


The generative AI business has undergone a big transformation from utilizing massive language mannequin (LLM)-driven functions to agentic AI methods, marking a basic shift in how AI capabilities are architected and deployed. Whereas early generative AI functions primarily relied on LLMs to instantly generate textual content and reply to prompts, the business has advanced from these static, prompt-response paradigms towards autonomous agent frameworks to construct dynamic, goal-oriented methods able to device orchestration, iterative problem-solving, and adaptive activity execution in manufacturing environments.
Now we have witnessed this evolution in Amazon; since 2025, there have been hundreds of brokers constructed throughout Amazon organizations. Whereas single-model benchmarks function a vital basis for assessing particular person LLM efficiency in LLM-driven functions, agentic AI methods require a basic shift in analysis methodologies. The brand new paradigm assesses not solely the underlying mannequin efficiency but in addition the emergent behaviors of the whole system, together with the accuracy of device choice selections, the coherence of multi-step reasoning processes, the effectivity of reminiscence retrieval operations, and the general success charges of activity completion throughout manufacturing environments.
On this publish, we current a complete analysis framework for Amazon agentic AI methods that addresses the complexity of agentic AI functions at Amazon via two core elements: a generic analysis workflow that standardizes evaluation procedures throughout various agent implementations, and an agent analysis library that gives systematic measurements and metrics in Amazon Bedrock AgentCore Evaluations, together with Amazon use case-specific analysis approaches and metrics. We additionally share greatest practices and experiences captured throughout engagements with a number of Amazon groups, offering actionable insights for AWS developer communities dealing with related challenges in evaluating and deploying agentic AI methods inside their very own enterprise contexts.
AI agent analysis framework in Amazon
When builders design, develop, and consider AI brokers, they face vital challenges. In contrast to conventional LLM-driven functions that solely generate responses to remoted prompts, AI brokers autonomously pursue targets via multi-step reasoning, device use, and adaptive decision-making throughout multi-turn interactions. Conventional LLM analysis strategies deal with agent methods as black packing containers and consider solely the ultimate consequence, failing to offer enough insights to find out why AI brokers fail or pinpoint the foundation causes. Though a number of particular analysis instruments can be found within the business, builders should navigate amongst them and consolidate outcomes with vital handbook efforts. Moreover, whereas agent improvement frameworks, comparable to Strands Brokers, LangChain, and LangGraph, have built-in analysis modules, builders need a framework-agnostic analysis method quite than being locked into strategies inside a single framework.
Moreover, sturdy self-reflection and error dealing with in AI brokers requires systematic evaluation of how brokers detect, classify, and recuperate from failures throughout the execution lifecycle in reasoning, tool-use, reminiscence dealing with, and motion taking. For instance, the analysis frameworks should measure the agent’s capacity to acknowledge various failure eventualities comparable to inappropriate planning from the reasoning mannequin, invalid device invocations, malformed parameters, sudden device response codecs, authentication failures, and reminiscence retrieval errors. A production-grade agent should show constant error restoration patterns and resilience in sustaining the coherence of person interactions after encountering exceptions.
To fulfill these wants, AI brokers deployed in manufacturing environments at scale require steady monitoring and systematic analysis to promptly detect and mitigate agent decay and efficiency degradation. This calls for that the agent analysis framework streamline the end-to-end course of and supply close to real-time challenge detection, notification, and downside decision. Lastly, incorporating human-in-the-loop (HITL) processes is important to audit analysis outcomes, serving to to make sure the reliability of system outputs.
