


How would your agent stack change if a coverage might be educated with no reward or demo, only a distinctive rollout based mostly on outcomes, and nonetheless outperformed imitation studying throughout eight benchmarks? The Meta-Superintelligence Analysis Institute isearly experienceIt’s a reward-free coaching method that improves language brokers’ coverage studying with out utilizing giant human demonstration units or reinforcement studying (RL) in the primary loop. The core concept is straightforward. The agent branches out from the skilled state and performs its personal actions, ensuing future stateand convert these outcomes into monitoring. The analysis group embodies this with two particular methods.Implicit World Modeling (IWM) and Self-reflection (SR)—Reviews constant advantages throughout eight environments and a number of base fashions.
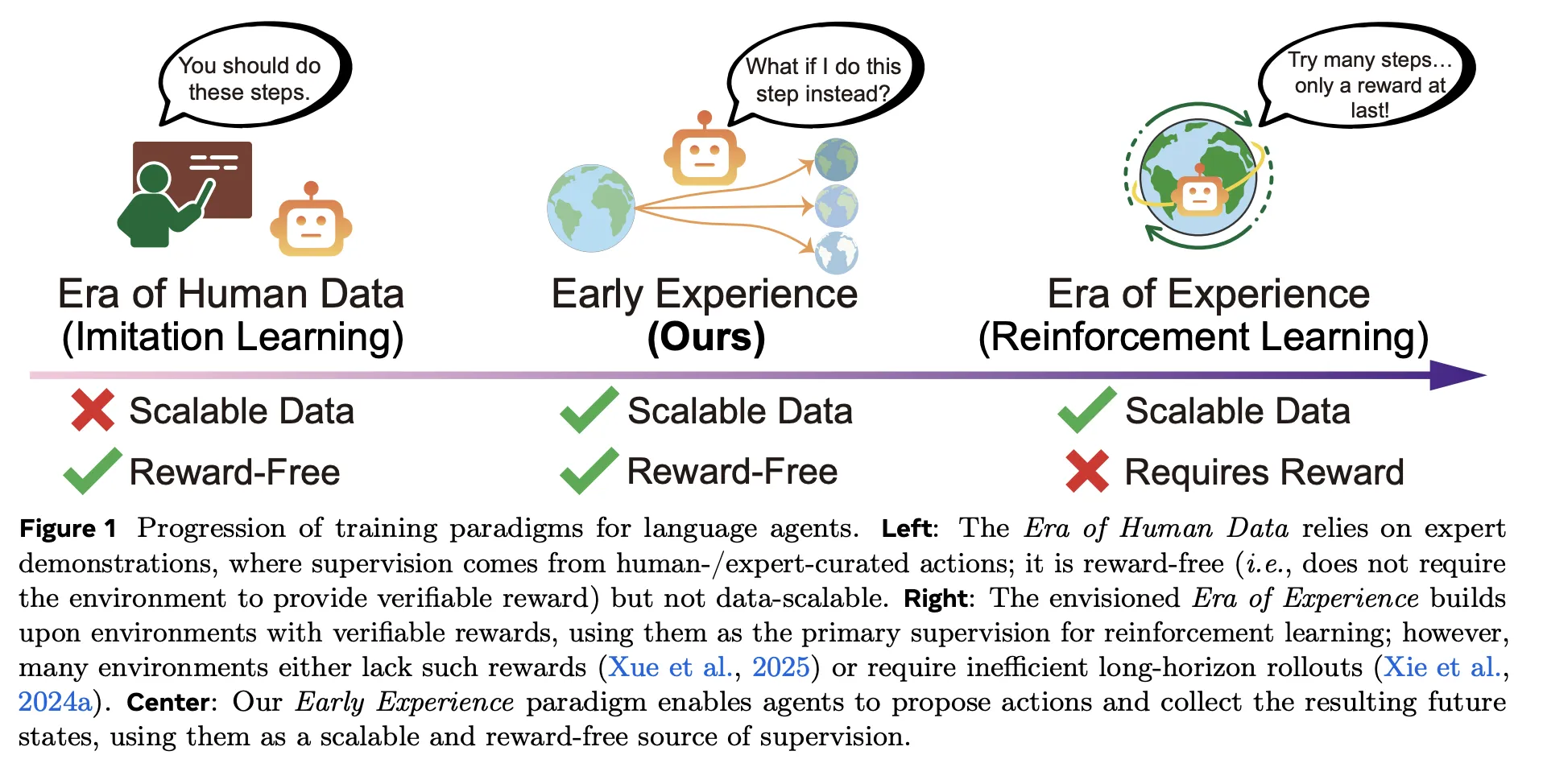
How will the early expertise change?
