


Extracting structured knowledge from paperwork like invoices, receipts, and types is a persistent enterprise problem. Variations in format, structure, language, and vendor make standardization tough, and handbook knowledge entry is sluggish, error-prone, and unscalable. Conventional optical character recognition (OCR) and rule-based techniques usually fall brief in dealing with this complexity. As an illustration, a regional financial institution may have to course of 1000’s of disparate paperwork—mortgage functions, tax returns, pay stubs, and IDs—the place handbook strategies create bottlenecks and enhance the danger of error. Clever doc processing (IDP) goals to resolve these challenges through the use of AI to categorise paperwork, extract or derive related data, and validate the extracted knowledge to make use of it in enterprise processes. One among its core targets is to transform unstructured or semi-structured paperwork into usable, structured codecs similar to JSON, which then comprise particular fields, tables, or different structured goal data. The goal construction must be constant, in order that it may be used as a part of workflows or different downstream enterprise techniques or for reporting and insights era. The next determine exhibits the workflow, which entails ingesting unstructured paperwork (for instance, invoices from a number of distributors with various layouts) and extracting related data. Regardless of variations in key phrases, column names, or codecs throughout paperwork, the system normalizes and outputs the extracted knowledge right into a constant, structured JSON format.
Imaginative and prescient language fashions (VLMs) mark a revolutionary development in IDP. VLMs combine giant language fashions (LLMs) with specialised picture encoders, creating really multi-modal AI capabilities of each textual reasoning and visible interpretation. Not like conventional doc processing instruments, VLMs course of paperwork extra holistically—concurrently analyzing textual content content material, doc structure, spatial relationships, and visible components in a way that extra carefully resembles human comprehension. This strategy permits VLMs to extract that means from paperwork with unprecedented accuracy and contextual understanding. For readers inquisitive about exploring the foundations of this know-how, Sebastian Raschka’s submit—Understanding Multimodal LLMs—affords a superb primer on multimodal LLMs and their capabilities.
This submit has 4 most important sections that mirror the first contributions of our work and embrace:
- An outline of the assorted IDP approaches accessible, together with the choice (our really useful resolution) for fine-tuning as a scalable strategy.
- Pattern code for fine-tuning VLMs for document-to-JSON conversion utilizing Amazon SageMaker AI and the SWIFT framework, a light-weight toolkit for fine-tuning varied giant fashions.
- Growing an analysis framework to evaluate efficiency processing structured knowledge.
- A dialogue of the potential deployment choices, together with an specific instance for deploying the fine-tuned adapter.
SageMaker AI is a totally managed service to construct, prepare and deploy fashions at scale. On this submit, we use SageMaker AI to fine-tune the VLMs and deploy them for each batch and real-time inference.
Stipulations
Earlier than you start, be sure you have the next arrange so to efficiently observe the steps outlined on this submit and the accompanying GitHub repository:
- AWS account: You want an energetic AWS account with permissions to create and handle sources in SageMaker AI, Amazon Easy Storage Service (Amazon S3), and Amazon Elastic Container Registry (Amazon ECR).
- IAM permissions: Your IAM person or position should have enough permissions. For manufacturing setups, observe the precept of least privilege as described in safety finest practices in IAM. For a sandbox setup we recommend the next roles:
- Full entry to Amazon SageMaker AI (for instance,
AmazonSageMakerFullAccess). - Learn/write entry to S3 buckets for storing datasets and mannequin artifacts.
- Permissions to push and pull Docker photographs from Amazon ECR (for instance,
AmazonEC2ContainerRegistryPowerUser). - If utilizing particular SageMaker occasion sorts, make sure that your service quotas are enough.
- Full entry to Amazon SageMaker AI (for instance,
- GitHub repository: Clone or obtain the venture code from our GitHub repository. This repository comprises the notebooks, scripts, and Docker artifacts referenced on this submit.
- Native surroundings arrange:
- Python: Python 3.10 or larger is really useful.
- AWS CLI: Ensure that the AWS Command Line Interface (AWS CLI) is put in and configured with credentials which have the required permissions.
- Docker: Docker have to be put in and working in your native machine if you happen to plan to construct the customized Docker container for deployment.
- Jupyter Pocket book and Lab: To run the offered notebooks.
- Set up the required Python packages by working
pip set up -r necessities.txtfrom the cloned repository’s root listing.
- Familiarity (really useful):
- Fundamental understanding of Python programming.
- Familiarity with AWS companies, significantly SageMaker AI.
- Conceptual data of LLMs, VLMs, and the container know-how might be helpful.
Overview of doc processing and generative AI approaches
There are various levels of autonomy in clever doc processing. On one finish of the spectrum are absolutely handbook processes: People manually studying paperwork and getting into the data right into a kind utilizing a pc system. Most techniques as we speak are semi-autonomous doc processing options. For instance, a human taking an image of a receipt and importing it to a pc system that robotically extracts a part of the data. The purpose is to get to totally autonomous clever doc processing techniques. This implies decreasing the error price and assessing the use case particular danger of errors. AI is considerably reworking doc processing by enabling larger ranges of automation. A wide range of approaches exist, ranging in complexity and accuracy—from specialised fashions for OCR, to generative AI.
Specialised OCR fashions that don’t depend on generative AI are designed as pre-trained, task-specific ML fashions that excel at extracting structured data similar to tables, types, and key-value pairs from widespread doc sorts like invoices, receipts, and IDs. Amazon Textract is one instance of this kind of service. This service affords excessive accuracy out of the field and requires minimal setup, making it well-suited for workloads the place fundamental textual content extraction is required, and paperwork don’t differ considerably in construction or comprise photographs.
Nevertheless, as you enhance the complexity and variability of paperwork, along with including multimodality, utilizing generative AI will help enhance doc processing pipelines.
Whereas highly effective, making use of general-purpose VLMs or LLMs to doc processing isn’t easy. Efficient immediate engineering is necessary to information the mannequin. Processing giant volumes of paperwork (scaling) requires environment friendly batching and infrastructure. As a result of LLMs are stateless, offering historic context or particular schema necessities for each doc might be cumbersome.
Approaches to clever doc processing that use LLMs or VLMs fall into 4 classes:
- Zero-shot prompting: the inspiration mannequin (FM) receives the results of earlier OCR or a PDF and the directions to carry out the doc processing process.
- Few-shot prompting: the FM receives the results of earlier OCR or a PDF, the directions to carry out the doc processing process, and a few examples.
- Retrieval-augmented few-shot prompting: much like the previous technique, however the examples despatched to the mannequin are chosen dynamically utilizing Retrieval Augmented Technology (RAG).