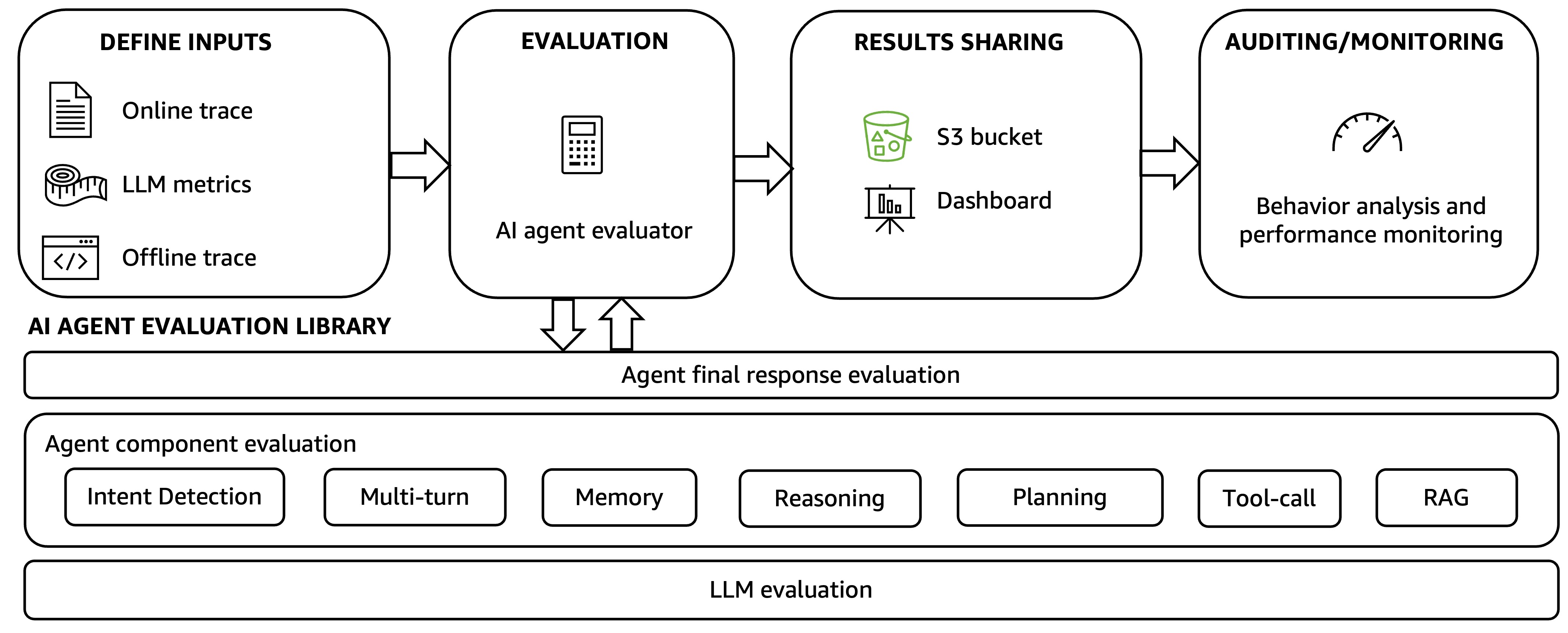
To deal with these challenges, we suggest a holistic agentic AI analysis framework, as proven within the following determine. The framework comprises two key elements: an automatic AI agent analysis workflow and an AI agent analysis library.
The automated AI agent analysis workflow drives the holistic analysis method with 4 steps.
Step 1: Customers outline inputs for analysis, usually hint recordsdata from agent execution. These could be offline traces collected after the agent completes the duty and uploaded to the framework utilizing a unified API entry level or on-line traces the place customers can outline analysis dimensions and metrics.
Step 2: The AI agent analysis library is used to robotically generate default and user-defined analysis metrics. The strategies within the library are described within the subsequent checklist.
Step 3: The analysis outcomes are shared via an Amazon Easy Storage Service (Amazon S3) bucket or a dashboard that visualizes the agent hint observability and analysis outcomes.
Step 4: Outcomes are analyzed via agent efficiency auditing and monitoring. Builders can outline their very own guidelines to ship notifications upon agent efficiency degradation and might take motion to resolve issues. Builders may HITL mechanisms to schedule periodic human audits of agent hint subsets and analysis outcomes, bettering constant agent high quality and efficiency.
