


How can audio modifying be as direct and controllable as merely rewriting a line of textual content? StepFun AI has open sourced Step-Audio-EditX, a 3B-parameter LLM-based audio mannequin that turns expressive audio modifying right into a token-level text-like operation moderately than a waveform-level sign processing activity.
Why builders worth controllable TTS?
Most zero-shot TTS programs copy emotion, model, accent, and timbre immediately from quick reference audio. Sounds pure, however has much less management. In-text model prompts are solely helpful for voices throughout the area, and duplicated voices usually ignore the requested emotion or talking model.
Previous work has tried to disentangle the elements utilizing extra encoders, adversarial losses, or complicated architectures. Step-Audio-EditX maintains a comparatively intertwined illustration and as an alternative adjustments the info and post-training targets. The mannequin learns management by seeing many pairs and triplets the place the textual content is fastened however one attribute adjustments by a big margin.
Structure, Twin Codebook Tokenizer and Compact Audio LLM
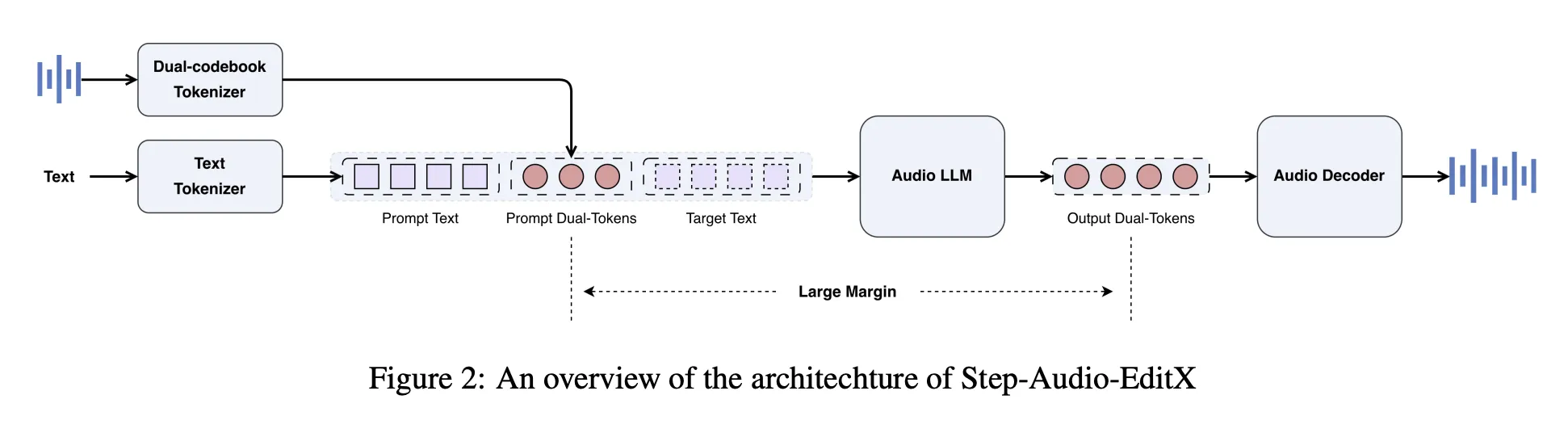
Step-Audio-EditX reuses the Step-Audio twin codebook tokenizer. Audio is mapped to 2 token streams. One is a 16.7 Hz linguistic stream with a 1024 entry codebook, and the opposite is a 25 Hz semantic stream with a 4096 entry codebook. Tokens are interleaved in a 2:3 ratio. The tokenizer retains prosodic and emotional data, so it’s not absolutely disentangled.
On high of this tokenizer, the StepFun analysis workforce will construct a 3B parameter audio LLM. The mannequin is initialized from a textual content LLM and educated on a blended corpus utilizing a 1:1 ratio of pure textual content and twin codebook audio tokens with chat-style prompts. Audio LLM reads textual content tokens, audio tokens, or each and all the time produces twin codebook audio tokens as output.
A separate audio decoder handles the reconstruction. A diffusion transformer-based move matching module predicts the Mel spectrogram from audio tokens, reference audio, and speaker embeddings, and a BigVGANv2 vocoder converts the Mel spectrogram right into a waveform. The Circulation Matching module is educated with roughly 200,000 hours of high-quality audio to enhance pronunciation and timbre similarity.
