


Zhipu AI has open sourced the GLM-4.6V collection as a pair of imaginative and prescient language fashions that deal with photographs, movies, and instruments as first-class inputs to the agent, quite than as afterthoughts tacked on high of textual content.
Mannequin lineup and context size
There are two fashions within the collection. GLM-4.6V is 106B Parameter-based fashions for cloud and high-performance cluster workloads. GLM-4.6V-Flash is a variant of the 9B parameters tuned for native deployment and low-latency use.
GLM-4.6V extends the coaching context window to 128K tokens. In apply, pages are encoded as photographs and consumed by the visible encoder, so this helps roughly 150 pages of dense paperwork, 200 slide pages, or 1 hour of video in a single go.
Utilizing native multimodal instruments
The primary technical modifications are native Multimodal operate name. Conventional instruments utilized in LLM programs route all the pieces by way of textual content. The picture or web page is first transformed to an outline, the mannequin calls the software with the textual content argument, after which reads the textual content response. This wastes data and will increase latency.
Introducing GLM-4.6V Native multimodal operate name. Photographs, screenshots, and documentation pages are handed immediately as software parameters. The software can return a grid of search outcomes, a graph, a rendered net web page, or a product picture. The mannequin consumes these visible outputs and fuses them with textual content in the identical inference chain. This closes the loop from notion to understanding to execution and explicitly positions it as a bridge between visible notion and executable actions for multimodal brokers.
To assist this, Zhipu AI extends the mannequin context protocol with URL-based multimodal processing. The software receives and returns a URL that identifies a selected picture or body. This avoids file dimension limitations and permits for exact choice inside a number of picture contexts.
Wealthy textual content content material, net search, front-end replication
The Zhipu AI analysis group describes 4 normal situations.
First, perceive and create wealthy textual content content material. GLM-4.6V reads blended inputs corresponding to papers, experiences, and slide decks and produces output that’s interleaved with structured picture textual content. Perceive textual content, charts, figures, tables, and formulation throughout the similar doc. Throughout era, you possibly can crop related visuals, acquire exterior photographs via instruments, after which carry out a visible audit step that filters out low-quality photographs and composes the ultimate article with inline figures.
The second is visible net search.. This mannequin can detect person intent, plan which search instruments to invoke, and mix text-to-image and image-to-text searches. It then arranges the captured photographs and textual content, selects related proof, and outputs a structured reply, corresponding to a visible comparability of merchandise or places.
Third, front-end replication and visible interplay.. GLM-4.6V is tailor-made for design-to-coding workflows. Rebuild pixel-accurate HTML, CSS, and JavaScript from UI screenshots. Builders can mark areas on the screenshot and situation directions in pure language, corresponding to shifting this button to the left or altering the background of this card. The mannequin maps these directions to code and returns an up to date snippet.
Fourth, understanding multimodal paperwork in lengthy contexts.. GLM-4.6V can learn a number of doc inputs as much as a 128K token context restrict by treating pages as photographs. The researchers report how the mannequin processed monetary experiences from 4 publicly traded corporations, extracted core metrics to create a comparability desk, and summarized a whole soccer match whereas retaining the power to reply questions on particular targets and timestamps.
structure, information, reinforcement studying
The GLM-4.6V mannequin belongs to the GLM-V household and relies on the GLM-4.5V and GLM-4.1V-Pondering technical experiences. The analysis group highlights three key expertise parts.
First, modeling lengthy sequences. GLM-4.6V extends the coaching context window to 128K tokens and performs steady pre-training on a big lengthy context picture textual content corpus. We use Glyph’s compression coordination concept to permit visible tokens to carry dense data aligned with linguistic tokens.
Second, bettering world information. Zhipu AI group provides 1 billion multimodal notion and world information datasets throughout pre-training. It covers layered encyclopedia ideas and on a regular basis visible entities. The said aim is to enhance each fundamental recognition and completeness of cross-modal query answering, in addition to benchmarking.
Third, information synthesis and augmentation MCP by brokers. The analysis group generates large-scale artificial traces by which the mannequin calls instruments, processes visible output, and iterates on plans. These prolong MCP with URL-based multimodal processing and interleaved output mechanisms. The era stack follows the sequence of draft, picture choice, and ultimate ending. The mannequin can autonomously invoke crop and search instruments between these phases to place the picture on the applicable place within the output.
