


Generative AI competitors has lengthy been a recreation of “greater is best.” Nonetheless, because the business reaches the boundaries of energy and reminiscence bottlenecks, the dialogue is shifting from uncooked parameter counts to architectural effectivity. The Liquid AI group is main this effort with the discharge of . LFM2-24B-A2Ba 24 billion parameter mannequin that redefines what it is best to anticipate from edge-enabled AI.
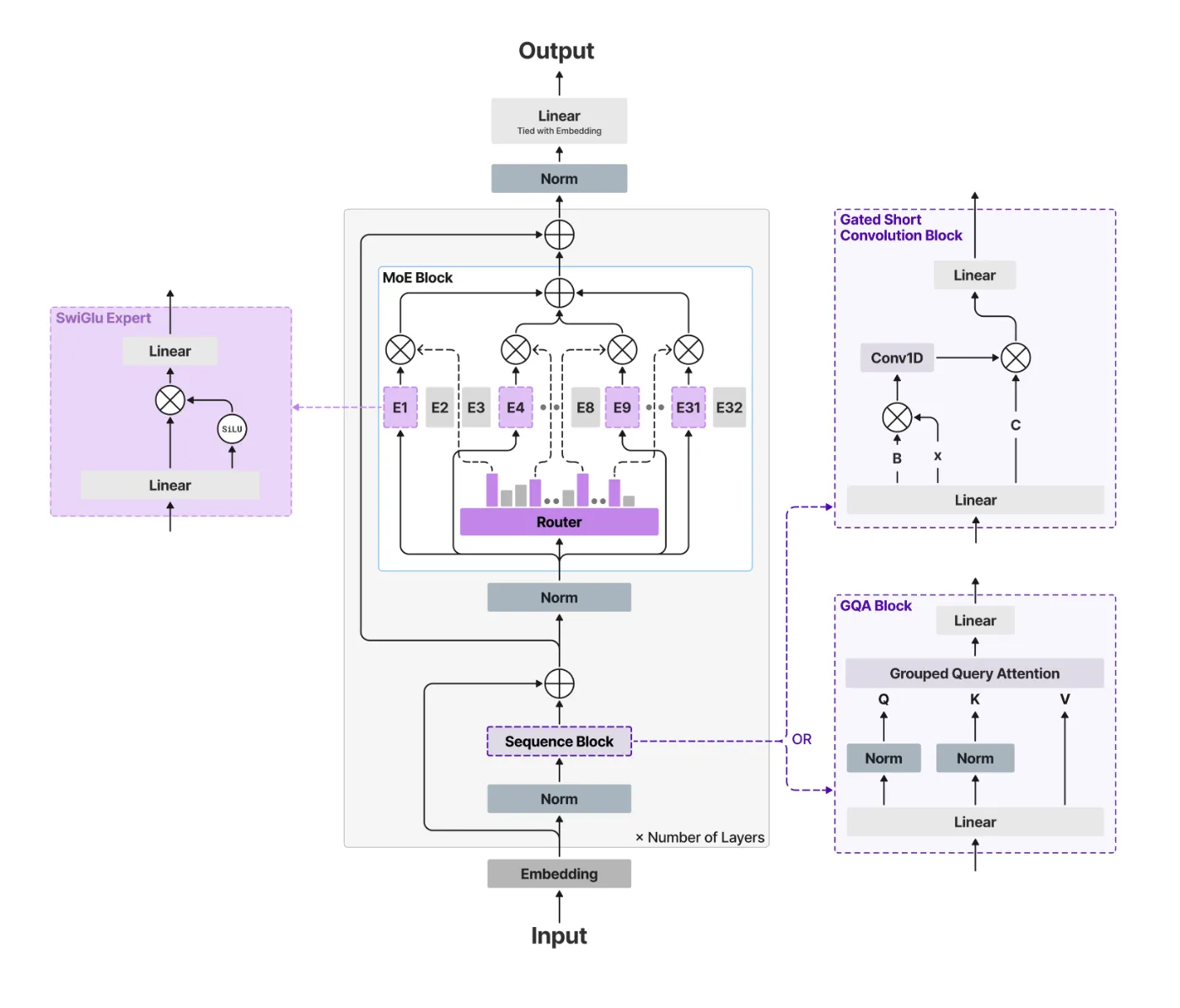
“A2B” structure: 1:3 effectivity
The mannequin identify “A2B” is Consideration to the bottom. Conventional Transformer makes use of Softmax consideration the place all layers scale quadratically (O(N2)) Specify the sequence size. This ends in a big key-value (KV) cache that consumes VRAM.
