


Constructing efficient reward features might help you customise Amazon Nova fashions to your particular wants, with AWS Lambda offering the scalable, cost-effective basis. Lambda’s serverless structure helps you to give attention to defining high quality standards whereas it handles the computational infrastructure.
Amazon Nova presents a number of customization approaches, with Reinforcement fine-tuning (RFT) standing out for its capacity to show fashions desired behaviors by means of iterative suggestions. Not like Supervised fine-tuning (SFT) that requires 1000’s of labeled examples with annotated reasoning paths, RFT learns from analysis alerts on remaining outputs. On the coronary heart of RFT lies the reward perform—a scoring mechanism that guides the mannequin towards higher responses.
This publish demonstrates how Lambda allows scalable, cost-effective reward features for Amazon Nova customization. You’ll study to decide on between Reinforcement Studying through Verifiable Rewards (RLVR) for objectively verifiable duties and Reinforcement Studying through AI Suggestions (RLAIF) for subjective analysis, design multi-dimensional reward techniques that enable you to forestall reward hacking, optimize Lambda features for coaching scale, and monitor reward distributions with Amazon CloudWatch. Working code examples and deployment steering are included that can assist you begin experimenting.
Constructing code-based rewards utilizing AWS Lambda
You’ve got a number of pathways to customise basis fashions, every suited to totally different situations. SFT excels when you’ve gotten clear input-output examples and need to train particular response patterns—it’s notably efficient for duties like classification, named entity recognition, or adapting fashions to domain-specific terminology and formatting conventions. SFT works effectively when the specified habits might be demonstrated by means of examples, making it perfect for educating constant type, construction, or factual information switch.Nonetheless, some customization challenges require a special strategy. When functions want fashions to stability a number of high quality dimensions concurrently—like customer support responses that should be correct, empathetic, concise, and brand-aligned concurrently —or when creating 1000’s of annotated reasoning paths proves impractical, reinforcement-based strategies supply a greater different. RFT addresses these situations by studying from analysis alerts slightly than requiring exhaustive labeled demonstrations of right reasoning processes.
AWS Lambda-based reward features simplifies this by means of feedback-based studying. As a substitute of displaying the mannequin 1000’s of efficient examples, you present prompts and outline analysis logic that scores responses—then the mannequin learns to enhance by means of iterative suggestions. This strategy requires fewer labelled examples whereas supplying you with exact management over desired behaviors. Multi-dimensional scoring captures nuanced high quality standards that forestall fashions from exploiting shortcuts, whereas Lambda’s serverless structure handles variable coaching workloads with out infrastructure administration. The result’s Nova customization that’s accessible to builders with out deep machine studying experience, but versatile sufficient for stylish manufacturing use instances.
How AWS Lambda based mostly rewards work
The RFT structure makes use of AWS Lambda as a serverless reward evaluator that integrates with Amazon Nova coaching pipeline, creating an suggestions loop that guides mannequin studying. The method begins when your coaching job generates candidate responses from the Nova mannequin for every coaching immediate. These responses circulate to your Lambda perform, which evaluates their high quality throughout dimensions like correctness, security, formatting, and conciseness. The perform then returns scalar numerical scores—sometimes within the -1 to 1 vary as a finest follow. Greater scores information the mannequin to bolster the behaviors that produced them, whereas decrease scores information it away from patterns that led to poor responses. This cycle repeats 1000’s of instances all through coaching, progressively shaping the mannequin towards responses that constantly earn increased rewards.
