


Liquid AI has launched LFM2-Audio-1.5B, a compact audio language primary mannequin that understands and generates speech and textual content via a single end-to-end stack. It’s positioned in the direction of low latency real-time assistants on resource-constrained units, extending the LFM2 household to audio whereas retaining a small footprint.
However what’s actually new? Unified spine with direntangled audio I/O
LFM2-Audio extends the 1.2B-Parameter LFM2 Language Spine to deal with audio and textual content as first-class sequence tokens. What’s vital is the mannequin Leisure Audio Illustration: The enter is a steady embedding projected immediately from uncooked waveform chunks (~80 ms), whereas the output is discrete audio code. This avoids discretization artifacts on the enter path whereas protecting coaching and technology autoregent for each modalities on the output path.
The implementation makes use of the launched checkpoint.
🚨 [Recommended Read] Vipe (Video Pause Engine): A strong and versatile 3D video annotation software for spatial AI
- spine: LFM2 (Hybrid Conv + Atterness), 1.2b Params (LM solely)
- Audio encoder: FastConformer (~115m, Canary-180m-Flash)
- Audio decoder: RQ-Transformer predicts discrete Mimi Codec Token (8 Codebook)
- context: 32,768 tokens; vocab: 65,536 (Textual content) / 2049×8 (Audio)
- accuracy: BFLOAT16; license: LFM Open License v1.0; language: English
Two technology modes for real-time brokers
- Interleaved technology For reside speech to speech chat the place the mannequin alternates between textual content and audio tokens, minimizing perceived latency.
- Sequential technology For ASR/TTS (turning modality by turn-by-turn).
LiquidAI supplies Python packages (liquid-audio) and a gradient demo that reproduces these behaviors.
Latency: <100ms from the primary audio
The Liquid AI Crew stories end-to-end latency beneath 100 milliseconds From a 4-second audio question to the primary audible response (a proxy for acknowledged responsiveness in interactive use), it states that it’s quicker than the mannequin underneath setup than the 1.5B parameter.
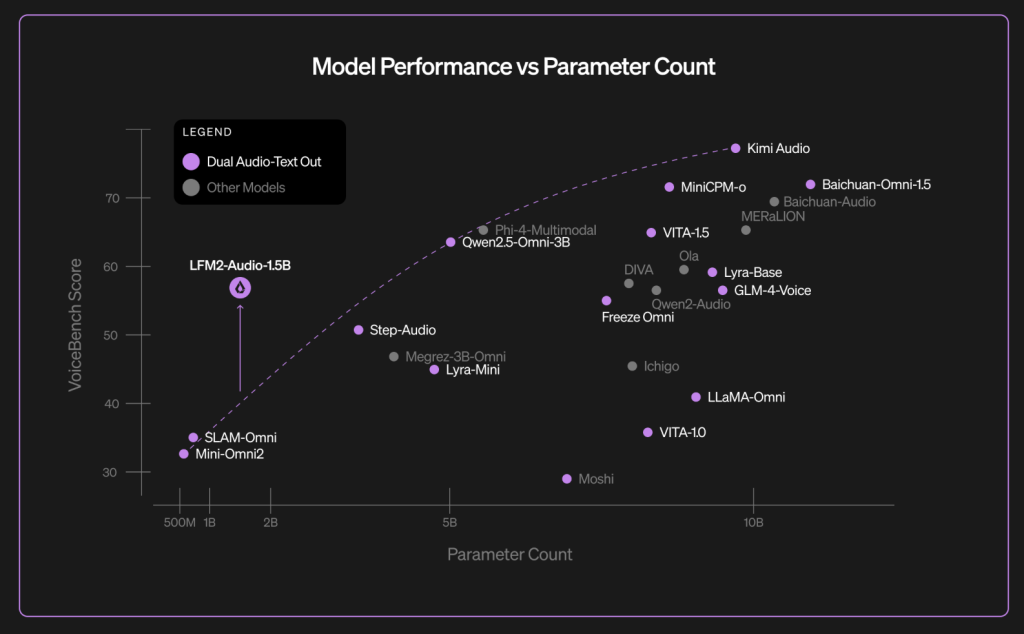
Benchmark: Voice bench and ASR outcomes
Above Voice bench– 9 Audio Assistant Evaluate Suite – liquid Reviews an Total rating of 56.78 For LFM2-Audio-1.5B, task-specific numbers are disclosed within the weblog chart (for instance, Alpacaeval 3.71, Commoneval 3.49, WildVoice 3.17). The Liquid AI crew contrasts this outcome with bigger fashions such because the QWEN2.5-OMNI-3B and MOSHI-7B in the identical desk. (VoiceBench is an exterior benchmark launched in late 2024 for LLM-based voice assistants.)