- Wonderful-tuning VLMs
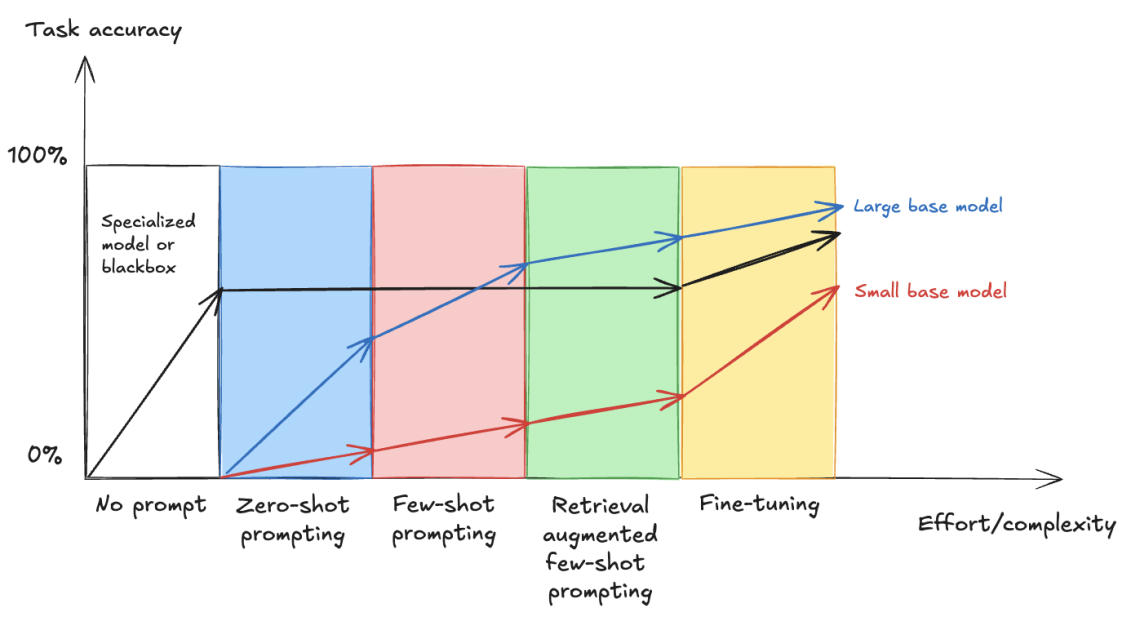
Within the following, you possibly can see the connection between rising effort and complexity and process accuracy, demonstrating how completely different methods—from fundamental immediate engineering to superior fine-tuning—impression the efficiency of enormous and small base fashions in comparison with a specialised resolution (impressed by the weblog submit Comparing LLM fine-tuning strategies)
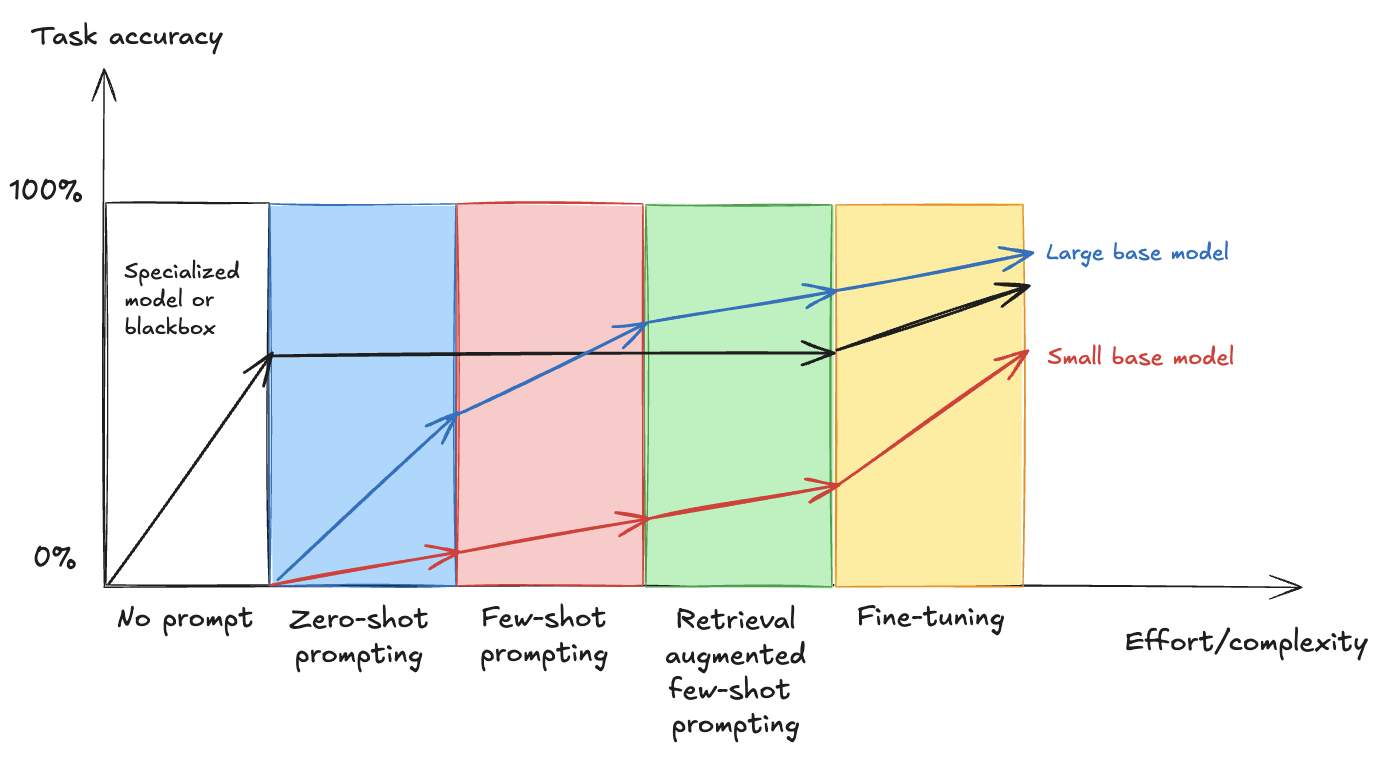
As you progress throughout the horizontal axis, the methods develop in complexity, and as you progress up the vertical axis, you enhance general accuracy. Normally, giant base fashions present higher efficiency than small base fashions within the methods that require immediate engineering, nevertheless as we clarify within the outcomes of this submit, fine-tuning small base fashions can ship related outcomes as fine-tuning giant base fashions for a selected process.