The AI agent analysis library operates throughout three layers: calculating and producing analysis metrics for the agent’s closing output, assessing particular person agent elements, and measuring the efficiency of the underlying LLMs that energy the agent.
- Backside layer: Benchmarks a number of basis fashions to pick the suitable fashions powering the AI agent and decide how totally different fashions influence the agent total high quality and latency.
- Center layer: Evaluates the efficiency of the elements of the agent, together with intent detection, multi-turn dialog, reminiscence, LLM reasoning and planning, tool-use, and others. For instance, the center layer determines whether or not the agent understands person intents accurately, how the LLM drives agentic workflow planning via chain-of-thought (CoT) reasoning, whether or not the device choice and execution are aligned with the agentic plan, and if the plan is accomplished efficiently.
- Higher layer: Assesses the agent’s closing response, the duty completion, and whether or not the agent meets the objective outlined within the use case. It additionally covers total duty and security, the prices, and the shopper expertise impacts.
Amazon Bedrock AgentCore Evaluations supplies automated evaluation instruments to measure how nicely your agent or instruments carry out particular duties, deal with edge circumstances, and preserve consistency throughout totally different inputs and contexts. Within the agent analysis library, we present a set of pre-defined analysis metrics for the agent’s closing response and its elements, based mostly on the built-in configurations, evaluators, and metrics of AgentCore Evaluations. We additional prolonged the analysis library with specialised metrics designed for the heterogeneous situation complexity and application-specific necessities of Amazon. The first metrics within the library embrace
- Last response high quality:
- Correctness: The factual accuracy and correctness of an AI assistant’s response to a given activity.
- Faithfulness: Whether or not an AI assistant’s response stays in keeping with the dialog historical past.
- Helpfulness: How successfully an AI assistant’s response helps customers appropriately tackle question and progress towards their targets.
- Response relevance: How nicely an AI assistant’s response addresses the precise query or request.
- Conciseness: How effectively an AI assistant communicates info, for example, whether or not the response is appropriately temporary with out lacking key info.
- Activity completion:
- Purpose success: Did the AI assistant efficiently full all person targets inside a dialog session.
- Purpose accuracy: Compares the output to the bottom fact.
- Instrument use:
- Instrument choice accuracy: Did the AI assistant select the suitable device for a given state of affairs.
- Instrument parameter accuracy: Did the AI assistant accurately use contextual info when making device calls.
- Instrument name error charge: The frequency of failures when an AI assistant makes device calls.
- Multi-turn perform calling accuracy: Are a number of instruments being known as and the way usually the instruments are known as within the appropriate sequence.
- Reminiscence:
- Context retrieval: Assesses the accuracy of findings and surfaces probably the most related contexts for a given question from reminiscence, prioritizing related info based mostly on similarity or rating, and balancing precision and recall.
- Multi-turn:
- Matter adherence classification: If a multi-turn dialog contains a number of matters, assesses whether or not the dialog stays on predefined domains and matters through the interplay.
- Matter adherence refusal: Determines if the AI agent refuse to reply questions on a subject.
- Reasoning:
- Grounding accuracy: Does the mannequin perceive the duty, appropriately choose instruments, and is the CoT aligned with the offered context and information returned by exterior instruments.
- Faithfulness rating: Measures logical consistency throughout the reasoning course of.
- Context rating: Is every step taken by the agent contextually grounded.
- Duty and security:
- Hallucination: Do the outputs align with established information, verifiable information, logical inference, or embrace any parts which can be implausible, deceptive, or completely fictional.
- Toxicity: Do the outputs comprise language, solutions, or attitudes which can be dangerous, offensive, disrespectful, or promote negativity. This embrace content material that is perhaps aggressive, demeaning, bigoted, or excessively essential with out constructive goal.
- Harmfulness: Is there probably dangerous content material in an AI assistant’s response, together with insults, hate speech, violence, inappropriate sexual content material, and stereotyping.