Device invocation is a part of the aim of reinforcement studying. GLM-4.6V makes use of RL to plan, comply with instructions, and coordinate format adherence in complicated software chains.
efficiency
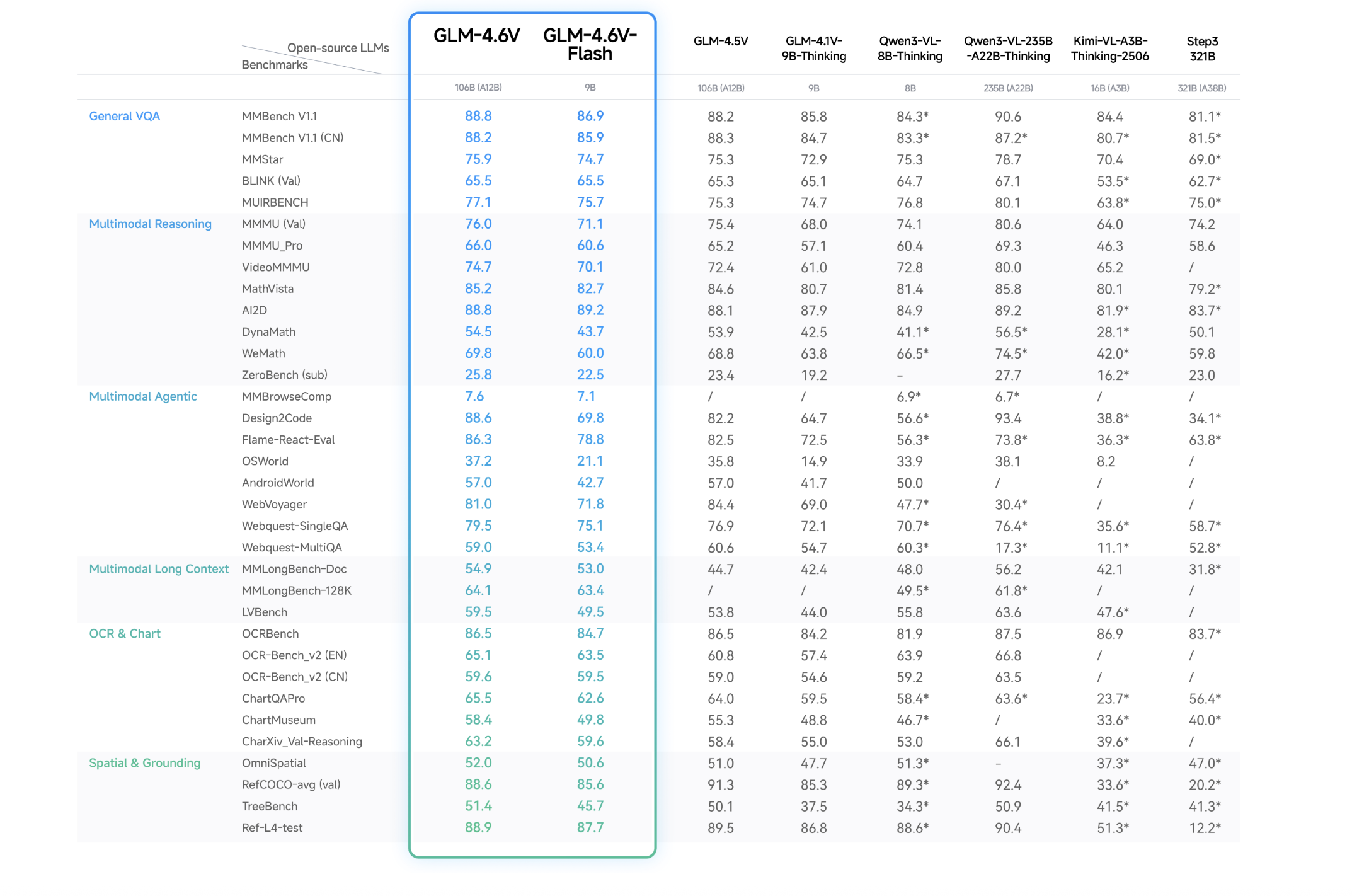
Vital factors
- GLM-4.6V is a 106B multimodal basis mannequin with 128K token coaching contexts, and GLM-4.6V-Flash is a 9B variant optimized for native and low-latency use.
- Each fashions assist native multimodal operate calls, permitting instruments to immediately eat and return photographs, video frames, and doc pages, and join visible recognition to executable actions on the agent.
- GLM-4.6V is skilled for multimodal understanding and interleaved era of lengthy contexts, permitting it to learn massive blended doc units and output structured textual content with inline diagrams and tool-selected photographs in a single go.
- The collection achieves state-of-the-art efficiency on key multimodal benchmarks at related parameter scales and is launched as open supply weights underneath the MIT license in Hugging Face and ModelScope.
Please verify HF model card and technical details. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to comply with us too Twitter Do not forget to hitch us 100,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a synthetic intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per thirty days, which reveals its recognition amongst viewers.

{kind=link}