


Everybody talks about LLM, however immediately’s AI ecosystem is rather more than simply language fashions. Behind the scenes, a whole household of specialised architectures is quietly remodeling how machines understand, plan, act on, partition, symbolize, and even effectively execute ideas on small units. Every of those fashions solves a distinct a part of the intelligence puzzle, and collectively they type the subsequent technology of AI techniques.
This text describes 5 main gamers: Giant Language Mannequin (LLM), Imaginative and prescient Language Mannequin (VLM), Mixture of Experience (MoE), Giant Scale Motion Mannequin (LAM), and Small Language Mannequin (SLM).
LLM takes in textual content, splits it into tokens, converts these tokens into embeddings, passes them to a layer of transformers, and generates textual content again. Fashions reminiscent of ChatGPT, Claude, Gemini, and Llama all observe this primary course of.
On the coronary heart of LLM is a deep studying mannequin skilled on giant quantities of textual content information. This coaching will allow you to know the language, generate responses, summarize data, write code, reply questions, and carry out a variety of duties. They use a transformer structure that is excellent at dealing with lengthy sequences and capturing complicated patterns in languages.
LLM is now extensively accessible via shopper instruments and assistants, from OpenAI’s ChatGPT and Anthropic’s Claude to Meta’s Llama mannequin, Microsoft Copilot, and Google’s Gemini and BERT/PaLM households. They’re the inspiration of contemporary AI functions because of their versatility and ease of use.
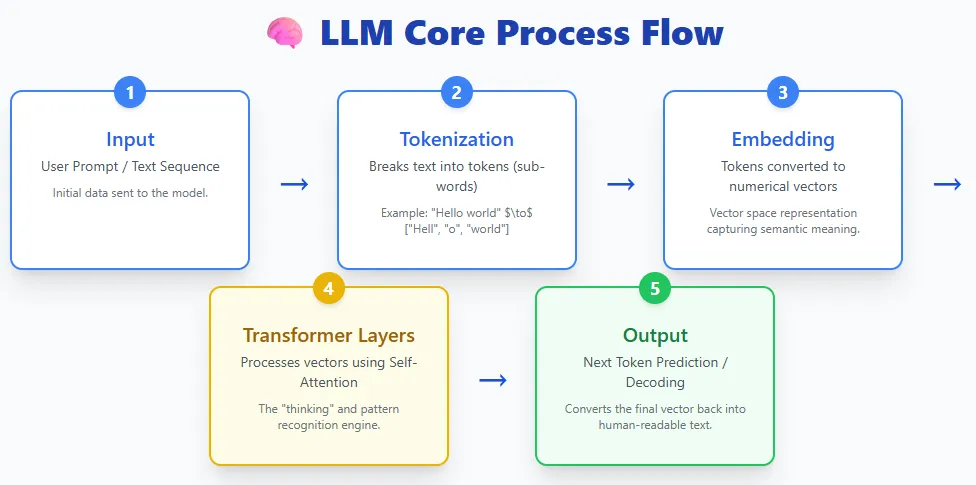
VLM combines two worlds.
- Imaginative and prescient encoder to course of photos or movies
- Textual content encoder that processes languages
Each streams meet in a multimodal processor and the language mannequin produces the ultimate output.
Examples embrace GPT-4V, Gemini Professional Imaginative and prescient, and LLaVA.
A VLM is actually a big language mannequin given the flexibility to see. By mixing visible and textual representations, these fashions can perceive photos, interpret paperwork, reply questions on photographs, clarify movies, and extra.
Conventional pc imaginative and prescient fashions are skilled for one slender job, reminiscent of classifying cats and canines or extracting textual content from photos, and can’t generalize past their coaching class. In the event you want new lessons or duties, you’ll have to retrain them from scratch.
VLM removes this limitation. Educated on big datasets of photos, movies, and textual content, they will carry out many visible duties in zero photographs by merely following pure language directions. Every thing from picture captioning and OCR to visible reasoning and multi-step doc understanding could be executed with out task-specific retraining.
This flexibility makes VLM one of the highly effective advances in trendy AI.