See AgentCore analysis templates for different agent output high quality metrics, or create customized evaluators which can be tailor-made to your particular use circumstances and analysis necessities.
Evaluating real-world agent methods utilized by Amazon
Prior to now few years, Amazon has been working to advance its method in constructing agentic AI functions to deal with complicated enterprise challenges, streamlining enterprise processes, bettering operational effectivity, and optimizing enterprise outcomes—shifting from early experimentation to production-scale deployments throughout a number of enterprise items. These agentic AI functions function at enterprise scale and are deployed throughout AWS infrastructure, remodeling how work will get completed throughout international operations inside Amazon. On this part, we introduce a number of real-world agentic AI use circumstances from Amazon, to show how Amazon groups enhance AI agent efficiency via holistic analysis utilizing the framework mentioned within the earlier part.
Evaluating tool-use within the Amazon purchasing assistant AI agent
To ship a easy purchasing expertise to Amazon shoppers, the Amazon purchasing assistant can seamlessly work together with quite a few APIs and internet providers from underlying Amazon methods, as proven within the following determine. The AI agent must onboard a whole lot, typically hundreds, of instruments from underlying Amazon methods to have interaction in long-running multi-turn conversations with the buyer. The agent makes use of these instruments to ship a customized expertise that features buyer profiling, product and stock discovery, and order placement. Nonetheless, manually onboarding so many enterprise APIs and internet providers to an AI agent is a cumbersome course of that usually takes months to finish.
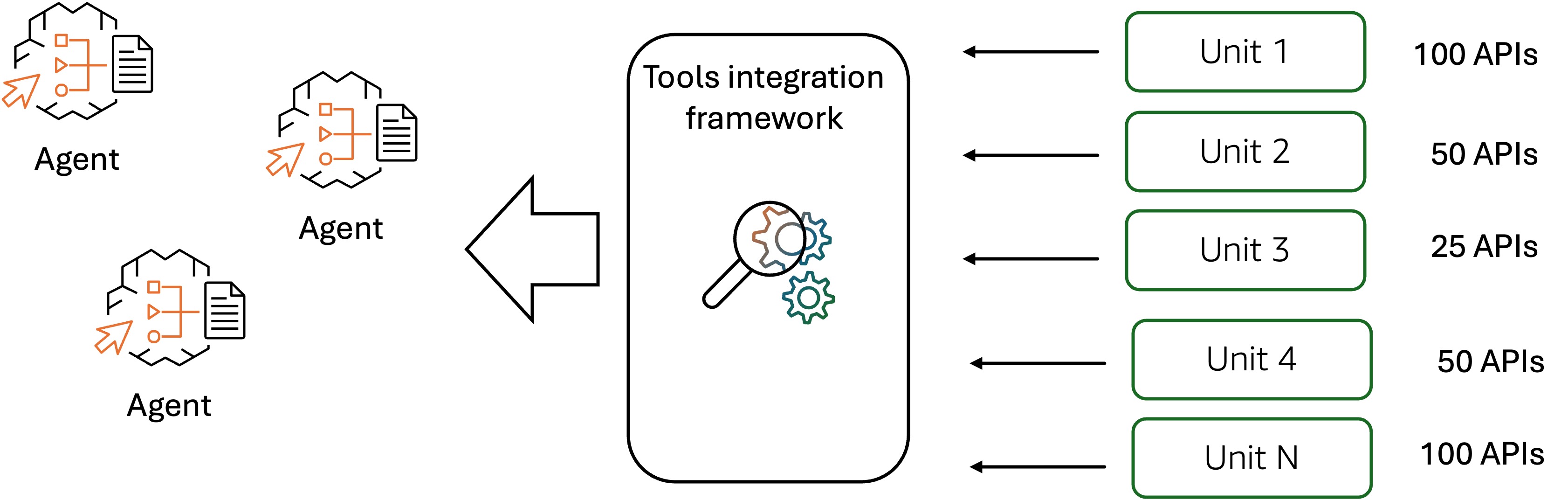
Remodeling legacy APIs and internet providers into agent-compatible instruments requires the systematic definition of structured schemas and semantic descriptions for the endpoints of the API and internet providers, enabling the agent’s reasoning and planning mechanisms to precisely establish and choose contextually acceptable instruments throughout activity execution. Poorly outlined device schemas and imprecise semantic descriptions lead to faulty device choice throughout agent runtime, resulting in the invocation of irrelevant APIs that unnecessarily broaden the context window, enhance inference latency, and escalate computational prices via redundant LLM calls. To deal with these challenges, Amazon outlined cross-organizational requirements for device schema and outline formalization, making a governance framework that specifies necessary compliance necessities for all builder groups concerned in device improvement and agent integration. This standardization initiative establishes uniform specs for device interfaces, parameter definitions, functionality descriptions, and utilization constraints, serving to to make sure that instruments developed throughout various organizational items preserve constant structural patterns and