Conventional pipelines depend on Imitation studying (IL) Within the skilled trajectory, optimizations are low-cost, however troublesome to scale and susceptible exterior of distribution. Reinforcement studying (RL) Studying from expertise is promised, however requires verifiable rewards and steady infrastructure, which are sometimes missing in internet and multi-tool settings. early expertise sitting between them: it’s No reward like Imitation studying (IL)however the director is predicated on: the results of the agent’s personal actionsnot simply the actions of specialists. That’s, the agent suggests what’s going to really occur subsequent, acts on it, and learns from it. No reward perform is required.
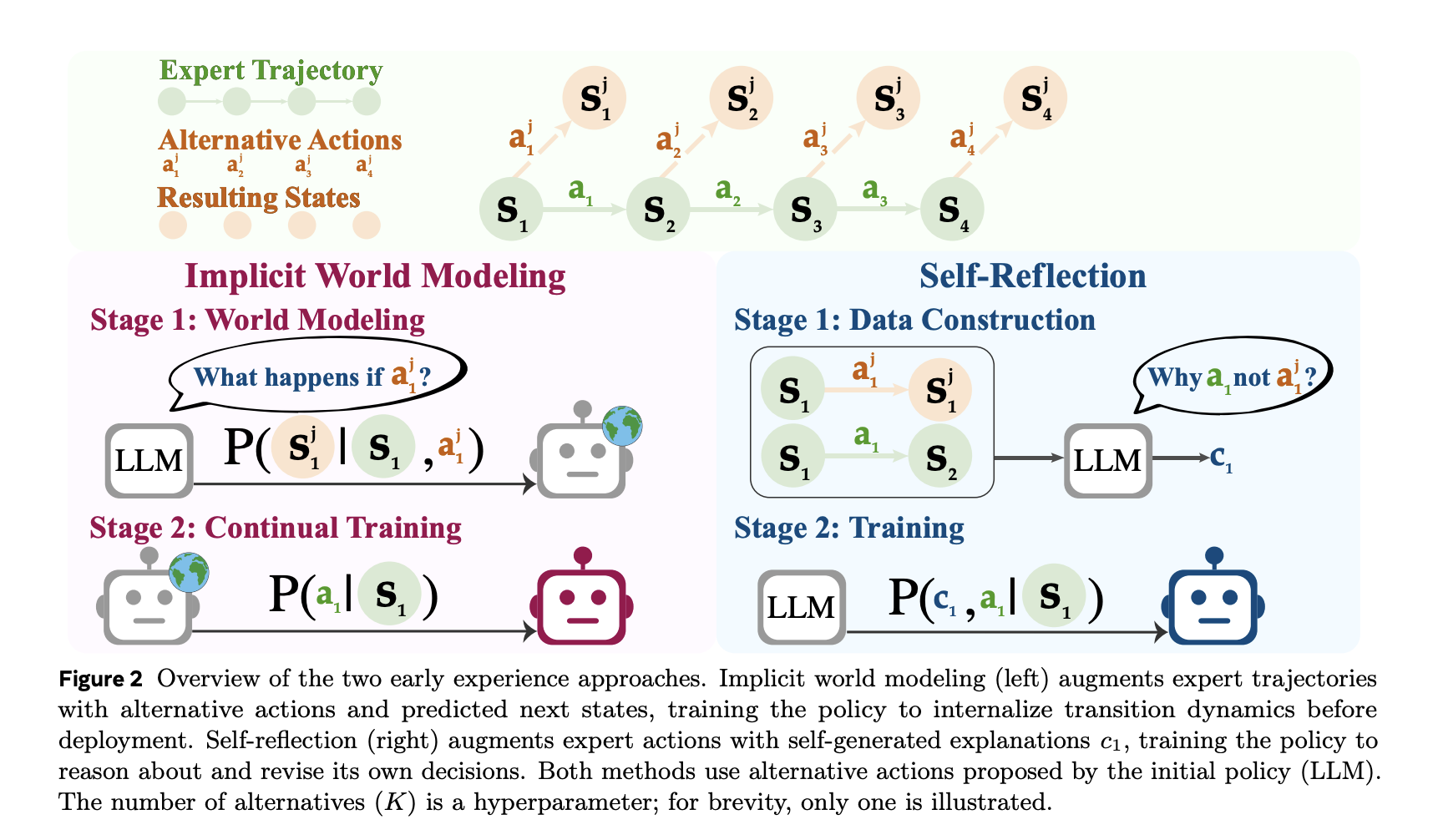
- Implicit World Modeling (IWM): Prepare the mannequin and make predictions Subsequent remark It enhances the agent’s inside mannequin of its environmental dynamics by taking into consideration its state and chosen actions, decreasing out-of-policy drift.