The Liquid AI group avoids this by utilizing a hybrid construction. of ‘base‘ Layers are environment friendly Gated brief convolutional block,alternatively, ‘Notice‘ Layers are used Grouped question consideration (GQA).
Within the LFM2-24B-A2B configuration, the mannequin makes use of a 1:3 ratio.
- Complete variety of layers: 40
- Convolution block: 30
- Consideration block: 10
By interspersing a small variety of GQA blocks throughout many of the gated convolution layers, this mannequin maintains the high-resolution acquisition and inference of the Transformer whereas sustaining the quick prefill and low reminiscence footprint of linear complexity fashions.
Sparse MoE: 24 billion intelligence on a 2 billion finances
A very powerful level of LFM2-24B-A2B is that Mixture of Specialists (MoE) design. The mannequin comprises 24 billion parameters, however just one is activated. 2.3 billion parameters per token.
It is a main change in deployment. The lively parameter path could be very lean, so the mannequin 32GB RAM. This implies it may be run regionally on high-end client laptops, desktops with built-in GPUs (iGPUs), and devoted NPUs with out the necessity for an information center-grade A100. It successfully gives the data density of a 24B mannequin and the inference velocity and vitality effectivity of a 2B mannequin.
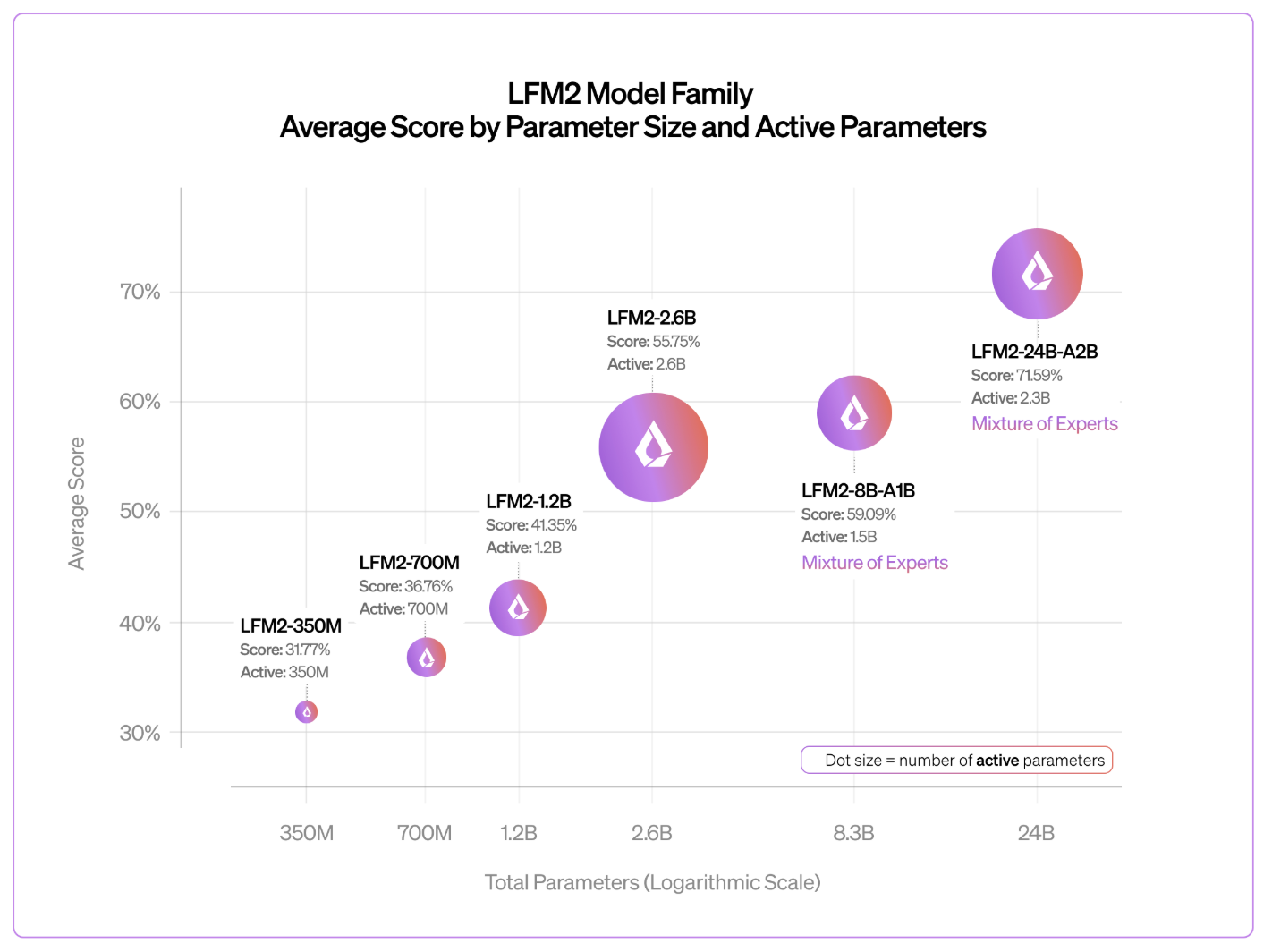
Benchmark: Punchup
The Liquid AI group stories that the LFM2 household follows predictable log-linear scaling habits. Regardless of having fewer lively parameters, the 24B-A2B mannequin constantly outperforms its bigger rivals.
- Logic and reasoning: In a take a look at like GSM8K and Arithmetic-500akin to a dense mannequin twice the scale.
- throughput: Benchmarking on a single NVIDIA H100 utilizing vLLMit has arrived 26.8K whole tokens per second The variety of concurrent requests is 1,024, which is considerably increased than Snowflake. gpt-oss-20b and Quen 3-30B-A3B.