Zero-shot prompting
Zero-shot prompting is a way to make use of language fashions the place the mannequin is given a process with out prior examples or fine-tuning. As a substitute, it depends solely on the immediate’s wording and its pre-trained data to generate a response. In doc processing, this strategy entails giving the mannequin both a picture of a PDF doc, the OCR-extracted textual content from the PDF, or a structured markdown illustration of the doc and offering directions to carry out the doc processing process, along with the specified output format.
Amazon Bedrock Information Automation makes use of zero-shot prompting with generative AI to carry out IDP. You need to use Bedrock Information Automation to automate the transformation of multi-modal knowledge—together with paperwork containing textual content and sophisticated buildings, similar to tables, charts and pictures—into structured codecs. You’ll be able to profit from customization capabilities by means of the creation of blueprints that specify output necessities utilizing pure language or a schema editor. Bedrock Information Automation also can extract bounding bins for the recognized entities and route paperwork appropriately to the right blueprint. These options might be configured and used by means of a single API, making it considerably extra highly effective than a fundamental zero-shot prompting strategy.
Whereas out-of-the-box VLMs can deal with common OCR duties successfully, they usually battle with the distinctive construction and nuances of customized paperwork—similar to invoices from numerous distributors. Though crafting a immediate for a single doc could be easy, the variability throughout lots of of vendor codecs makes immediate iteration a labor-intensive and time-consuming course of.
Few-shot prompting
Transferring to a extra complicated strategy, you will have few-shot prompting, a way used with LLMs the place a small variety of examples are offered inside the immediate to information the mannequin in finishing a selected process. Not like zero-shot prompting, which depends solely on pure language directions, few-shot prompting improves accuracy and consistency by demonstrating the specified input-output habits by means of examples.
One various is to make use of the Amazon Bedrock Converse API to carry out few shot prompting. Converse API gives a constant method to entry LLMs utilizing Amazon Bedrock. It helps turn-based messages between the person and the generative AI mannequin, and permits together with documents as a part of the content material. Another choice is utilizing Amazon SageMaker Jumpstart, which you should use to deploy fashions from suppliers like HuggingFace.
Nevertheless, almost certainly your small business must course of several types of paperwork (for instance, invoices, contracts and hand written notes) and even inside one doc kind there are lots of variations, for instance, there may be not one standardized bill structure and as a substitute every vendor has their very own structure that you simply can’t management. Discovering a single or just a few examples that cowl all of the completely different paperwork you need to course of is difficult.
Retrieval-augmented few-shot prompting
One method to handle the problem of discovering the fitting examples is to dynamically retrieve beforehand processed paperwork as examples and add them to the immediate at runtime (RAG).
You’ll be able to retailer just a few annotated samples in a vector retailer and retrieve them primarily based on the doc that must be processed. Amazon Bedrock Information Bases helps you implement your entire RAG workflow from ingestion to retrieval and immediate augmentation with out having to construct customized integrations to knowledge sources and handle knowledge flows.
This turns the clever doc processing downside right into a search downside, which comes with its personal challenges on methods to enhance the accuracy of the search. Along with methods to scale for a number of sorts of paperwork, the few-shot strategy is dear as a result of each doc processed requires an extended immediate with examples. This leads to an elevated variety of enter tokens.
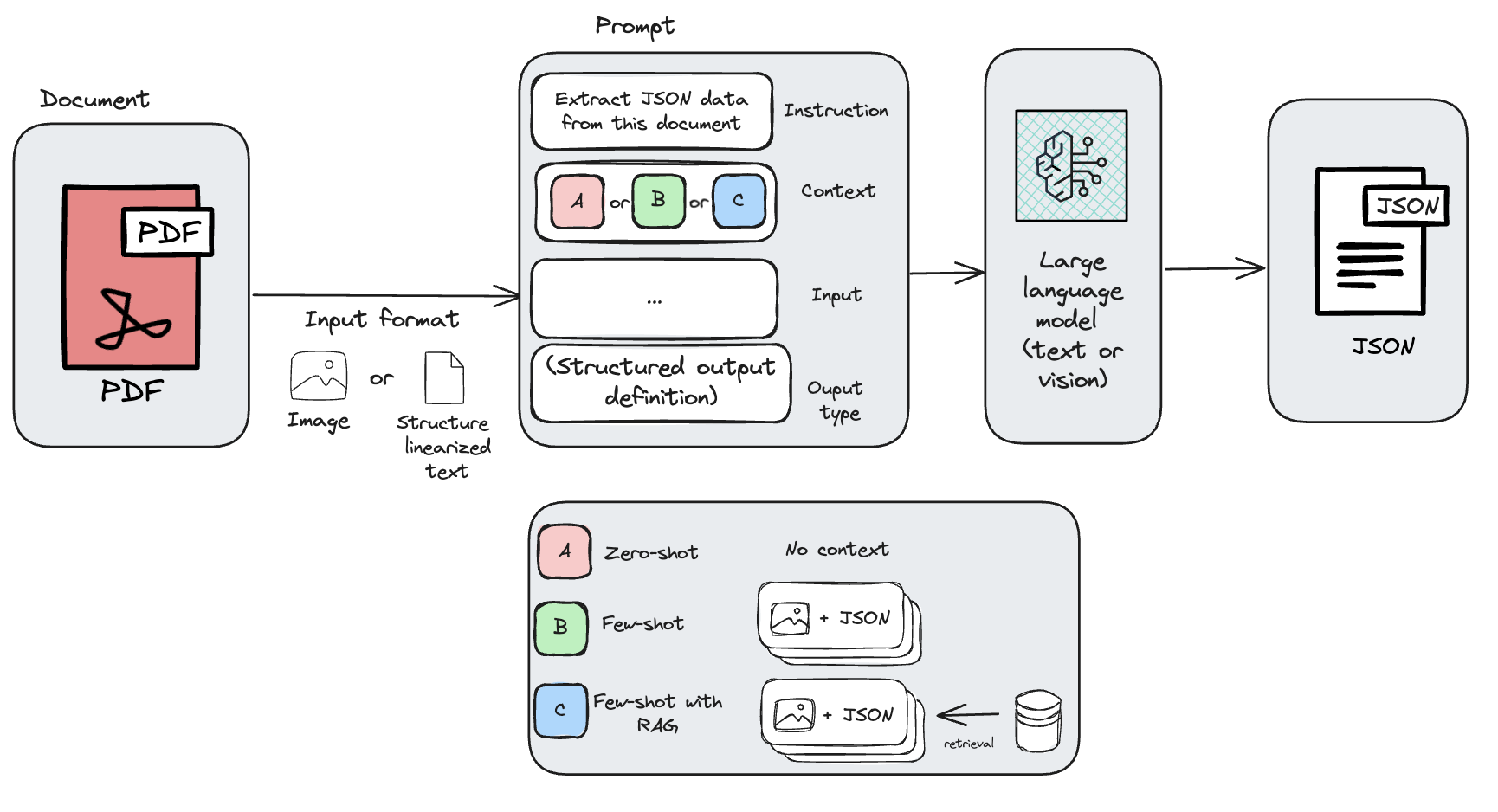
As proven within the previous determine, the immediate context will differ primarily based on the technique chosen (zero-shot, few-shot or few-shot with RAG), which can general change the outcomes obtained.