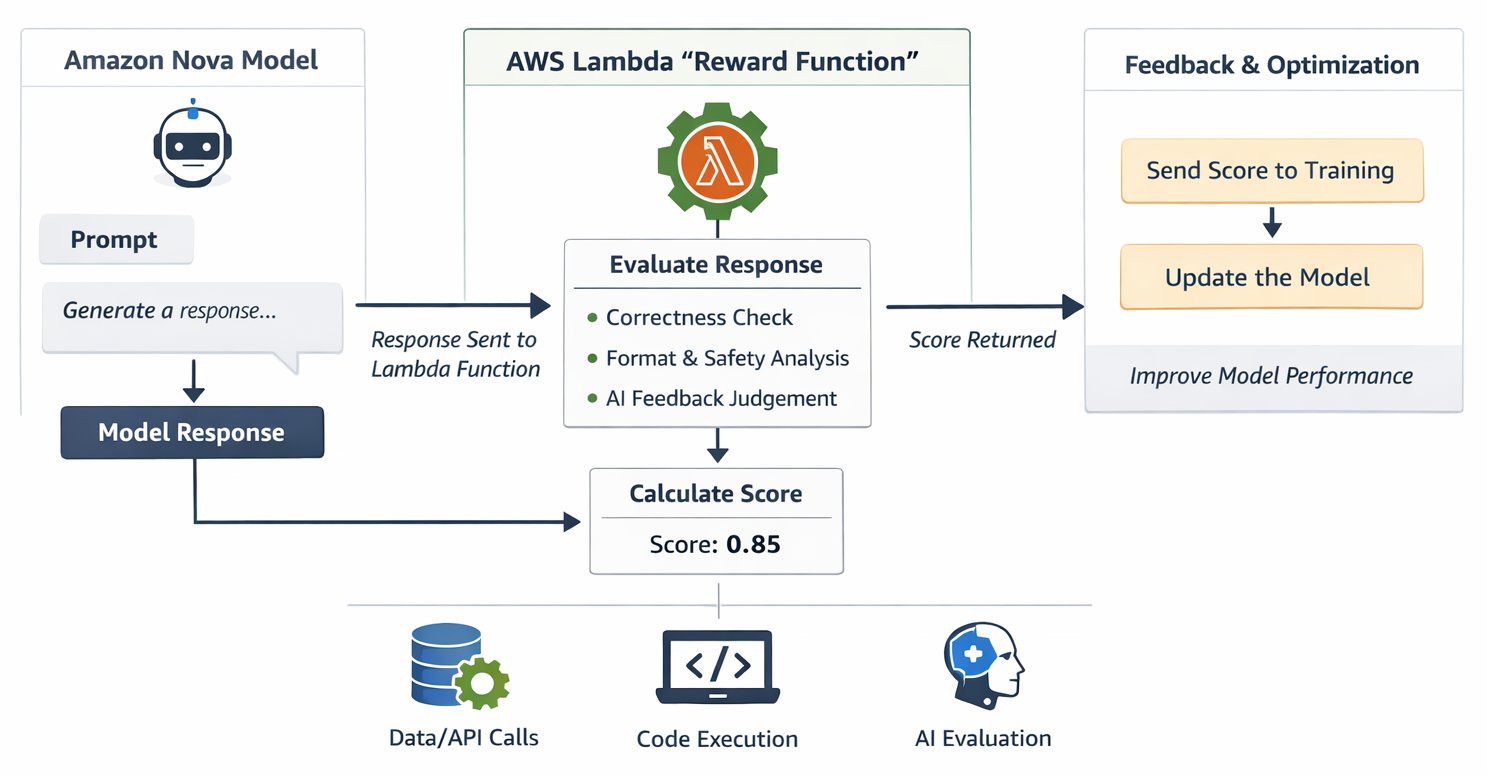
The structure brings collectively a number of AWS providers in a cohesive customization answer. Lambda executes your reward analysis logic with automated scaling that handles variable coaching calls for with out requiring you to provision or handle infrastructure. Amazon Bedrock offers the totally managed RFT expertise with built-in Lambda help, providing AI decide fashions for RLAIF implementations by means of a easy Software Programming Interface (API). For groups needing superior coaching management, Amazon SageMaker AI presents choices by means of Amazon SageMaker AI Coaching Jobs and Amazon SageMaker AI HyperPod, each supporting the identical Lambda-based reward features. Amazon CloudWatch screens Lambda efficiency in real-time, logs detailed debugging details about reward distributions and coaching progress, and triggers alerts when points come up. On the basis sits Amazon Nova itself—fashions with customization recipes optimized throughout all kinds of use instances that reply successfully to the suggestions alerts your reward features present
This serverless strategy makes Nova customization cost-effective. Lambda robotically scales from dealing with 10 concurrent evaluations per second throughout preliminary experimentation to 400+ evaluations throughout manufacturing coaching, with out infrastructure tuning or capability planning. Your single Lambda perform can assess a number of high quality standards concurrently, offering the nuanced, multi-dimensional suggestions that stops fashions from exploiting simplistic scoring shortcuts. The structure helps each goal verification by means of RLVR—operating code in opposition to take a look at instances or validating structured outputs—and subjective judgment by means of RLAIF, the place AI fashions consider qualities like tone and helpfulness. You pay just for precise compute time throughout analysis with millisecond billing granularity, making experimentation inexpensive whereas holding manufacturing prices proportional to coaching depth. Maybe most respected for iterative growth, Lambda features save as reusable “Evaluator” belongings in Amazon SageMaker AI Studio, enabling you to keep up constant high quality measurement as you refine your customization technique throughout a number of coaching runs.
