


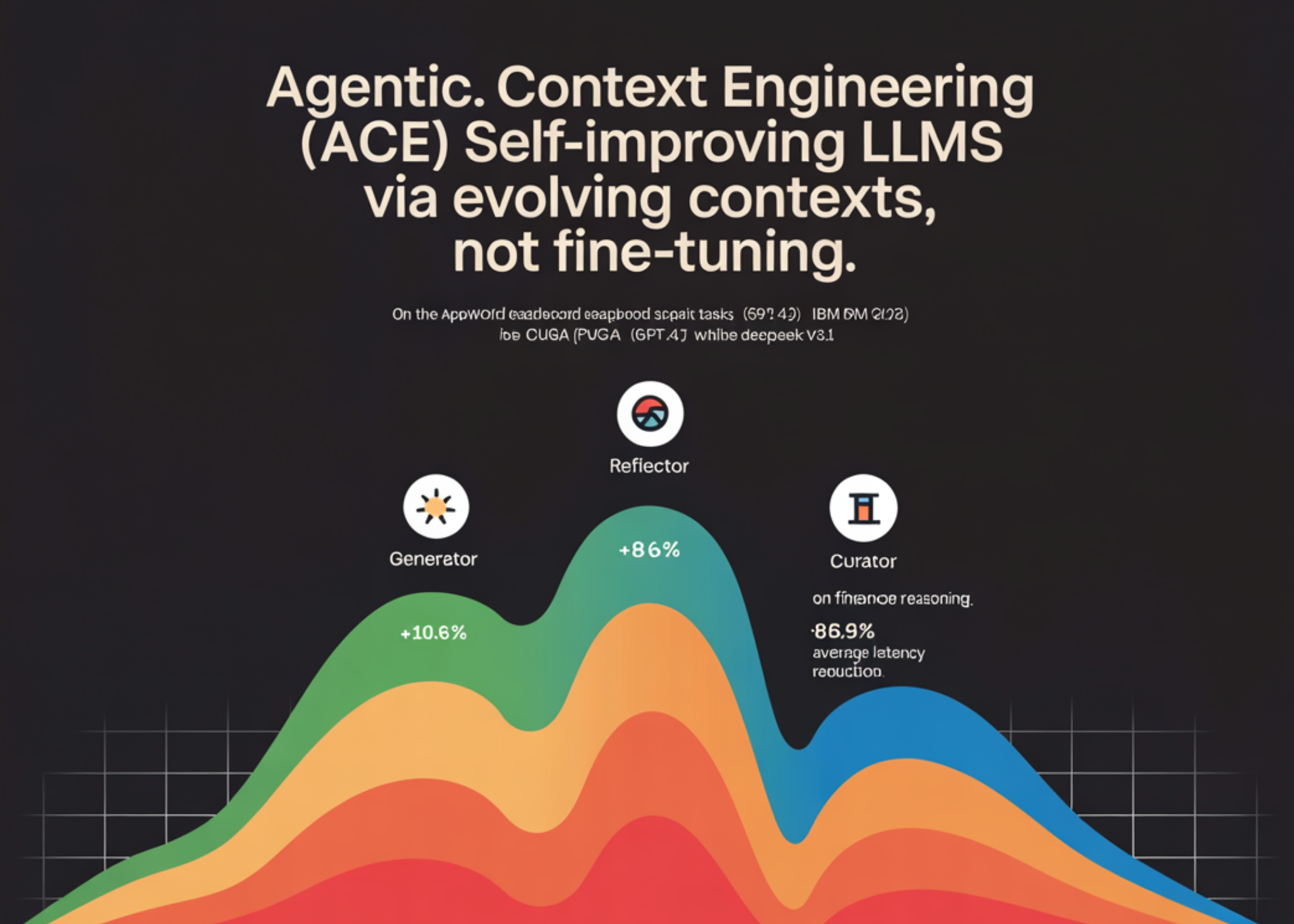
TL;DR: Launched by a group of researchers from Stanford College, SambaNova Techniques, and the College of California, Berkeley ACE framework This improves LLM efficiency. Enhancing and increasing enter contexts As a substitute of updating the mannequin weights. Context is handled as a dwelling “playbook” maintained by three roles.generator, reflector, curator— with small issues delta gadgets They’re merged in phases to keep away from brevity bias and context collapse. Reported revenue: +10.6% About AppWorld agent duties: +8.6% monetary reasoning; As much as 86.9% discount in common latency vs robust context-adaptive baseline. AppWorld Leaderboard Snapshot (September 20, 2025), ReAct+ACE (59.4%) ≈ IBM CUGA (60.3%, GPT-4.1) in use DeepSeek-V3.1.