Wonderful-tuning VLMs
On the finish of the spectrum, you will have the choice to fine-tune a customized mannequin to carry out doc processing. That is our really useful strategy and what we deal with on this submit. Wonderful-tuning is a technique the place a pre-trained LLM is additional educated on a selected dataset to specialize it for a specific process or area. Within the context of doc processing, fine-tuning entails utilizing labeled examples—similar to annotated invoices, contracts, or insurance coverage types—to show the mannequin precisely methods to extract or interpret related data. Often, the labor-intensive a part of fine-tuning is buying an appropriate, high-quality dataset. Within the case of doc processing, your organization in all probability already has a historic dataset in its current doc processing system. You’ll be able to export this knowledge out of your doc processing system (for instance out of your enterprise useful resource planning (ERP) system) and use it because the dataset for fine-tuning. This fine-tuning strategy is what we deal with on this submit as a scalable, excessive accuracy, and cost-effective strategy for clever doc processing.
The previous approaches symbolize a spectrum of methods to enhance LLM efficiency alongside two axes: LLM optimization (shaping mannequin habits by means of immediate engineering or fine-tuning) and context optimization (enhancing what the mannequin is aware of at inference by means of methods similar to few-shot studying or RAG). These strategies might be mixed—for instance, utilizing RAG with few-shot prompts or incorporating retrieved knowledge into fine-tuning—to maximise accuracy.
Wonderful-tuning VLMs for document-to-JSON conversion
Our strategy—the really useful resolution for cost-effective document-to-JSON conversion—makes use of a VLM and fine-tunes it utilizing a dataset of historic paperwork paired with their corresponding ground-truth JSON that we take into account as annotations. This permits the mannequin to study the precise patterns, fields, and output construction related to your historic knowledge, successfully instructing it to learn your paperwork and extract data in response to your required schema.
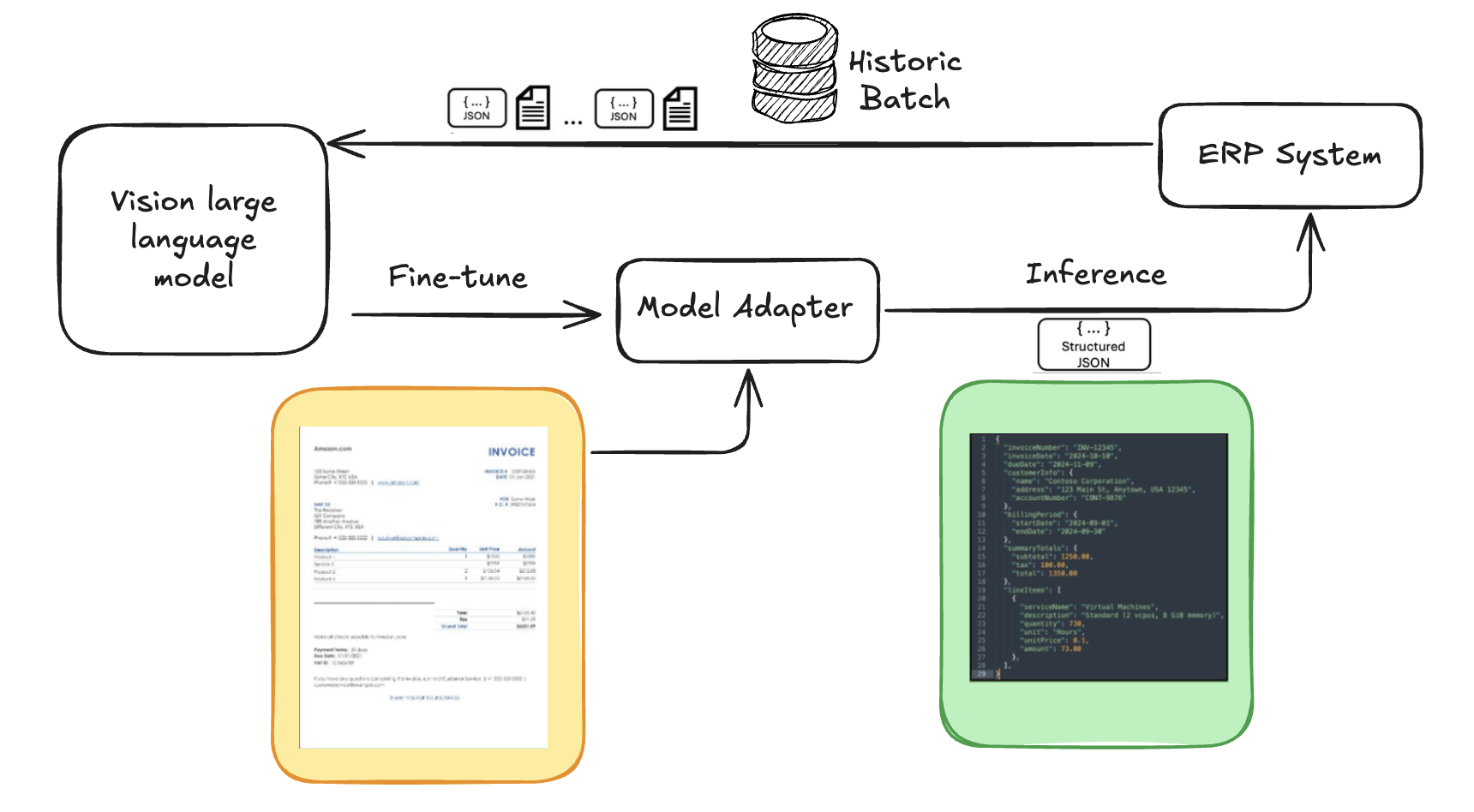
The next determine exhibits a high-level structure of the document-to-JSON conversion course of for fine-tuning VLMs through the use of historic knowledge. This permits the VLM to study from excessive knowledge variations and helps be certain that the structured output matches the goal system construction and format.
Wonderful-tuning affords a number of benefits over relying solely on OCR or common VLMs:
- Schema adherence: The mannequin learns to output JSON matching a selected goal construction, which is significant for integration with downstream techniques like ERPs.
- Implicit area location: Wonderful-tuned VLMs usually study to find and extract fields with out specific bounding field annotations within the coaching knowledge, simplifying knowledge preparation considerably.