- Self-reflection (SR): Current specialists and different actions in the identical situation. Ask the mannequin to elucidate Why skilled actions are higher Use the noticed outcomes to fine-tune your coverage from this contrasting sign.
Each methods use the identical funds and decoding settings as IL. Solely the information supply differs (agent-generated branches somewhat than skilled trajectories).
Perceive benchmarks
The analysis group evaluates as follows. eight Language agent environments throughout internet navigation, long-term planning, scientific/concrete duties, and multi-domain API workflows. internet store (transactional looking), journey planner (plan with many constraints), science world, alfworld, tau bench,others. early expertise yield Common absolute revenue +9.6 success and +9.4 Out of Area (OOD) Runs on IL throughout the whole matrix of duties and fashions. These advantages persist if the identical checkpoints are used. Initialize RL (GRPO), improved higher restrict after RL Max +6.4 in comparison with Reinforcement studying (RL) It began from Imitation studying (IL).
Effectivity: Much less skilled knowledge, similar optimization funds
The important thing to actual victory is Demo effectivity. If the optimization funds is fastened, early expertise Match or beat IL utilizing fraction of skilled knowledge. above internet store, 1/8 demo with early expertise has already exceeded IL is full Demo set; prime alfworldparity hits 1/2 demo. This benefit grows with extra demonstrations, indicating that the long run states generated by the agent present monitoring alerts that demonstrations alone can’t seize.
The way to construct knowledge?
The pipeline is seeded from a restricted set of skilled rollouts to acquire a consultant state. As soon as chosen, the agent will counsel: different motionrun them and file them. Subsequent remark.
- for I.W.M.the coaching knowledge has three parts ⟨state, motion, subsequent state⟩, and the target is Prediction of subsequent state.
- for S.R.the immediate contains the skilled’s actions and a number of other alternate options, in addition to their noticed outcomes. The mannequin produces well-founded rationale It explains why skilled conduct is fascinating and this oversight is used to enhance coverage.
The place is reinforcement studying (RL) appropriate??
early expertise enamel should not have “RL with out compensation” is that supervised recipes utilizing Outcomes skilled by brokers as a label. In an setting with verifiable rewards, analysis groups merely Add RL after Early expertise. Initialization is healthier than IL, so Identical RL schedule Climb larger and quicker. as much as +6.4 Last success over IL-initialized RL throughout examined domains. This permits for early expertise bridge: Pre-training with out reward from outcomes. It’s finished in keeping with requirements (the place attainable). Reinforcement studying (RL).
Necessary factors
- Agent-generated coaching with out reward future state (not a reward) utilizing implicit world modeling and introspection Outperforms imitation studying throughout eight environments.
- Absolute advantages over IL have been reported: +18.4 (internet store), +15.0 (Journey Planner), +13.3 (Science World) Below matched budgets and settings.
- Demo effectivity: Transcend IL with WebShop 1/8 Concerning the demo. Attain parity with ALFWorld 1/2— with a hard and fast optimization price.
- As an initializer, early expertise Enhance the next RL (GRPO) endpoint as follows as much as +6.4 In opposition to RL, begin from IL.
- Validated on a number of spine households (3B-8B) with constant enhancements inside and outdoors the area. positioned as a bridge between Imitation studying (IL) and Reinforcement studying (RL).
early expertise It is a sensible contribution. We substitute weak rationale-only extensions with outcome-based monitoring that brokers can generate at scale with out reward features. Two variants, Implicit World Modeling (next-observation predictions to repair environmental dynamics) and Self-Reflection (contrasting result-validated rationales for skilled actions), instantly assault off-policy drift and long-term error accumulation, and clarify constant advantages for imitative studying throughout eight environments and a stronger RL higher sure when used as an initializer for GRPO. In internet and tooling settings the place verifiable rewards are missing, this reward-free monitoring is the lacking center floor between IL and RL, and is quickly executable within the manufacturing agent stack.
Please examine paper is here. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to comply with us too Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views monthly, demonstrating its reputation amongst viewers.

{kind=link}