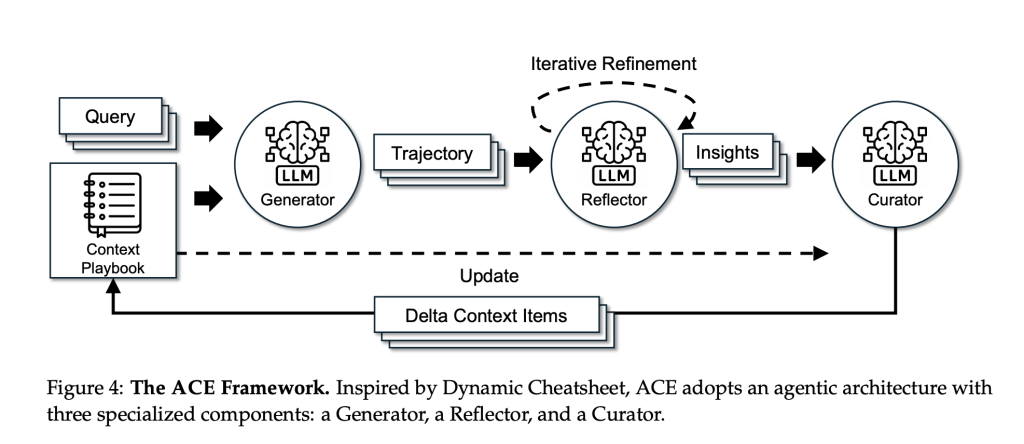
What does ACE change?
ACE positions “context engineering” because the premier various to parameter updates. Moderately than compressing directions into brief prompts, ACE Accumulate and set up domain-specific ways As time goes on, declare that it’s larger context density Instruments, multi-turn states, and failure modes enhance important agent duties.
Technique: Generator → Reflector → Curator
- generator It executes duties, generates trajectories (inferences/device calls), and divulges helpful and dangerous strikes.
- reflector Extract concrete classes from these traces.
- curator Converts the lesson to the enter delta gadgets Merge them deterministically (with useful/detrimental counters) and do deduplication and pruning to maintain playbooks coated.
Two design selections—Incremental delta replace and progress and refinement– Preserves helpful historical past and prevents “context collapse” because of monolithic rewrites. To isolate context results, the analysis group made the next modifications. Similar base LLM (non-thinking DeepSeek-V3.1) throughout all three roles.