- Improved textual content extraction high quality: The mannequin turns into extra correct at extracting textual content even from visually complicated or noisy doc layouts.
- Contextual understanding: The mannequin can higher perceive the relationships between completely different items of knowledge on the doc.
- Decreased immediate engineering: Put up fine-tuning, the mannequin requires much less complicated or shorter prompts as a result of the specified extraction habits is constructed into its weights.
For our fine-tuning course of, we chosen the Swift framework. Swift gives a complete, light-weight toolkit for fine-tuning varied giant language fashions, together with VLMs like Qwen-VL and Llama-Imaginative and prescient.
Information preparation
To fine-tune the VLMs, you’ll use the Fatura2 dataset, a multi-layout bill picture dataset comprising 10,000 invoices with 50 distinct layouts.
The Swift framework expects coaching knowledge in a selected JSONL (JSON Strains) format. Every line within the file is a JSON object representing a single coaching instance. For multimodal duties, this JSON object sometimes consists of:
messages: An inventory of conversational turns (for instance, system, person, assistant). The person flip comprises placeholders for photographs (for instance, <picture>) and the textual content immediate that guides the mannequin. The assistant flip comprises the goal output, which on this case is the ground-truth JSON string.photographs: An inventory of relative paths—inside the dataset listing construction—to the doc web page photographs (JPG information) related to this coaching instance.
As with normal ML observe, the dataset is cut up into coaching, improvement (validation), and check units to successfully prepare the mannequin, tune hyperparameters, and consider its closing efficiency on unseen knowledge. Every doc (which could possibly be single-page or multi-page) paired with its corresponding ground-truth JSON annotation constitutes a single row or instance in our dataset. In our use case, one coaching pattern is the bill picture (or a number of photographs of doc pages) and the corresponding detailed JSON extraction. This one-to-one mapping is important for supervised fine-tuning.
The conversion course of, detailed within the dataset creation notebook from the associated GitHub repo, entails a number of key steps:
- Picture dealing with: If the supply doc is a PDF, every web page is rendered right into a high-quality PNG picture.
- Annotation processing (fill lacking values): We apply gentle pre-processing to the uncooked JSON annotation. Wonderful-tuning a number of fashions on an open supply dataset, we noticed that the efficiency will increase when all keys are current in each JSON pattern. To keep up this consistency, the goal JSONs within the dataset are made to incorporate the identical set of top-level keys (derived from your entire dataset). If a secret’s lacking for a specific doc, it’s added with a null worth.
- Key ordering: The keys inside the processed JSON annotation are sorted alphabetically. This constant ordering helps the mannequin study a steady output construction.
- Immediate development: A person immediate is constructed. This immediate consists of <picture> tags (one for every web page of the doc) and explicitly lists the JSON keys the mannequin is predicted to extract. Together with the JSON keys within the prompts improves the fine-tuned mannequin’s efficiency.
- Swift formatting: These elements (immediate, picture paths, goal JSON) are assembled into the Swift JSONL format. Swift datasets assist multimodal inputs, together with photographs, movies and audios.
The next is an instance construction of a single coaching occasion in Swift’s JSONL format, demonstrating how multimodal inputs are organized. This consists of conversational messages, paths to pictures, and objects containing bounding field (bbox) coordinates for visible references inside the textual content. For extra details about methods to create a customized dataset for Swift, see the Swift documentation.
Wonderful-tuning frameworks and sources
In our analysis of fine-tuning frameworks to be used with SageMaker AI, we thought of a number of outstanding choices highlighted in the neighborhood and related to our wants. These included Hugging Face Transformers, Hugging Face Autotrain, Llama Manufacturing facility, Unsloth, Torchtune, and ModelScope SWIFT (referred to easily as SWIFT on this submit, aligning with the SWIFT 2024 paper by Zhao and others.).
After experimenting with these, we determined to make use of SWIFT due to its light-weight nature, complete assist for varied Parameter-Environment friendly Wonderful-Tuning (PEFT) strategies like LoRA and DoRA, and its design tailor-made for environment friendly coaching of a big selection of fashions, together with the VLMS used on this submit (for instance, Qwen-VL 2.5). Its scripting strategy integrates seamlessly with SageMaker AI coaching jobs, permitting for scalable and reproducible fine-tuning runs within the cloud.
There are a number of methods for adapting pre-trained fashions: full fine-tuning, the place all mannequin parameters are up to date, PEFT, which affords a extra environment friendly various by updating solely a small new variety of parameters (adapters), and quantization, a way that reduces mannequin dimension and hastens inference utilizing lower-precision codecs (see Sebastian Rashka’s post on fine-tuning to study extra about every approach).
Our venture makes use of LoRA and DoRA, as configured within the fine-tuning notebook.
The next is an instance of configuring and working a fine-tuning job (LoRA) as a SageMaker AI coaching job utilizing SWIFT and distant operate. When executing this operate, the fine-tuning might be executed remotely as a SageMaker AI coaching job.
Wonderful-tuning VLMs sometimes requires GPU situations due to their computational calls for. For fashions like Qwen2.5-VL 3B, an occasion similar to an Amazon SageMaker AI ml.g5.2xlarge or ml.g6.8xlarge might be appropriate. Coaching time is a operate of dataset dimension, mannequin dimension, batch dimension, variety of epochs, and different hyperparameters. As an illustration, as famous in our venture readme.md, fine-tuning Qwen2.5 VL 3B on 300 Fatura2 samples took roughly 2,829 seconds (roughly 47 minutes) on an ml.g6.8xlarge occasion utilizing Spot pricing. This demonstrates how smaller fashions, when fine-tuned successfully, can ship distinctive efficiency cost-efficiently. Bigger fashions like Llama-3.2-11B-Imaginative and prescient would usually require extra substantial GPU sources (for instance, ml.g5.12xlarge or bigger) and longer coaching instances.
Analysis and visualization of structured outputs (JSON)
A key side of any automation or machine studying venture is analysis. With out evaluating your resolution, you don’t know the way properly it performs at fixing your small business downside. We wrote an evaluation notebook that you should use as a framework. Evaluating the efficiency of document-to-JSON fashions entails evaluating the model-generated JSON outputs for unseen enter paperwork (check dataset) towards the ground-truth JSON annotations.
Key metrics employed in our venture embrace:
- Actual match (EM) – accuracy: This metric measures whether or not the extracted worth for a selected area is a precise character-by-character match to the ground-truth worth. It’s a strict metric, usually reported as a proportion.
- Character error price (CER) – edit distance: calculates the minimal variety of single-character edits (insertions, deletions, or substitutions) required to vary the mannequin’s predicted string into the ground-truth string, sometimes normalized by the size of the ground-truth string. A decrease CER signifies higher efficiency.
