implies that performing the identical operation a number of instances produces the identical outcome as performing it as soon as. For brokers, this typically means together with a singular operation ID for every write. If the operation has already been utilized, the system acknowledges the ID and skips the duplicate. It is a small design selection, but it surely has a huge impact on reliability.
price it Build idempotency at the agent level from the beginning. It’s a trouble to put in it later. Any agent that writes to a database, updates data, or triggers downstream workflows should implement some type of deduplication logic. This permits the complete system to be extra resilient to real-world execution disruptions.
Take a look at for race situations earlier than they’re examined
of The difficult part of a race condition is reproducing the race condition. These are timing dependent. That’s, it typically solely happens below load or in sure execution sequences which might be troublesome to breed in a managed take a look at surroundings.
One helpful method is stress testing with intentional concurrency. Begin a number of brokers concurrently in opposition to a shared useful resource and see what breaks. Instruments like Locust pytest-asyncio Even simultaneous duties or easy duties, ThreadPoolExecutor That is helpful for simulating the type of duplicate executions that reveal battle bugs in a staging surroundings moderately than a manufacturing surroundings.
Property-based testing is underutilized on this context. When you can outline invariants that should all the time maintain no matter execution order, you may carry out randomized exams that violate them. Though it will not detect the whole lot, it is going to floor many delicate consistency points {that a} deterministic take a look at would fully miss.
Examples of particular race situations
It will show you how to make this concrete. Contemplate a easy shared counter that a number of brokers replace. This might signify one thing actual, reminiscent of monitoring what number of instances a doc has been processed or what number of duties have been accomplished.
Under is a minimal model of the issue in pseudocode.
|
# shared state counter = 0 # agent job certainly increment counter(): international counter worth = counter # Step 1: Learn worth = worth + 1 # Step 2: Change counter = worth # Step 3: Write |
Now think about two brokers doing this on the similar time.
- Agent A reads
counter = 0 - agent B reads
counter = 0 - Agent A writes
counter = 1 - Agent B writes
counter = 1
I anticipated the ultimate worth to be 2, however as a substitute it was 1. There are not any errors or warnings, simply an incorrect state. It is a race situation in its easiest type.
There are a number of methods to mitigate this relying in your system design.
Choice 1: Lock the important part
Probably the most direct repair is to permit just one agent at a time to change the shared useful resource. That is proven in pseudo code.
|
rock.get() worth = counter worth = worth + 1 counter = worth rock.launch() |
This ensures accuracy, however at the price of lowered parallelism. If many brokers are contending for a similar lock, throughput can drop shortly.
Choice 2: Atomic operations
Atomic updates are a cleaner resolution in case your infrastructure helps it. As a substitute of breaking operations into learn, modify, and write steps, they delegate operations to the underlying system.
|
counter = atomic_increment(counter) |
Databases, key/worth shops, and a few in-memory programs make this available. Fully removes race by making the replace indivisible.
Choice 3: Idempotent writing with model management
One other method is to make use of model management to detect and reject conflicting updates.
|
# learn by specifying model worth, model = learn counter() # attempt writing success = write_counter(worth + 1, Anticipated model=model) if would not have success: retry() |
That is truly an optimistic lock. If one other agent updates the counter first, the write will fail and be retried with a brand new state.
In actual multi-agent programs, “counters” are hardly ever this easy. It may very well be a doc, a reminiscence retailer, or a workflow state object. However the sample is identical. Splitting reads and writes into a number of steps creates a window the place one other agent can intervene.
Closing that window by locks, atomic operations, or race detection is the core of dealing with actual race situations.
remaining ideas
Race situations in multi-agent programs are manageable, however require intentional design. The programs which might be in a position to deal with this stuff aren’t simply fortunate with their timing. These assume that concurrency will trigger issues and plan accordingly.
Idempotent operations, event-driven communication, good locks, and correct queue administration usually are not overdesigned. These are baselines for pipelines the place brokers are anticipated to work in parallel with out interfering with one another. When you get these fundamentals proper, the remainder turns into rather more predictable.

{kind=link}