semantic readability to supply dependable agent-tool interactions. All builder groups engaged in device improvement and agent integration should conform to those architectural specs, which prescribe standardized codecs for device signatures, enter validation schemas, output contracts, and human-readable documentation. This helps guarantee consistency in device illustration throughout the enterprise agentic methods. Moreover, manually defining device schemas and descriptions for a whole lot or hundreds of instruments represents a big engineering burden, and the complexity escalates considerably when a number of APIs require coordinated orchestration to perform composite duties. Amazon builders applied an API self-onboarding system that makes use of LLMs to automate the era of standardized device schemas and descriptions. This considerably improved the effectivity in onboarding massive numbers of APIs and providers into agent-compatible instruments, accelerating integration timelines and lowering handbook engineering overhead. To guage the tool-selection and tool-use after integration of the APIs is accomplished, Amazon groups created golden datasets for regression testing. The datasets are generated synthetically utilizing LLMs from historic API invocation logs upon person queries. Utilizing pre-defined tool-selection and tool-use metrics comparable to device choice accuracy, device parameter accuracy, and multi-turn perform name accuracy, the Amazon builders can systematically consider the purchasing assistant AI agent’s functionality to accurately establish acceptable instruments, populate their parameters with correct values, and preserve coherent device invocation sequences throughout conversational turns. Because the agent continues to evolve, the flexibility to quickly and reliably combine new APIs as instruments within the agent and consider the tool-use efficiency turns into more and more essential. The target evaluation of agent’s useful reliability in manufacturing environments successfully reduces improvement overhead whereas sustaining sturdy efficiency within the agentic AI functions.
Evaluating person intent detection within the Amazon customer support AI agent
Within the Amazon customer-service panorama, AI brokers are instrumental in dealing with buyer inquiries and resolving points. On the coronary heart of those methods lies a vital functionality: an orchestration AI agent utilizing it’s reasoning mannequin to precisely detect buyer intent, which determines whether or not a buyer’s question is accurately understood and routed to the suitable specialised resolver applied by agent instruments or subagents, as proven within the following determine. The stakes are excessive with regards to intent detection accuracy. When the customer support agent misinterprets a buyer’s intent, it could set off a cascade of issues: queries get routed to the improper specialised resolvers, prospects obtain irrelevant responses, and frustration builds. This impacts buyer expertise and results in elevated operational prices as extra prospects search intervention from human brokers.