- Recall-Oriented Understudy for Gisting Analysis (ROGUE): It is a suite of metrics that evaluate n-grams (sequences of phrases) and the longest widespread subsequence between the expected output and the reference. Whereas historically used for textual content summarization, ROUGE scores also can present insights into the general textual similarity of the generated JSON string in comparison with the bottom reality.
Visualizations are useful for understanding mannequin efficiency nuances. The next edit distance heatmap picture gives a granular view, displaying how carefully the predictions match the bottom reality (inexperienced means the mannequin’s output precisely matches the bottom reality, and shades of yellow, orange, and pink depict rising deviations). Every mannequin has its personal bar chart, permitting fast comparability throughout fashions. The X-axis is the variety of pattern paperwork. On this case, we ran inference on 250 unseen samples from the Fatura2 dataset. The Y-axis exhibits the JSON keys that we requested the mannequin to extract; which might be completely different for you relying on what construction your downstream system requires.
Within the picture, you possibly can see the efficiency of three completely different fashions on the Fatura2 dataset. From left to proper: Qwen2.5 VL 3B fine-tuned on 300 samples from the Fatura2 dataset, within the center Qwen2.5 VL 3B with out fine-tuning (labeled vanilla), and Llama 3.2 11B imaginative and prescient fine-tuned on 1,000 samples.
The gray shade exhibits the samples for which the Fatura2 dataset doesn’t comprise any floor reality, which is why these are the identical throughout the three fashions.
For an in depth, step-by-step walk-through of how the analysis metrics are calculated, the precise Python code used, and the way the visualizations are generated, see the excellent evaluation notebook in our project.
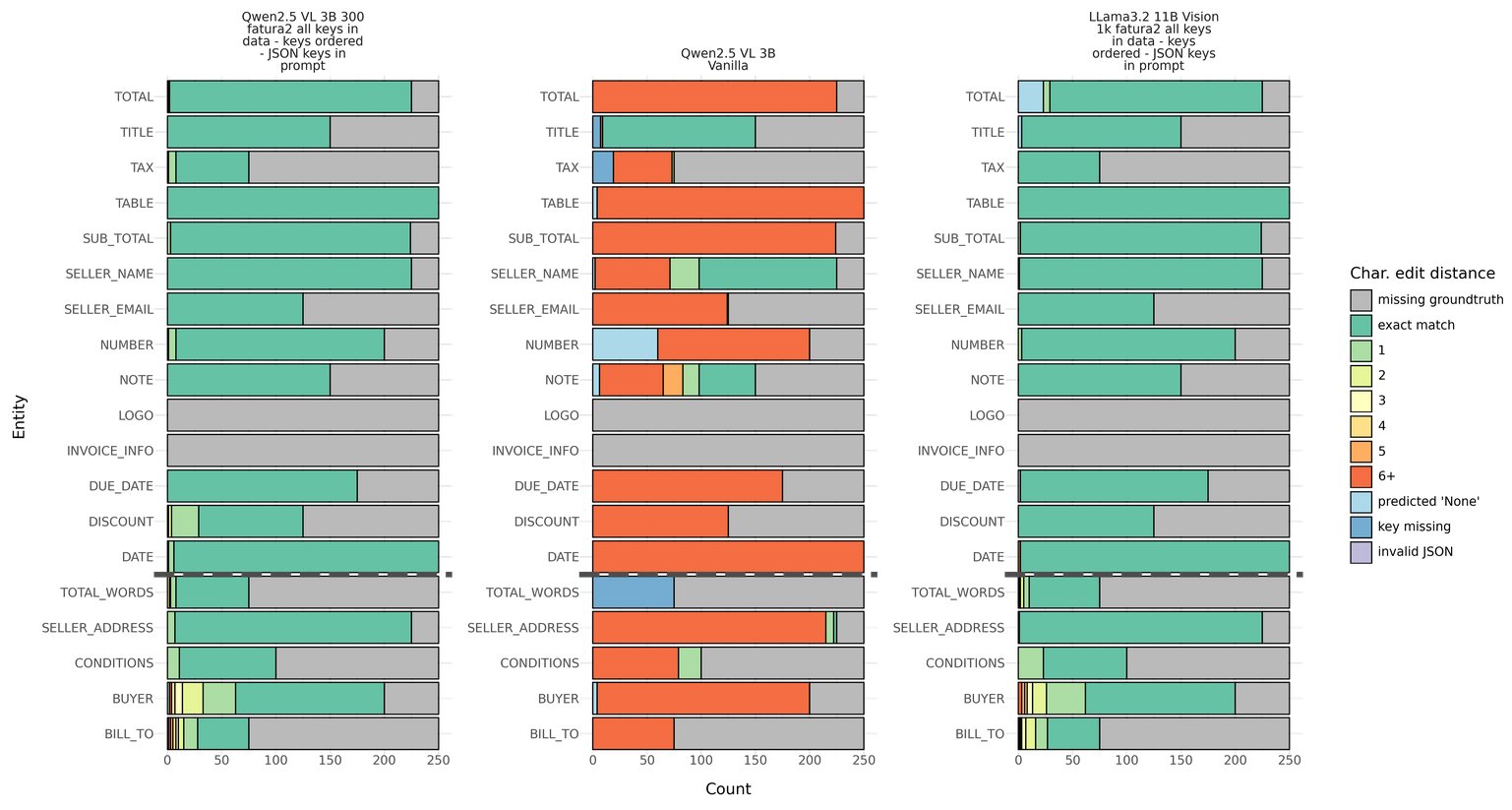
The picture exhibits that Qwen2.5 vanilla is simply respectable at extracting the Title and Vendor Title from the doc. For the opposite keys it makes greater than six character edit errors. Nevertheless, out of the field Qwen2.5 is sweet at adhering to the JSON schema with just a few predictions the place the secret is lacking (darkish blue shade) and no predictions of JSON that couldn’t be parsed (for instance, lacking citation marks, lacking parentheses, or a lacking comma). Analyzing the 2 fine-tuned fashions, you possibly can see enchancment in efficiency with most samples, precisely matching the bottom reality on all keys. There are solely slight variations between fine-tuned Qwen2.5 and fine-tuned Llama 3.2, for instance fine-tuned Qwen2.5 barely outperforms fine-tuned Llama 3.2 on Complete, Title, Circumstances, and Purchaser; whereas fine-tuned Llama 3.2 barely outperforms fine-tuned Qwen2.5 on Vendor Deal with, Low cost, Tax, and Low cost.