Artificial knowledge with massive margins as an alternative of complicated encoders
The important thing thought is massive margin studying. The mannequin is post-trained on triplets and quadruplets that maintain the textual content fastened and solely change one attribute with a transparent hole.
For zero-shot TTS, Step-Audio-EditX makes use of a high-quality in-house dataset that features primarily Chinese language and English, small quantities of Cantonese and Sichuan, and roughly 60,000 audio system. The information cowl a variety of within- and between-speaker variations in model and emotion. ()arXiv)
For emotion and speech modifying, the workforce builds artificial wide-margin triplets: textual content, voice impartial, and voice emotion or model. Voice actors file roughly 10-second clips for every emotion and magnificence. StepTTS’s zero-shot cloning generates impartial and emotional variations of the identical textual content and speaker. A margin scoring mannequin educated on a small set of human labels scores pairs on a scale of 1 to 10, and solely samples with a rating of not less than 6 are retained.
Paralinguistic modifying, protecting respiratory, laughter, pose embeddings, and different tags, makes use of a semi-synthesis technique based mostly on the NVSpeech dataset. The analysis workforce builds a quadruplet the place the goal is the unique NVSpeech audio and transcript, and the enter is a cloned model of the textual content with tags eliminated. This lets you monitor edits within the time area with out utilizing a margin mannequin.
Reinforcement studying knowledge makes use of two most popular sources. Human annotators give 20 candidates a 5-point score for accuracy, prosody, and naturalness for every immediate, and pairs with a margin larger than 3 are retained. The comprehension mannequin scores emotion and speech on a scale of 1 to 10 and retains pairs with a margin larger than 8.
After coaching, SFT and PPO of the token sequence
There are two levels of post-training: Supervised fine-tuning adopted by PPO.
in Supervised fine-tuningsystem prompts outline modifying duties in a zero-shot TTS and unified chat format. For TTS, the immediate waveform is encoded into twin codebook tokens, transformed to string format, and inserted into the system immediate as speaker data. The person message is the goal textual content and the mannequin returns a brand new audio token. For modifying, the person message accommodates the unique speech token and pure language directions, and the mannequin outputs the edited token.
Reinforcement studying improves instruction in:. The 3B reward mannequin is initialized from SFT checkpoints and educated with Bradley Terry loss on most popular pairs with massive margins. The reward is calculated immediately based mostly on the twin codebook token sequence with out decoding right into a waveform. PPO coaching makes use of this reward mannequin, clip threshold, and KL penalty to steadiness high quality and deviation from the SFT coverage.
Step-Audio-Edit-Check, Iterative Modifying and Generalization
To quantify management, the analysis workforce launched Step-Audio-Edit-Check. Use Gemini 2.5 Professional as an LLM to evaluate emotion, speech, and paralinguistic accuracy. This benchmark consists of 8 audio system extracted from Wenet Speech4TTS, GLOBE V2, and Libri Gentle, with 4 audio system per language.
The emotion set has 5 classes, and every class consists of 50 Chinese language and 50 English prompts. There are 7 types within the Talking Types set, and 50 prompts for every model for every language. This paralinguistic set has 10 labels resembling Breathe, Laughter, Shock, and Hmm, and 50 prompts for every label and language.