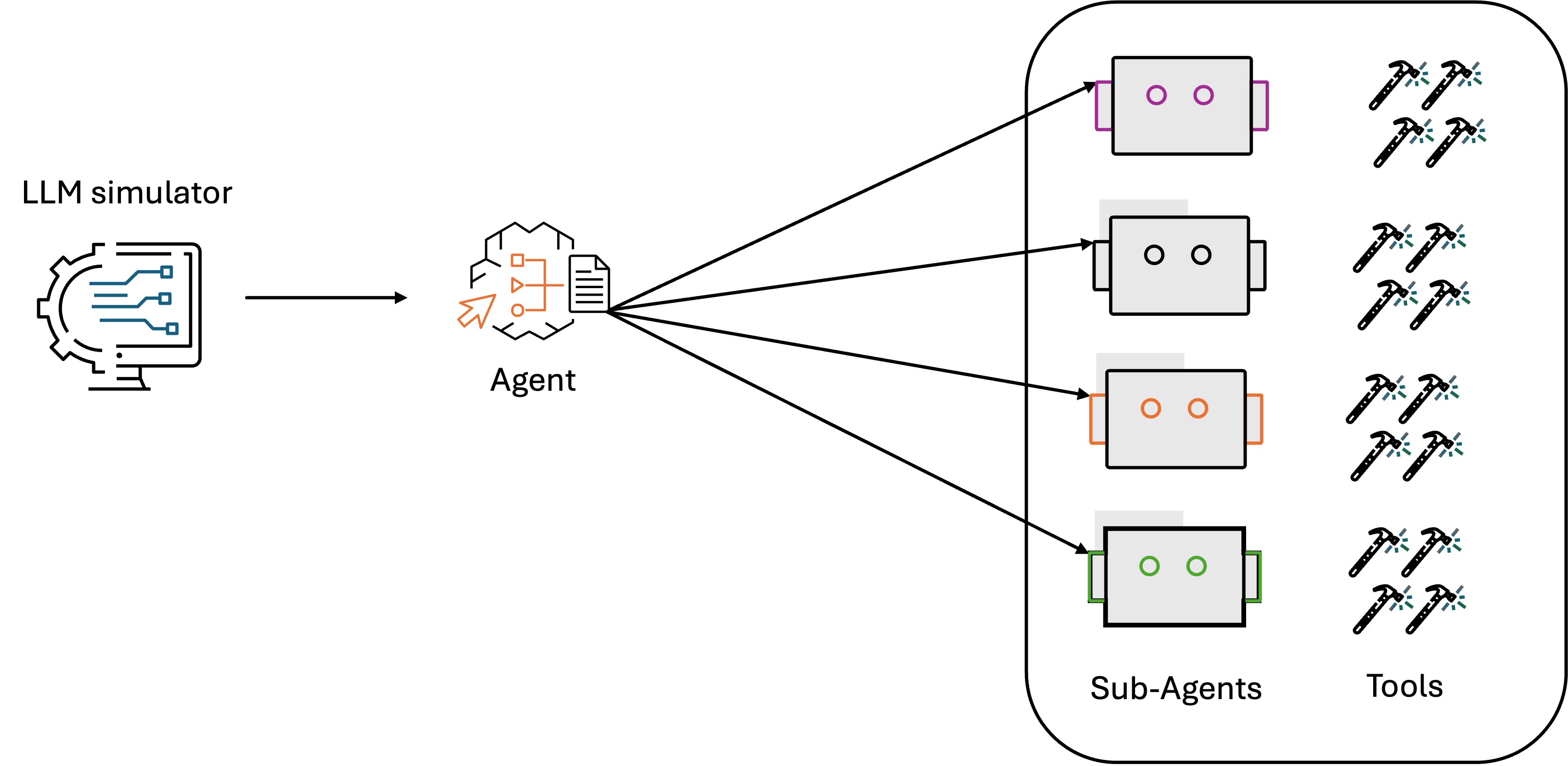
To guage the agent’s reasoning functionality for intent detection, the Amazon staff developed an LLM simulator that makes use of LLM pushed digital buyer personas to simulate various person eventualities and interactions. The analysis is primarily targeted on correctness of the intent generated by the orchestration agent and routing to the proper subagent. The simulation dataset comprises a set of person question and floor fact intent pairs collected from anonymized historic buyer interactions. Utilizing the simulator, the orchestration agent generates the intents upon the person queries within the simulation dataset. By evaluating the agent response intent to the bottom fact intent, we are able to validate if the agent-generated intents adjust to the bottom fact.