The purpose is to enter a doc into your fine-tuned mannequin and obtain a clear, structured JSON object that precisely maps the extracted data to predefined fields. JSON-constrained decoding enforces adherence to a specified JSON schema throughout inference and is helpful to verify the output is legitimate JSON. For the Fatura2 dataset, this strategy was not mandatory—our fine-tuned Qwen 2.5 mannequin persistently produced legitimate JSON outputs with out further constraints. Nevertheless, incorporating constrained decoding stays a beneficial safeguard, significantly for manufacturing environments the place output reliability is important.
Notebook 07 visualizes the enter doc and the extracted JSON knowledge side-by-side.
Deploying the fine-tuned mannequin
After you fine-tune a mannequin and consider it in your dataset, it would be best to deploy it to run inference to course of your paperwork. Relying in your use case, a distinct deployment choice could be extra appropriate.
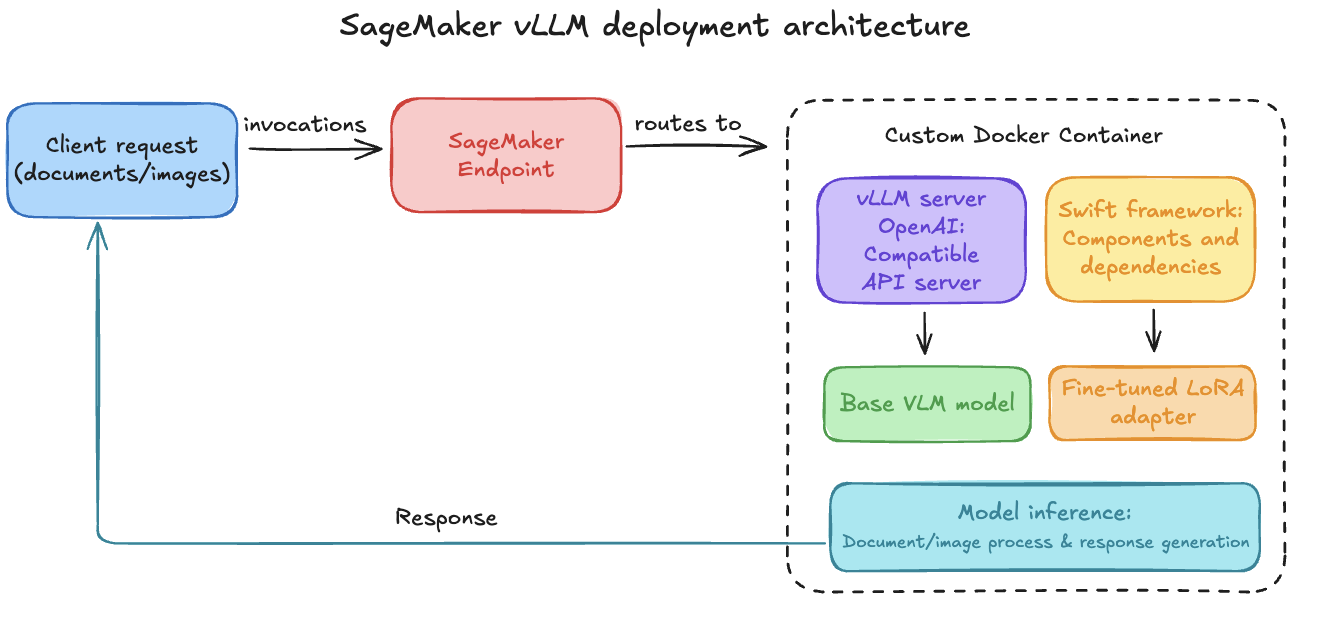
Choice a: vLLM container prolonged for SageMaker
To deploy our fine-tuned mannequin for real-time inference, we use SageMaker endpoints. SageMaker endpoints present absolutely managed internet hosting for real-time inference for FMs, deep studying, and different ML fashions and permits managed autoscaling and price optimum deployment methods. The method, detailed in our deploy model notebook, entails constructing a customized Docker container. This container packages the vLLM serving engine, extremely optimized for LLM and VLM inference, together with the Swift framework elements wanted to load our particular mannequin and adapter. vLLM gives an OpenAI-compatible API server by default, appropriate for dealing with doc and picture inputs with VLMs. Our customized docker-artifacts and Dockerfile adapts this vLLM base for SageMaker deployment. Key steps embrace:
- Organising the required surroundings and dependencies.
- Configuring an entry level that initializes the vLLM server.
- Ensuring the server can load the bottom VLM and dynamically apply our fine-tuned LoRA adapter. The Amazon S3 path to the adapter (
mannequin.tar.gz) is handed utilizing theADAPTER_URIsurroundings variable when creating the SageMaker mannequin. - The container, after being constructed and pushed to Amazon ECR, is then deployed to a SageMaker endpoint, which listens for invocation requests and routes them to the vLLM engine contained in the container.
The next picture exhibits a SageMaker vLLM deployment structure, the place a customized Docker container from Amazon ECR is deployed to a SageMaker endpoint. The container makes use of vLLM’s OpenAI-compatible API and Swift to serve a base VLM with a fine-tuned LoRA adapter dynamically loaded from Amazon S3.
Choice b (non-obligatory): Inference elements on SageMaker
For extra complicated inference workflows that may contain subtle pre-processing of enter paperwork, post-processing of the extracted JSON, and even chaining a number of fashions (for instance, a classification mannequin adopted by an extraction mannequin), Amazon SageMaker inference elements provide enhanced flexibility. You need to use them to construct a pipeline of a number of containers or fashions inside a single endpoint, every dealing with a selected a part of the inference logic.
Choice c: Customized mannequin inference in Amazon Bedrock
Now you can import your customized fashions in Amazon Bedrock after which use Amazon Bedrock options to make inference calls to the mannequin. Qwen 2.5 structure is supported (see Supported Architectures). For extra data, see Amazon Bedrock Customized Mannequin Import now usually accessible.
Clear up
To keep away from ongoing fees, it’s necessary to take away the AWS sources created for this venture while you’re completed.
- SageMaker endpoints and fashions:
- Within the AWS Administration Console for SageMaker AI, go to Inference after which Endpoints. Choose and delete endpoints created for this venture.
- Then, go to Inference after which Fashions and delete the related fashions.
- Amazon S3 knowledge:
- Navigate to the Amazon S3 console.
- Delete the S3 buckets or particular folders or prefixes used for datasets, mannequin artifacts (for instance, mannequin.tar.gz from coaching jobs), and inference outcomes. Observe: Be sure you don’t delete knowledge wanted by different initiatives.
- Amazon ECR photographs and repositories:
- Within the Amazon ECR console, delete Docker photographs and the repository created for the customized vLLM container if you happen to deployed one.