- Lengthy context: The options of the mannequin are 32k Token context window. Optimized for privacy-friendly RAG (search augmented era) pipelines and native doc evaluation.
technical cheat sheet
| property | specification |
| whole parameters | 24 billion |
| lively parameters | 2.3 billion |
| structure | Hybrid (Gated Conversion + GQA) |
| layer | 40 (Base 30 / Consideration 10) |
| context size | 32,768 tokens |
| coaching information | 17 trillion tokens |
| license | LFM Open License v1.0 |
| native assist | llama.cpp, vLLM, SGLang, MLX |
Essential factors
- Hybrid “A2B” structure: The mannequin makes use of a 1:3 ratio. Grouped question consideration (GQA) to Gate brief convolution. By using a linear complexity “base” layer for 30 out of 40 layers, this mannequin achieves a lot sooner prefill and decoding speeds with a considerably lowered reminiscence footprint in comparison with conventional all-attention transformers.
- Sparse MoE effectivity: regardless of having 24 billion parameters in wholethe mannequin simply prompts 2.3 billion parameters per token. This “sparse combination of specialists” design means that you can obtain the inference depth of enormous fashions whereas sustaining the inference latency and vitality effectivity of 2B parameter fashions.
- True edge options: The mannequin optimized by hardware-in-the-loop architectural search is designed to satisfy the next circumstances: 32GB RAM. This makes it totally deployable on consumer-grade {hardware}, akin to laptops with built-in GPUs and NPUs, with out the necessity for costly information heart infrastructure.
- Reducing-edge efficiency: The LFM2-24B-A2B outperforms bigger opponents akin to: Quen 3-30B-A3B and snowflake gpt-oss-20b In throughput. Benchmarks present that it virtually hits 26.8K tokens per second It reveals near-linear scaling and excessive effectivity on lengthy context duties on a single H100. 32,000 token window.
Please examine technical details and model weights. Please be at liberty to observe us too Twitter Remember to hitch us 120,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.


{kind=link}