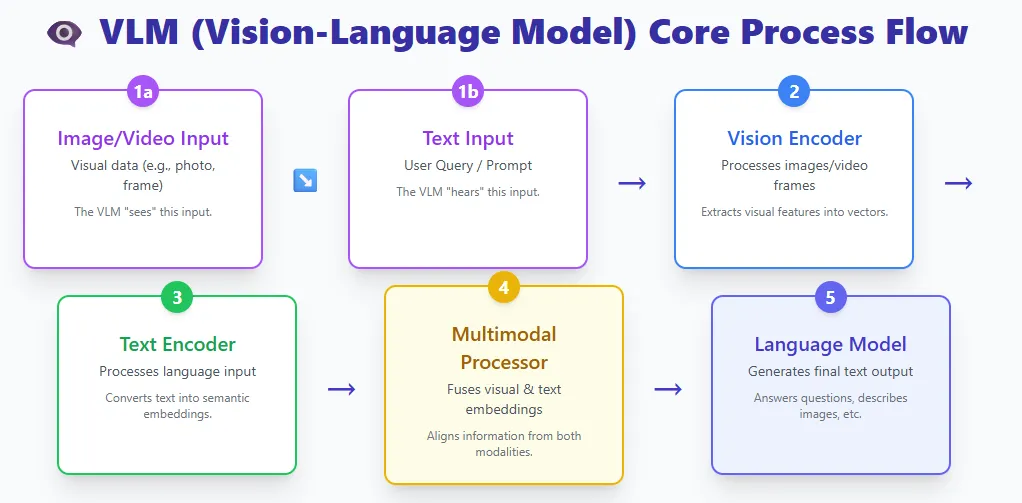
The professional combination mannequin is constructed on the usual Transformer structure, however introduces vital upgrades. As a substitute of 1 feedforward community per layer, we use many smaller professional networks and activate solely a small variety of professional networks per token. This makes the MoE mannequin extremely environment friendly whereas providing excessive capability.
In a daily transformer, all tokens undergo the identical feedforward community. That’s, all parameters are used for all tokens. The MoE layer replaces this with a pool of consultants, and the router decides which professional will deal with every token (top-Okay choice). In consequence, a MoE mannequin might include a a lot bigger variety of complete parameters, however solely a small fraction of them could be computed at a time, making the computations sparse.
For instance, Mixtral 8×7B has over 46B parameters, however every token makes use of solely about 13B.
This design considerably reduces inference prices. Relatively than scaling by making the mannequin deeper or wider (which will increase FLOPs), MoE fashions scale by including extra consultants, growing capability with out growing compute per token. Because of this MoE is claimed to have “greater brains at decrease runtime prices.”
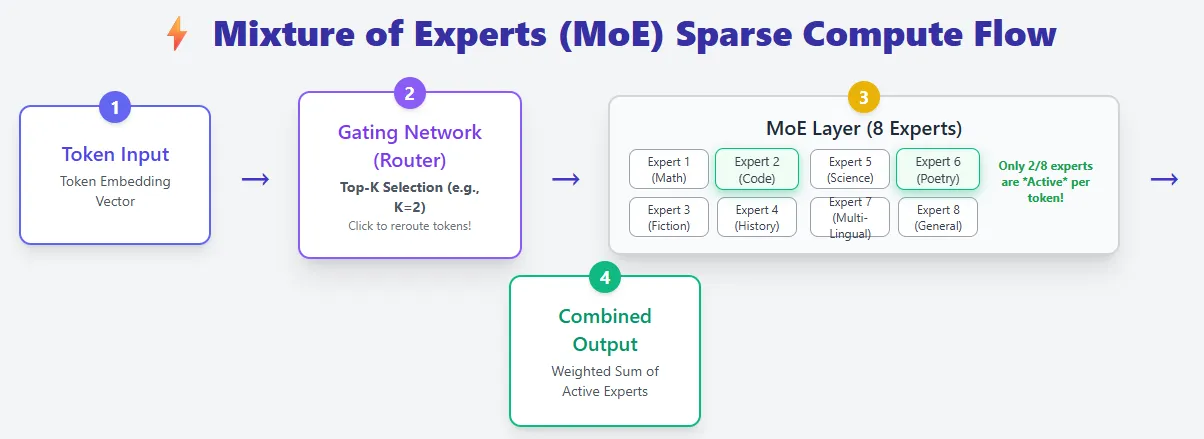
Giant-scale motion fashions transcend textual content technology to show intent into motion. Extra than simply answering questions, LAM can perceive what the consumer desires, break down the duty into steps, plan the required actions, and execute them in the actual world or on a pc.