- CloudWatch logs (non-obligatory):
- Logs from SageMaker actions are saved in Amazon CloudWatch. You’ll be able to delete related log teams (for instance,
/aws/sagemaker/TrainingJobsand/aws/sagemaker/Endpoints) if desired, although many have automated retention insurance policies.
- Logs from SageMaker actions are saved in Amazon CloudWatch. You’ll be able to delete related log teams (for instance,
Vital: At all times confirm sources earlier than deletion. If you happen to experimented with Amazon Bedrock customized mannequin imports, make sure that these are additionally cleaned up. Use AWS Price Explorer to observe for sudden fees.
Conclusion and future outlook
On this submit, we demonstrated that fine-tuning VLMs gives a strong and versatile strategy to automate and considerably improve doc understanding capabilities. We now have additionally demonstrated that utilizing targeted fine-tuning permits smaller, multi-modal fashions to compete successfully with a lot bigger counterparts (98% accuracy with Qwen2.5 VL 3B). The venture additionally highlights that fine-tuning VLMs for document-to-JSON processing might be finished cost-effectively through the use of Spot situations and PEFT strategies (roughly $1 USD to fine-tune a 3 billion parameter mannequin on round 200 paperwork).
The fine-tuning process was carried out utilizing Amazon SageMaker coaching jobs and the Swift framework, which proved to be a flexible and efficient toolkit for orchestrating this fine-tuning course of.
The potential for enhancing and increasing this work is huge. Some thrilling future instructions embrace deploying structured doc fashions on CPU-based, serverless compute like AWS Lambda or Amazon SageMaker Serverless Inference utilizing instruments like llama.cpp or vLLM. Utilizing quantized fashions can allow low-latency, cost-efficient inference for sporadic workloads. One other future course consists of enhancing analysis of structured outputs by going past field-level metrics. This consists of validating complicated nested buildings and tables utilizing strategies like tree edit distance for tables (TEDS).
The entire code repository, together with the notebooks, utility scripts, and Docker artifacts, is available on GitHub that can assist you get began unlocking insights out of your paperwork. For the same strategy, utilizing Amazon Nova, please seek advice from this AWS weblog for optimizing doc AI and structured outputs by fine-tuning Amazon Nova Fashions and on-demand inference.
Concerning the Authors
 Arlind Nocaj is a GTM Specialist Options Architect for AI/ML and Generative AI for Europe central primarily based in AWS Zurich Workplace, who guides enterprise clients by means of their digital transformation journeys. With a PhD in community analytics and visualization (Graph Drawing) and over a decade of expertise as a analysis scientist and software program engineer, he brings a singular mix of educational rigor and sensible experience to his position. His main focus lies in utilizing the complete potential of knowledge, algorithms, and cloud applied sciences to drive innovation and effectivity. His areas of experience embrace Machine Studying, Generative AI and specifically Agentic techniques with Multi-modal LLMs for doc processing and structured insights.
Arlind Nocaj is a GTM Specialist Options Architect for AI/ML and Generative AI for Europe central primarily based in AWS Zurich Workplace, who guides enterprise clients by means of their digital transformation journeys. With a PhD in community analytics and visualization (Graph Drawing) and over a decade of expertise as a analysis scientist and software program engineer, he brings a singular mix of educational rigor and sensible experience to his position. His main focus lies in utilizing the complete potential of knowledge, algorithms, and cloud applied sciences to drive innovation and effectivity. His areas of experience embrace Machine Studying, Generative AI and specifically Agentic techniques with Multi-modal LLMs for doc processing and structured insights.
 Malte Reimann is a Options Architect primarily based in Zurich, working with clients throughout Switzerland and Austria on their cloud initiatives. His focus lies in sensible machine studying functions—from immediate optimization to fine-tuning imaginative and prescient language fashions for doc processing. The latest instance, working in a small crew to supply deployment choices for Apertus on AWS. An energetic member of the ML neighborhood, Malte balances his technical work with a disciplined strategy to health, preferring early morning fitness center periods when it’s empty. Throughout summer time weekends, he explores the Swiss Alps on foot and having fun with time in nature. His strategy to each know-how and life is easy: constant enchancment by means of deliberate observe, whether or not that’s optimizing a buyer’s cloud deployment or getting ready for the following hike within the clouds.
Malte Reimann is a Options Architect primarily based in Zurich, working with clients throughout Switzerland and Austria on their cloud initiatives. His focus lies in sensible machine studying functions—from immediate optimization to fine-tuning imaginative and prescient language fashions for doc processing. The latest instance, working in a small crew to supply deployment choices for Apertus on AWS. An energetic member of the ML neighborhood, Malte balances his technical work with a disciplined strategy to health, preferring early morning fitness center periods when it’s empty. Throughout summer time weekends, he explores the Swiss Alps on foot and having fun with time in nature. His strategy to each know-how and life is easy: constant enchancment by means of deliberate observe, whether or not that’s optimizing a buyer’s cloud deployment or getting ready for the following hike within the clouds.
 Nick McCarthy is a Senior Generative AI Specialist Options Architect on the Amazon Bedrock crew, targeted on mannequin customization. He has labored with AWS purchasers throughout a variety of industries — together with healthcare, finance, sports activities, telecommunications, and power — serving to them speed up enterprise outcomes by means of the usage of AI and machine studying. Outdoors of labor, Nick loves touring, exploring new cuisines, and studying about science and know-how. He holds a Bachelor’s diploma in Physics and a Grasp’s diploma in Machine Studying.
Nick McCarthy is a Senior Generative AI Specialist Options Architect on the Amazon Bedrock crew, targeted on mannequin customization. He has labored with AWS purchasers throughout a variety of industries — together with healthcare, finance, sports activities, telecommunications, and power — serving to them speed up enterprise outcomes by means of the usage of AI and machine studying. Outdoors of labor, Nick loves touring, exploring new cuisines, and studying about science and know-how. He holds a Bachelor’s diploma in Physics and a Grasp’s diploma in Machine Studying.
 Irene Marban Alvarez is a Generative AI Specialist Options Architect at Amazon Net Companies (AWS), working with clients in the UK and Eire. With a background in Biomedical Engineering and Masters in Synthetic Intelligence, her work focuses on serving to organizations leverage the newest AI applied sciences to speed up their enterprise. In her spare time, she loves studying and cooking for her pals.
Irene Marban Alvarez is a Generative AI Specialist Options Architect at Amazon Net Companies (AWS), working with clients in the UK and Eire. With a background in Biomedical Engineering and Masters in Synthetic Intelligence, her work focuses on serving to organizations leverage the newest AI applied sciences to speed up their enterprise. In her spare time, she loves studying and cooking for her pals.

{kind=link}