Choosing the proper rewards mechanism
The inspiration of profitable RFT is choosing the proper suggestions mechanism. Two complementary approaches serve totally different use instances: RLVR and RLAIF are two strategies used to fine-tune giant language fashions (LLMs) after their preliminary coaching. Their main distinction lies in how they supply suggestions to the mannequin.
RLVR (Reinforcement Studying through Verifiable Rewards)
RLVR makes use of deterministic code to confirm goal correctness. RLVR is designed for domains the place a “right” reply might be mathematically or logically verified, for instance, fixing a math downside. RLVR makes use of deterministic features to grade outputs as an alternative of a discovered reward mannequin. RLVR fails for duties like inventive writing or model voice the place no absolute floor fact exists.
- Greatest for: Code technology, mathematical reasoning, structured output duties
- Instance: Working generated code in opposition to take a look at instances, validating API responses, checking calculation accuracy
- Benefit: Dependable, auditable, deterministic scoring
RLVR features programmatically confirm correctness in opposition to floor fact. Right here on this instance doing sentiment evaluation.
from typing import Checklist
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Non-compulsory
def extract_answer_nova(solution_str: str) -> Non-compulsory[str]:
"""Extract sentiment polarity from Nova-formatted response for chABSA."""
# First attempt to extract from answer block
solution_match = re.search(r'<|begin_of_solution|>(.*?)<|end_of_solution|>', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# Search for boxed format in answer block
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# Fallback: search for boxed format anyplace
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# Final resort: search for sentiment key phrases
solution_lower = solution_str.decrease()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(reply: str) -> str:
"""Normalize reply for comparability."""
return reply.strip().decrease()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
rating: float = 1.0,
data_source: str="chabsa",
extra_info: Non-compulsory[dict] = None
) -> float:
"""chABSA scoring perform with VeRL-compatible signature."""
reply = extract_answer_nova(solution_str)
if reply is None:
return 0.0
# Parse ground_truth JSON to get the reply
gt_answer = ground_truth.get("reply", ground_truth)
clean_answer = normalize_answer(reply)
clean_ground_truth = normalize_answer(gt_answer)
return rating if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""Reward service."""
id: str
aggregate_reward_score: float
def lambda_handler(occasion, context):
scores: Checklist[RewardOutput] = []
samples = occasion
for pattern in samples:
# Extract the bottom fact key. Within the present dataset it is reply
print("Pattern: ", json.dumps(pattern, indent=2))
ground_truth = pattern["reference_answer"]
idx = "no id"
# print(pattern)
if not "id" in pattern:
print(f"ID is None/empty for pattern: {pattern}")
else:
idx = pattern["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
if not "messages" in pattern:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
# Extract reply from floor fact dict
if ground_truth is None:
print(f"No reply present in floor fact for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
# Get completion from final message (assistant message)
last_message = pattern["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Final message will not be from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
if not "content material" in last_message:
print(f"Completion textual content is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]
Your RLVR perform ought to incorporate three vital design components for efficient coaching. First, create a easy reward panorama by awarding partial credit score—for instance, offering format_score factors for correct response construction even when the ultimate reply is wrong. This prevents binary scoring cliffs that make studying tough. Second, implement good extraction logic with a number of parsing methods that deal with numerous response codecs gracefully. Third, validate inputs at each step utilizing defensive coding practices that forestall crashes from malformed inputs
RLAIF (Reinforcement Studying through AI Suggestions)
RLAIF makes use of AI fashions as judges for subjective analysis. RLAIF achieves efficiency corresponding to RLHF(Reinforcement Studying through Human Suggestions) whereas being considerably sooner and less expensive. Right here is an instance RLVR lambda perform code for sentiment classification.