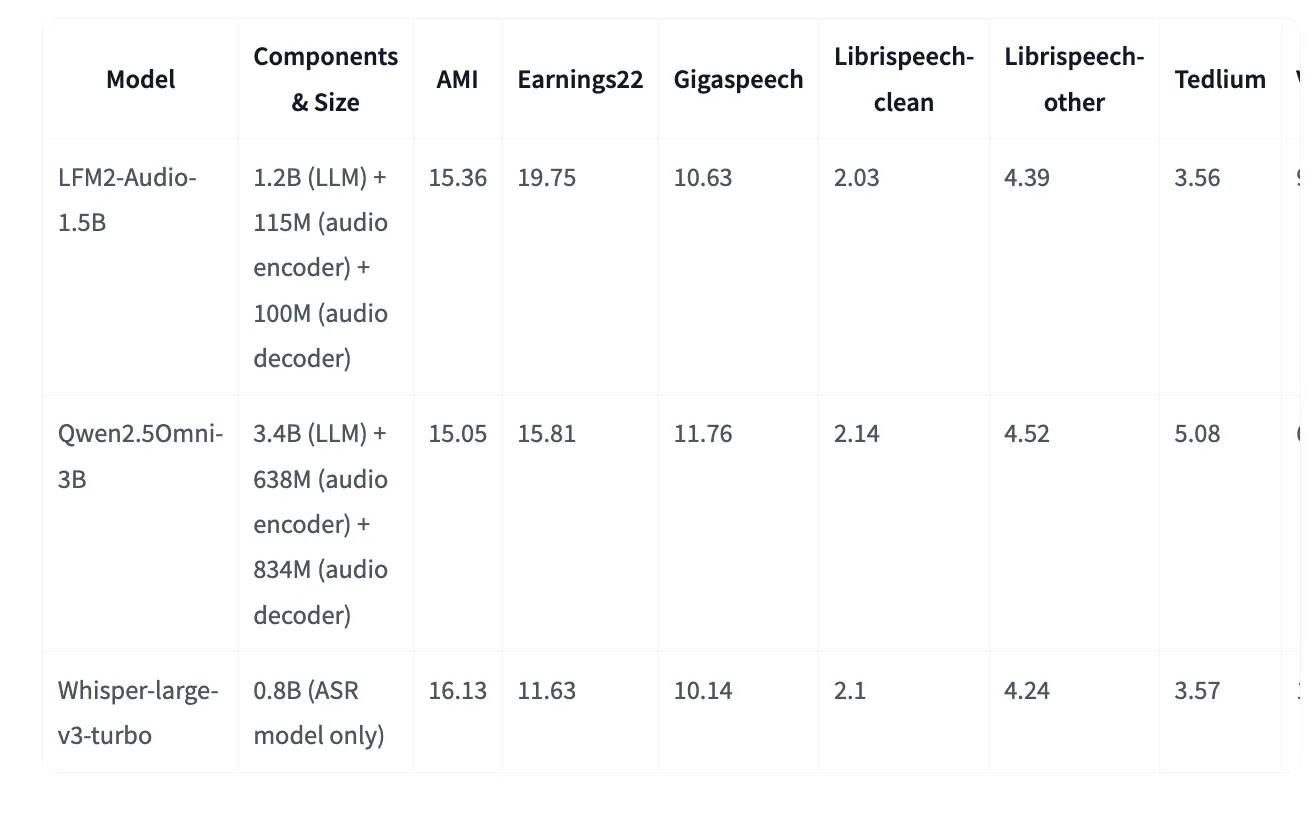
The Hagging Face mannequin card supplies an extra voice bench desk (which is intently associated however not similar, however has values per job worth). ASR LFM2-Audio is the place it matches or improves whispers-V3 turbo for some datasets, regardless of being a generalist speech and textual content mannequin. For instance (decrease is best): AMI 15.36 vs 16.13 (Whisper-Massive-V3 Turbo), Librispeech Clear 2.03 vs 2.10.
It is okay, however why is it actually vital within the tendencies in AI for voice?
Most “Omni” stacks couple ASR→LLM→TTS. This provides latency and brittle interfaces. The one spine design of LFM2-Audio with steady enter embedding and discrete output code reduces adhesive logic and permits for interleaved decoding for early audio ejection. For builders, this interprets to quicker perceptual response instances, supporting an easier pipeline and ASR, TTS, classification, and conversational brokers from one mannequin. LiquidAI supplies code, demo entry factors, and distribution through hugging faces.
Please verify github page, Embracing face model card and Technical details. Please be happy to verify GitHub pages for tutorials, code and notebooks. Additionally, please be happy to comply with us Twitter And do not forget to affix us 100k+ ml subreddit And subscribe Our Newsletter. cling on! Are you on a telegram? You can now join Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the probabilities of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is simple to know by a technically sound and vast viewers. The platform has over 2 million views every month, indicating its recognition amongst viewers.
🔥[Recommended Read] Nvidia AI Open-Sources Vipe (Video Pause Engine): A strong and versatile 3D video annotation software for spatial AI

{kind=link}