Along with the intent correctness, the analysis covers the duty completion—the agent’s closing response and intent decision—as the ultimate objective of the customer support duties. For the multi-turn dialog, we additionally embrace the metrics of matter adherence classification and matter adherence refusal to assist guarantee conversational coherence and person expertise high quality. As AI customer support methods proceed to evolve, the significance of sturdy agent reasoning analysis for person intent detection solely grows, the influence extends past speedy buyer satisfaction. It additionally optimizes customer support operation effectivity and repair supply prices, and so maximizes the return on AI investments.
Evaluating multi-agent methods at Amazon
As enterprises more and more confront multifaceted challenges in complicated enterprise environments, starting from cross-functional workflow orchestration to real-time decision-making below uncertainty, Amazon groups are progressively adopting multi-agent system architectures that decompose monolithic AI options into specialised, collaborative brokers able to distributed reasoning, dynamic activity allocation, and adaptive problem-solving at scale. One instance is the Amazon vendor assistant AI agent that encompasses collaborations amongst a number of AI brokers, depicted within the following move chart.
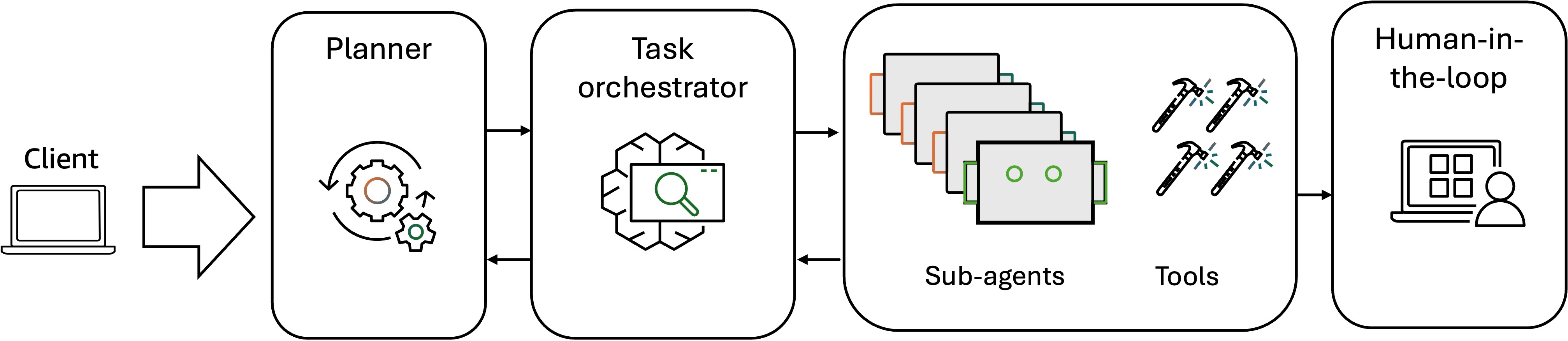
The agentic workflow, starting with an LLM planner and activity orchestrator, receives person requests, decomposes complicated duties into specialised subtasks, and intelligently assigns every subtask to probably the most acceptable underlying agent based mostly on their capabilities and present workload. The underlying brokers then function autonomously, executing their assigned duties through the use of their specialised instruments, reasoning capabilities, and area experience to finish goals with out requiring steady oversight from the orchestrator. Upon activity completion the specialised brokers talk again to the orchestration agent, reporting activity standing updates, completion confirmations, intermediate outcomes, or escalation requests after they encounter eventualities past their operational boundaries. The orchestration agent aggregates these responses, screens total progress, handles dependencies between subtasks, and synthesizes the collective outputs right into a coherent closing consequence that addresses the unique person request. To guage this multi-agent collaboration course of, the analysis workflow accounts for each particular person agent efficiency and the general collective system dynamics. Along with evaluating the general activity execution high quality and efficiency of specialised brokers in activity completion, reasoning, tool-use and reminiscence retrieval, we additionally must measure the interagent communication patterns, coordination effectivity, and activity handoff accuracy. For this, Amazon groups use the metrics such because the planning rating (profitable subtask task to subagents), communication rating (interagent communication messages for subtask completion), and collaboration success charge (share of profitable sub-task completion). In multi-agent methods analysis, HITL turns into essential due to the elevated complexity and potential for sudden emergent behaviors that automated metrics would possibly fail to seize. Human intervention within the analysis workflow supplies important oversight for assessing inter-agent communication to establish coordination failure in particular edge circumstances, evaluating the appropriateness of agent specialization and whether or not activity decomposition aligns with agent capabilities, and validating potential battle decision methods when brokers produce contradictory suggestions. It additionally helps guarantee logical consistency when a number of brokers contribute to a single resolution, and that the collective agent habits serves the supposed enterprise goal. These are the dimensions which can be troublesome to quantify via automated metrics alone however are essential for manufacturing deployment success.