- Greatest for: Artistic writing, summarization, model voice alignment, helpfulness
- Instance: Evaluating response tone, assessing content material high quality, judging consumer intent alignment
- Benefit: Scalable human-like judgment with out handbook labeling prices
RLAIF features delegate judgment to succesful AI fashions as proven on this pattern code beneath
import json
import re
import time
import boto3
from typing import Checklist, Dict, Any, Non-compulsory
bedrock_runtime = boto3.shopper('bedrock-runtime', region_name="us-east-1")
JUDGE_MODEL_ID = "<jude_model_id>" #Substitute with decide mannequin id of your curiosity
SYSTEM_PROMPT = "You could output ONLY a quantity between 0.0 and 1.0. No explanations, no textual content, simply the quantity."
JUDGE_PROMPT_TEMPLATE = """Evaluate the next two responses and price how related they're on a scale of 0.0 to 1.0, the place:
- 1.0 means the responses are semantically equal (identical that means, even when worded in another way)
- 0.5 means the responses are partially related
- 0.0 means the responses are fully totally different or contradictory
Response A: {response_a}
Response B: {response_b}
Output ONLY a quantity between 0.0 and 1.0. No explanations."""
def extract_solution_nova(solution_str: str, methodology: str = "strict") -> Non-compulsory[str]:
"""Extract answer from Nova-formatted response."""
assert methodology in ["strict", "flexible"]
if methodology == "strict":
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].substitute(",", "").substitute("$", "")
return final_answer
return None
elif methodology == "versatile":
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
numbers = re.findall(r"(-?[0-9.,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].substitute(",", "").substitute("$", "")
reply = re.findall(r"(-?[0-9.,]+)", solution_str)
if len(reply) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(reply):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Name Bedrock to match responses and return similarity rating."""
immediate = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for try in vary(max_retries):
attempt:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
rating = float(output)
return max(0.0, min(1.0, rating))
besides Exception as e:
if "ThrottlingException" in str(e) and try < max_retries - 1:
time.sleep(2 ** try)
else:
return 0.0
return 0.0
def compute_score(id: str, solution_str: str, ground_truth: str) -> float:
"""Compute rating for prepare.jsonl format."""
reply = extract_solution_nova(solution_str=solution_str, methodology="versatile")
if reply is None:
return 0.0
clean_answer = str(reply)
clean_ground_truth = str(ground_truth)
rating = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return rating
def lambda_grader(samples: Checklist[Dict[str, Any]]) -> Checklist[Dict[str, Any]]:
"""
Course of samples from prepare.jsonl format and return scores.
Args:
samples: Checklist of dictionaries with messages and metadata
Returns:
Checklist of dictionaries with reward scores
"""
outcomes = []
for pattern in samples:
sample_id = pattern.get("id", "unknown")
# Extract reference reply from metadata or high stage
metadata = pattern.get("metadata", {})
reference_answer = metadata.get("reference_answer", pattern.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("reply", "")
else:
ground_truth = str(reference_answer)
# Get assistant response from messages
messages = pattern.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("function") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content material", "")
break
if not assistant_response or not ground_truth:
outcomes.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
proceed
# Compute rating
rating = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
outcomes.append({
"id": sample_id,
"aggregate_reward_score": rating,
"metrics_list": [
{
"name": "semantic_similarity",
"value": score,
"type": "Reward"
}
]
})
return outcomes
def lambda_handler(occasion, context):
return lambda_grader(occasion)
Whereas implementing RLAIF perform think about shopper initialization with international variables to cut back total invocations latency. Deal with throttling exceptions gracefully to keep away from coaching interruptions. Use temperature 0.0 for deterministic decide scores, it helps with mannequin consistency. And supply clear rubric, it helps decide present calibrated scores
Concerns for writing good reward features
To jot down good reward features for RFT, begin easy, create a easy reward panorama (notbinary cliffs), guarantee rewards align with the true objective (keep away from hacking), use dense/shapedrewards for advanced duties, present clear alerts, and make them verifiable and constant.
- Outline Aim Clearly: Know precisely what success seems to be like to your mannequin.
- Easy Reward Panorama: As a substitute of straightforward cross/fail (0 or 1), use easy, dense
reward alerts that present partial credit score for being “heading in the right direction”. This granularfeedback helps the mannequin study from incremental enhancements slightly than ready fora excellent response. For advanced, multi-step duties, present rewards for intermediateprogress (shaping) slightly than simply the ultimate end result (sparse).