benchmark
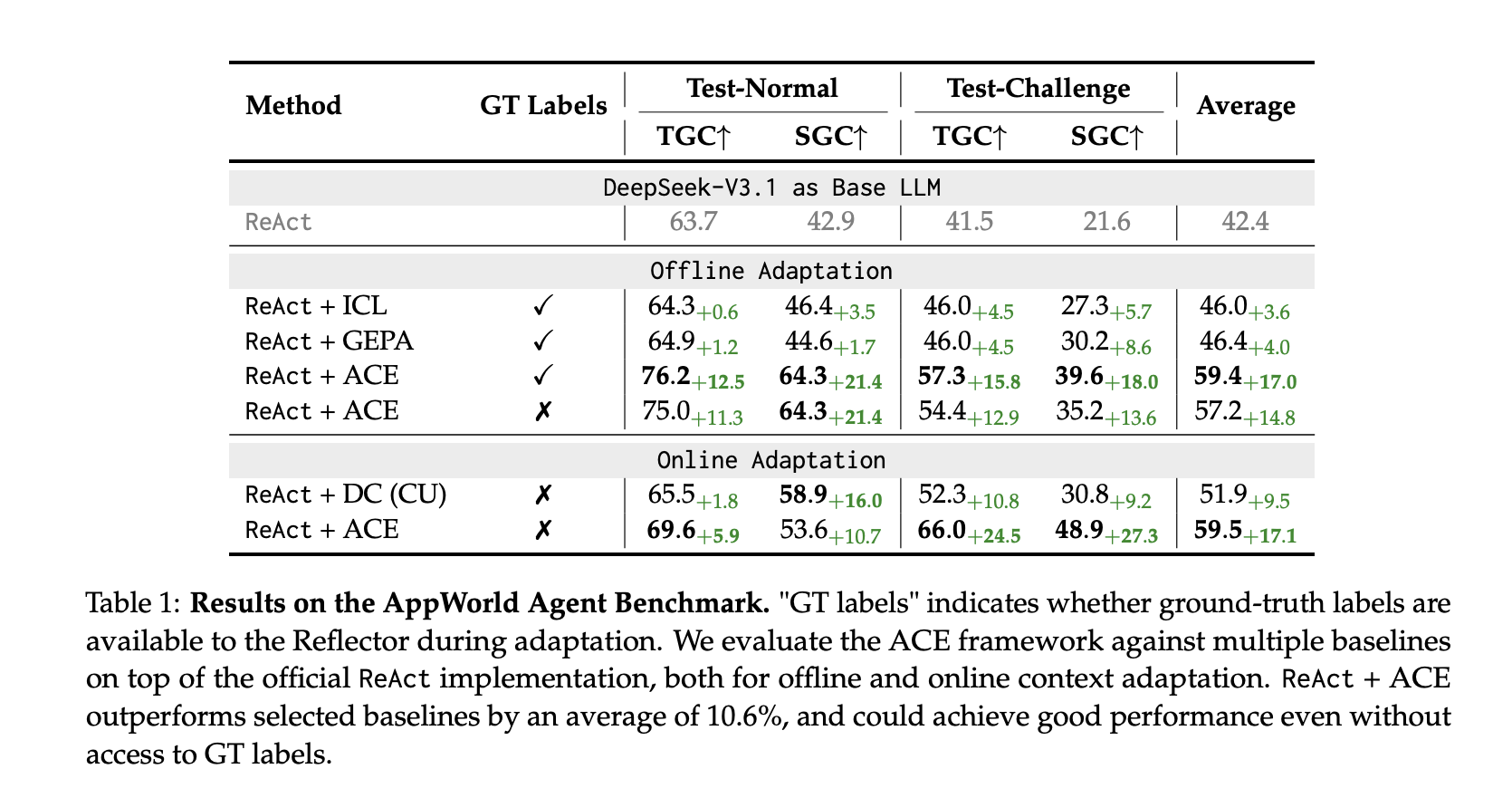
AppWorld (Agent): Constructed on the official ReAct baseline, React+ACE Outperform robust baselines (ICL, GEPA, Dynamic Cheat Sheet) +10.6% common Past the chosen baseline, ~+7.6% Use our online-enabled dynamic cheatsheet. in Leaderboard for September 20, 2025, ReAct+ACE 59.4% vs. IBM CUGA 60.3% (GPT-4.1);Ace Greater than CUGA harder take a look at problem Cut up whereas utilizing a smaller open supply base mannequin.
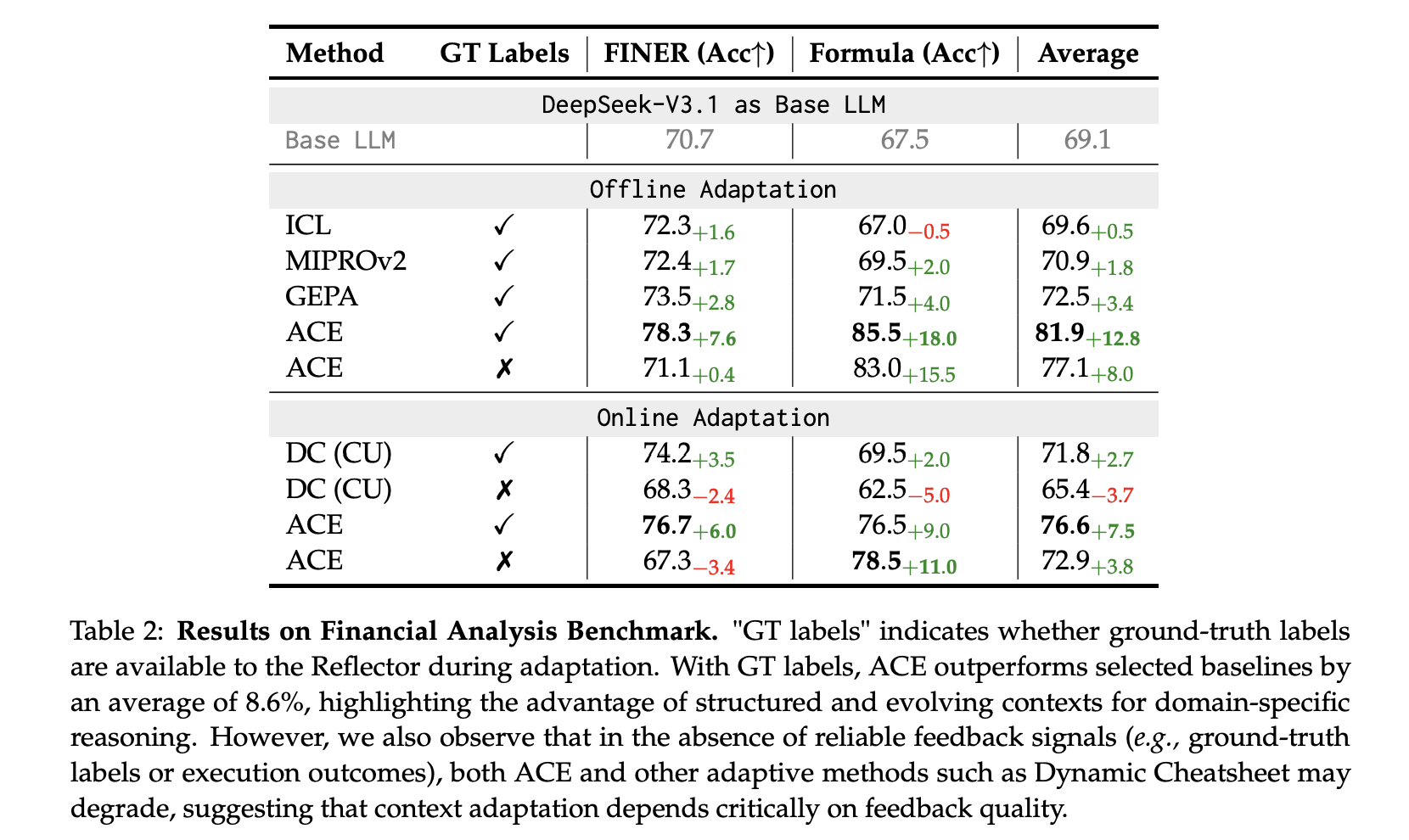
Finance (XBRL): above positive Tagging tokens and XBRL expression Numerical reasoning, ACE report +8.6% common On the baseline utilizing floor reality labels for offline adaptation. Sign high quality is vital, however execution-only suggestions additionally works.
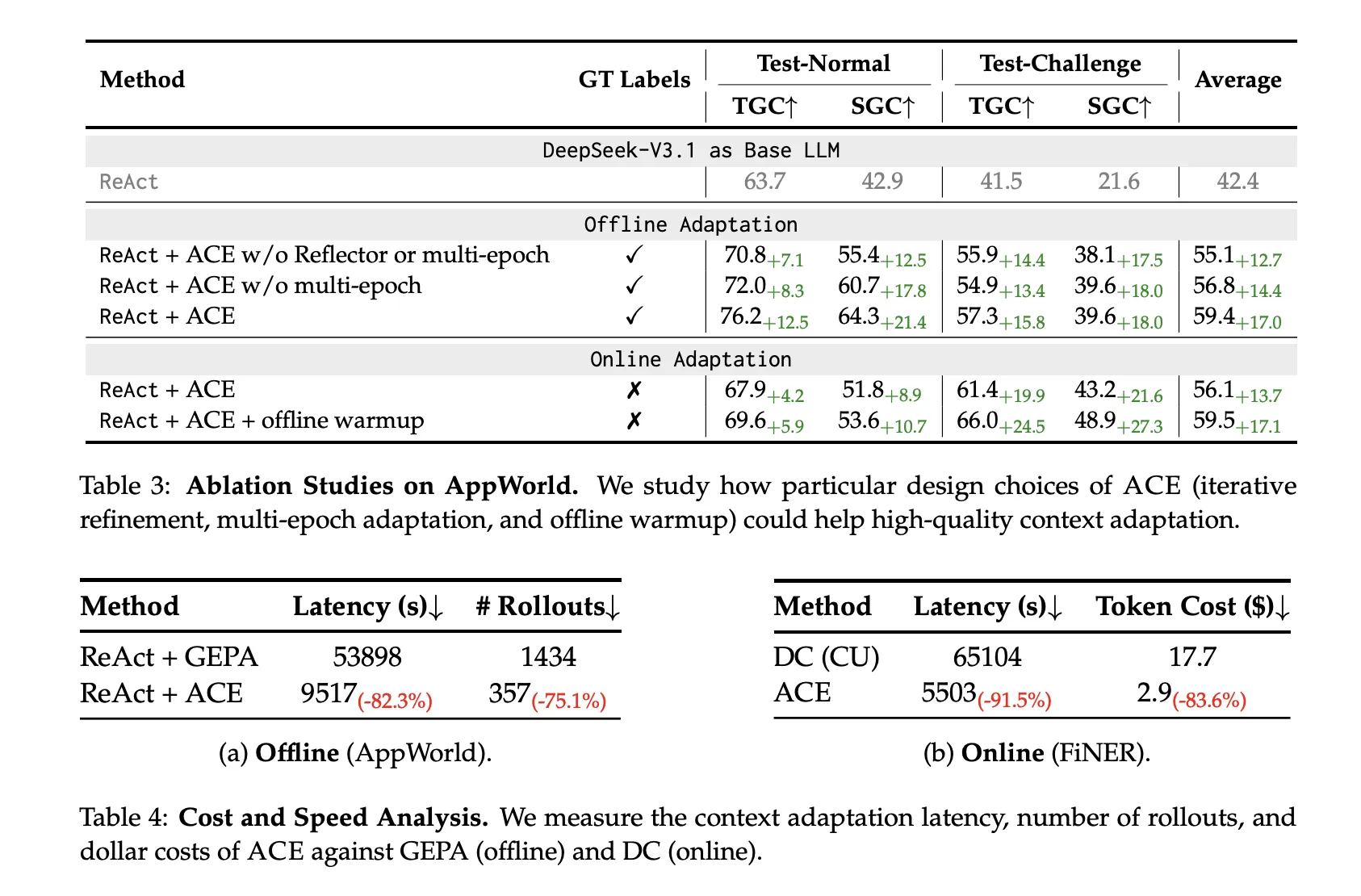
prices and delays