Classes realized and greatest practices
By way of intensive engagements with Amazon product and engineering groups deploying agentic AI methods in manufacturing environments, we’ve got recognized essential classes realized and established greatest practices that tackle the distinctive challenges of evaluating autonomous agent architectures at scale.
- Holistic analysis throughout a number of dimensions: Agentic software analysis should lengthen past conventional accuracy metrics to embody a complete evaluation framework that covers agent high quality, efficiency, duty, and price. High quality analysis contains measuring reasoning coherence, device choice accuracy, and activity completion success charges throughout various eventualities. Efficiency evaluation captures latency, throughput, and useful resource utilization below manufacturing workloads. Duty analysis addresses security, toxicity, bias mitigation, hallucination detection, and guardrails to align with organizational insurance policies and regulatory necessities. Value evaluation quantifies each direct bills together with mannequin inference, device invocation, information processing, and oblique prices comparable to human efforts and error remediation. This multi-dimensional method helps guarantee holistic optimization throughout balanced trade-offs.
- Use case and application-specific analysis: Moreover the standardized metrics mentioned within the earlier sections, application-specific analysis metrics additionally contribute to the general software evaluation. For example, customer support functions require metrics comparable to buyer satisfaction scores, first-contact decision charges, and sentiment evaluation scores to measure closing enterprise outcomes. This method requires shut collaboration with area consultants to outline significant success standards, outline acceptable metrics, and create analysis datasets that replicate real-world operational complexity to finish the evaluation course of.
- Human-in-the-loop (HITL) as a essential analysis part: As mentioned within the multi-agent system analysis case, HITL is indispensable, significantly for high-stakes resolution eventualities. It supplies important analysis of agent reasoning chains, the coherence of multi-step workflows, and the alignment of agent habits with enterprise necessities. HITL additionally helps present floor fact labels for constructing golden testing datasets, and calibration of LLM-as-a-judge within the automated evaluator to align with human preferences.
- Steady analysis in manufacturing environments: It’s important to keep up high quality as a result of the pre-deployment analysis won’t totally seize the efficiency traits. Additionally, manufacturing analysis screens real-world efficiency throughout various person behaviors, utilization patterns, and edge circumstances not represented earlier than manufacturing deployment to establish efficiency degradation over time. You’ll be able to observe key metrics via operational dashboards, implement alert thresholds, automate anomaly detection course of, and set up suggestions loops. When the problems are detected, you can begin mannequin retraining, refine context engineering, and align along with your final enterprise goals.
Conclusion
As AI methods turn into more and more complicated, the significance of a radical AI agent analysis method can’t be overstated. By way of holistic analysis throughout high quality, efficiency, duty, and price dimensions, along with steady manufacturing monitoring and human-in-the-loop validation, the complete lifecycle of agentic AI deployment from improvement to manufacturing could be addressed. You’ll be able to study from the introduced examples, greatest practices, and classes realized on this publish—lots of which can be found in Amazon Bedrock AgentCore Evaluations—to speed up your individual agentic AI initiatives whereas avoiding frequent pitfalls in analysis design and implementation.
In regards to the authors

{kind=link}
{kind=link}