- Making Rewards Multi-Dimensional: A single scalar reward is just too simply hacked. The
reward ought to consider mannequin efficiency from a number of dimensions: e.g. correctness,faithfulness to enter, security/coverage alignment, formatting, and conciseness, and many others.
- Reward Hacking Prevention: Make sure the mannequin can’t get excessive rewards by means of shortcuts
(e.g., fortunate guesses, repetitive actions); make the duty guess-proof.
- Use Verifiable Rubrics: For goal duties like code technology or math, use automated
graders that execute the code or parse particular reply tags (e.g., <reply>) to verifycorrectness with no human within the loop.
- Implement LLM Judges for Subjective Duties: When programmatic code can’t decide
the reply (e.g., summarization), use a separate, succesful mannequin as an “LLM Decide”. Youmust consider this decide first to make sure its grades are secure and aligned with humanpreferences.
Optimizing your reward perform execution throughout the coaching loop
As soon as your reward perform works accurately, optimization helps you prepare sooner whereas controlling prices. This part covers strategies to think about to your workloads. Optimization strategies compound of their affect—a well-configured Lambda perform with applicable batch sizing, concurrency settings, chilly begin mitigation, and error dealing with can consider responses ten instances sooner than a naive implementation whereas costing considerably much less and offering higher coaching reliability. The funding in optimization early within the customization course of pays dividends all through coaching by lowering iteration time, reducing compute prices, and catching points earlier than they require costly retraining.
- Guarantee IAM permissions are accurately configured earlier than you begin coaching
Dependency Administration and Permissions
- Learn how to add dependencies: you may both bundle them instantly together with your code in a deployment bundle (.zip file) or use Lambda layers to handle dependencies individually out of your core logic.
- Making a .zip deployment bundle (see directions right here)
- Utilizing Lambda layers (see directions right here)
- Amazon Bedrock entry for RLAIF: the execution function for the Lambda perform ought to have entry to Amazon Bedrock for LLM API name.
Use layers for dependencies shared throughout a number of features. Use deployment packages for function-specific logic.Connect AWS Identification and Entry Administration (IAM) permissions to Lambda execution function for RLAIF implementations. Following the precept of least privilege, scope the Useful resource ARN to the particular basis mannequin you might be utilizing as a decide slightly than utilizing a wildcard
- Understanding platform variations and which platform may be extra appropriate to your wants
Optimizing Lambda-based reward features requires understanding how totally different coaching environments work together with serverless analysis and the way architectural decisions affect throughput, latency, and value. The optimization panorama differs considerably between synchronous and asynchronous processing fashions, making environment-specific tuning important for production-scale customization.
Amazon SageMaker AI Coaching Jobs make use of synchronous processing that generates rollouts first earlier than evaluating them in parallel batches. This structure creates distinct optimization alternatives round batch sizing and concurrency administration. The lambda_batch_size parameter, defaulting to 64, determines what number of samples Lambda evaluates in a single invocation—tune this increased for quick reward features that full in milliseconds, however decrease it for advanced evaluations approaching timeout thresholds. The lambda_concurrency parameter controls parallel execution, with the default of 12 concurrent invocations usually proving conservative for manufacturing workloads. Quick reward features profit from considerably increased concurrency, typically reaching 50 or extra simultaneous executions, although you have to monitor account-level Lambda concurrency limits that cap whole concurrent executions throughout your features in a area.
Amazon SageMaker AI HyperPod takes a essentially totally different strategy by means of asynchronous processing that generates and evaluates samples individually slightly than in giant batches. This sample-by-sample structure naturally helps increased throughput, with default configurations dealing with 400 transactions per second by means of Lambda with out particular tuning. Scaling past this baseline requires coordinated adjustment of HyperPod recipe parameters—particularly proc_num and rollout_worker_replicas that management employee parallelism. When scaling staff aggressively, think about rising generation_replicas proportionally to stop technology from changing into the bottleneck whereas analysis capability sits idle.