Ace-san Non-LLM merge Moreover, localized updates considerably cut back adaptation overhead.
- Offline (AppWorld): −82.3% latency and −75.1% growth versus Gepa.
- On-line (FiNER): −91.5% delay and −83.6% token value versus dynamic cheat sheet.
Necessary factors
- ACE = Context-first adaptation: Enhance LLM by step-by-step enhancing of evolving “playbooks” (delta gadgets) curated by Generator → Reflector → Curator. identical We use a base LLM (non-thinking DeepSeek-V3.1) to isolate the results of context and keep away from collapse because of monolithic rewrites.
- Measured achieve: ReAct+ACE report +10.6% Obtain past AppWorld’s robust baseline 59.4% versus IBM CUGA 60.3% (GPT-4.1) Leaderboard snapshot for September 20, 2025. Monetary Benchmark (FiNER + XBRL Formulation) Present +8.6% Imply above baseline.
- Decrease overhead than reflective rewrite baseline: ACE reduces adaptation delay by: ~82 ~ 92% and rollout/token value ~75~84%in distinction to Dynamic Cheatsheet’s persistent reminiscence and GEPA’s Pareto-prompted evolutionary approaches.
conclusion
ACE positions context engineering because the premier various to weight updates. This implies sustaining persistent, curated playbooks that accumulate task-specific ways to scale back adaptive latency and token rollout in comparison with reflective rewrite baselines whereas delivering tangible advantages in AppWorld and monetary inference. Whereas this method is sensible with deterministic merging, delta gadgets, and lengthy context-aware providers, its limitations are apparent. Outcomes monitor suggestions high quality and job complexity. If adopted, the agent stack may “self-adjust” primarily via evolving context relatively than new checkpoints.
Please verify paper is here. Please be happy to test it out GitHub page for tutorials, code, and notebooks. Please be happy to observe us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per 30 days, demonstrating its recognition amongst viewers.

{kind=link}