A typical LAM pipeline contains:
- Recognition – Perceive consumer enter
- Intent recognition – determine what the consumer is making an attempt to perform
- Process decomposition – breaking down targets into actionable steps
- Motion planning + reminiscence – use previous and present conditions to decide on the proper sequence of actions
- Execution – execute duties autonomously
Examples embrace Rabbit R1, Microsoft’s UFO framework, and Claude Pc Use. All of those can work together with the app, navigate the interface, and full duties in your behalf.
LAM is skilled on an enormous dataset of actual consumer actions, giving it the flexibility to behave quite than simply reply, reminiscent of reserving a room, filling out a type, organizing information, and executing multi-step workflows. This strikes AI from a passive assistant to an lively agent able to making complicated real-time selections.
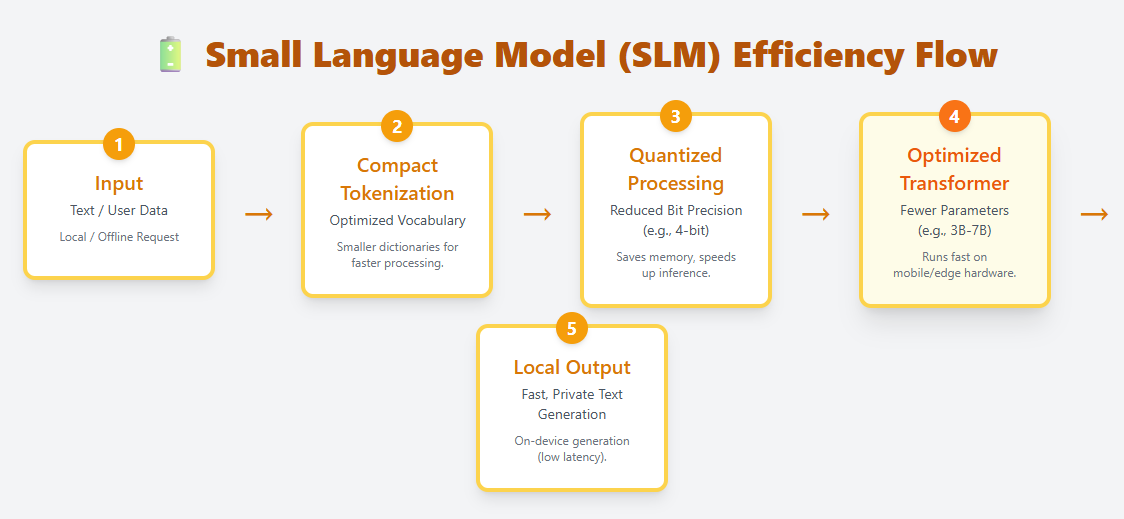
SLM is a light-weight language mannequin designed to run effectively on edge units, cellular {hardware}, and different resource-constrained environments. Permits native on-device deployment utilizing compact tokenization, optimized transformer layers, and aggressive quantization. Examples embrace Phi-3, Gemma, Mistral 7B, and Llama 3.2 1B.
Not like LLM, which has tons of of billions of parameters, SLM sometimes ranges from tens of millions to billions. Regardless of its small dimension, it might probably perceive and generate pure language, making it helpful for chatting, summarizing, translating, and automating duties with out the necessity for cloud computing.
SLM requires a lot much less reminiscence and compute, making it best for:
- cellular app
- IoT and edge units
- Offline or privateness delicate eventualities
- Low-latency functions the place cloud calls are too gradual
SLM represents a rising shift towards quick, non-public, and cost-effective AI, bringing linguistic intelligence immediately to non-public units.

I’m a Civil Engineering graduate from Jamia Millia Islamia, New Delhi (2022) and have a robust curiosity in information science, particularly neural networks and their functions in varied fields.


{kind=link}