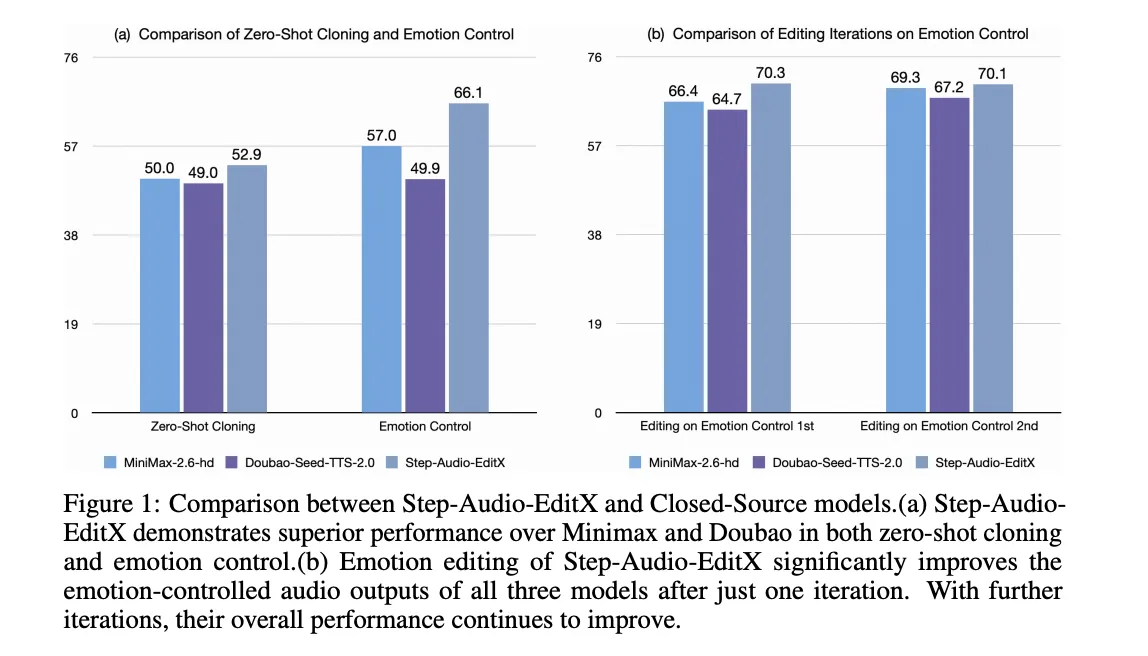
Edits are evaluated iteratively. Iteration 0 is the primary zero-shot clone. The mannequin then applies three rounds of edits utilizing textual content directions. In Chinese language, emotion accuracy elevated from 57.0 in iteration 0 to 77.7 in iteration 3. Speech accuracy elevated from 41.6 to 69.2. English confirmed comparable habits, with improved accuracy even in prompt-fixed ablation the place the identical immediate voice was utilized in all repetitions, supporting the margin studying speculation.

The identical modifying mannequin is utilized to 4 closed supply TTS programs: GPT 4o mini TTS, ElevenLab v2, Doubao Seed TTS 2.0, and MiniMax speech 2.6 hd. In all of those, a single modifying iteration with Step-Audio-EditX improves each emotional and stylistic precision, and the impact persists with additional iterations.
Paralinguistic modifying is scored on a scale of 1 to three. The common rating elevated from 1.91 at iteration 0 to 2.89 after 1 edit for each Chinese language and English. That is corresponding to native paralinguistic synthesis in highly effective industrial programs.

Essential factors
- Step Audio EditX makes use of a twin codebook tokenizer and a 3B parameter audio LLM, so you’ll be able to deal with audio as particular person tokens and edit audio in a text-like method.
- Quite than including additional disentangling encoders, this mannequin depends on high-margin artificial knowledge resembling emotion, speech model, paralinguistic cues, pace, and noise.
- PPO with supervised fine-tuning and a token-level reward mannequin tunes the audio LLM to observe pure language modifying directions for each TTS and modifying duties.
- The Step Audio Edit Check benchmark, with Gemini 2.5 Professional as decide, exhibits clear accuracy enhancements throughout three modifying iterations for emotion, model, and paralinguistic management in each Chinese language and English.
- Step Audio EditX can post-process and enhance audio from closed-source TTS programs, and the complete stack, together with code and checkpoints, is offered as open supply for builders.
Step Audio EditX maintains the Step Audio tokenizer, provides a compact 3B audio LLM, and optimizes management via massive margin knowledge and PPO, making it a exact step ahead in controllable speech synthesis. The introduction of the Step Audio Edit Check, which makes use of Gemini 2.5 Professional as a decide, will give concrete type to the analysis story relating to emotion, talking model, and paralinguistic management, and its open launch will decrease the hurdles for sensible audio modifying analysis. Total, this launch brings audio modifying even nearer to textual content modifying.
Please test paper, lipo and model weights. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to observe us too Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per thirty days, which exhibits its reputation amongst viewers.

{kind=link}