- Optimization of reward perform utilizing concurrency of Lambda
Lambda configuration instantly impacts coaching pace and reliability:
-
- Timeout Configuration: Set timeout to 60 seconds (default is simply 3 seconds), this offers headroom for RLAIF decide calls or advanced RLVR logic
- Reminiscence Allocation: Set reminiscence to 512 MB (default is 128 MB), accelerated CPU improves response time efficiency
- Chilly begin mitigation
Chilly begin mitigation prevents latency spikes that may sluggish coaching and enhance prices. Preserve deployment packages below 50MB to attenuate initialization time—this usually means excluding pointless dependencies and utilizing Lambda layers for big shared libraries. Reuse connections throughout invocations by initializing purchasers just like the Amazon Bedrock runtime shopper in international scope slightly than contained in the handler perform, permitting the Lambda execution setting to keep up these connections between invocations. Profile your perform utilizing Lambda Insights to establish efficiency bottlenecks. Cache ceaselessly accessed knowledge similar to analysis rubrics, validation guidelines, or configuration parameters in international scope so Lambda masses them as soon as per container slightly than on each invocation. This sample of worldwide initialization with handler-level execution proves notably efficient for Lambda features dealing with 1000’s of evaluations throughout coaching.
- Optimizing RLAIF decide fashions
For RLAIF implementations utilizing Amazon Bedrock fashions as judges, there’s an necessary trade-off to think about. Bigger fashions present extra dependable judgments however have decrease throughput, whereas smaller fashions supply higher throughput however could also be much less succesful—choose the smallest decide mannequin ample to your job to maximise throughput. Profile decide consistency earlier than scaling to full coaching.
Throughput Administration:
-
- Monitor Amazon Bedrock throttling limits at area stage
- Think about Amazon SageMaker AI endpoints for decide fashions. It presents increased throughput however at the moment restricted to open weight and Nova fashions
- Batch a number of evaluations per API name when doable
- Account for concurrent coaching jobs sharing Amazon Bedrock quota
- Guaranteeing your Lambda reward perform is error tolerant and corrective
Actual-world techniques encounter failures—community hiccups, momentary service unavailability, or occasional Lambda timeouts. Fairly than letting a single failure derail your complete coaching job, we’ve constructed sturdy retry mechanisms that deal with timeouts, Lambda failures, and transient errors robotically. The system intelligently retries failed reward calculations with exponential backoff, giving momentary points time to resolve. If a name fails even after three retries, you’ll obtain a transparent, actionable error message pinpointing the particular difficulty—whether or not it’s a timeout, a permissions downside, or a bug in your reward logic. This transparency helps you to rapidly establish and repair issues with out sifting by means of cryptic logs.
- Iterative CloudWatch debugging and catching any indicators of errors early on
Visibility into your coaching course of is crucial for each monitoring progress and troubleshooting points. We robotically log complete info to CloudWatch for each stage of the coaching pipeline: every coaching step’s metrics – together with step clever coaching reward scores and detailed execution traces for every pipeline element. This granular logging makes it simple to trace coaching progress in real-time, confirm that your reward perform is scoring responses as anticipated, and rapidly diagnose points after they come up. For instance, for those who discover coaching isn’t enhancing, you may study the reward distributions in CloudWatch to see in case your perform is returning largely zeros or if there’s inadequate sign
CloudWatch offers complete visibility into reward perform efficiency. Listed here are few helpful Amazon CloudWatch Insights Queries for the answer
Conclusion
Lambda-based reward features unlock Amazon Nova customization for organizations that want exact behavioral management with out large labeled datasets and improved reasoning. This strategy delivers important benefits by means of flexibility, scalability, and cost-effectiveness that streamline your mannequin customization course of.The structure permits RLVR to deal with goal verification duties whereas RLAIF helps with subjective judgment for nuanced high quality assessments. Organizations can use them individually or mix them for complete analysis that captures each factual accuracy and stylistic preferences. Scalability emerges naturally from the serverless basis, robotically dealing with variable coaching workloads from early experimentation by means of production-scale customization. Price-effectiveness flows instantly from this design—organizations pay just for precise analysis compute, with coaching jobs finishing sooner because of optimized Lambda concurrency and environment friendly reward calculation.The mixture of Amazon Nova basis fashions, Lambda serverless scalability, and Amazon Bedrock’s managed customization infrastructure makes reinforcement fine-tuning extra accessible no matter organizational scale. Begin experimenting with the pattern code on this weblog, and start customizing Amazon Nova fashions that ship precisely the behaviors your functions want.
Acknowledgements
Particular due to Eric Grudzien and Anupam Dewan for his or her evaluation and contributions to this publish.
Concerning the Authors

{kind=link}