


Introducing it by a crew of researchers from Metalareality Lab and Carnegie Mellon College mapanythingan end-to-end trans structure that straight regresses factored metric 3D scene geometry from photos and elective sensor inputs. Launched in Apache 2.0 with full coaching and benchmark code, Mapanything advances past the specialised pipeline by supporting over 12 3D imaginative and prescient duties with a single feedforward move.

Why is that this a common mannequin for 3D reconstruction?
Picture-based 3D reconstruction has traditionally relied on fragmented pipelines: characteristic detection, two-view pose estimation, bundle adjustment, multiview stereo, or monocular depth inference. Though efficient, these modular options require task-specific tuning, optimization and heavy post-processing.
Current transformer-based feedforward fashions such because the Dust3R, Mast3R, and VGGT are a simplified a part of this pipeline, however remained restricted.
Mapanything overcomes these constraints by:
- settle for 2,000 enter photos It’s carried out on a single inference.
- Versatile use of the next supplementary information Digicam endogenous, pose, and depth map.
- manufacturing Direct Metric 3D Reconstruction No bundle changes.
The mannequin’s factored scene illustration (mixed with raymap, depth, pose, and world scale components) gives unparalleled modularity and generality to earlier approaches.
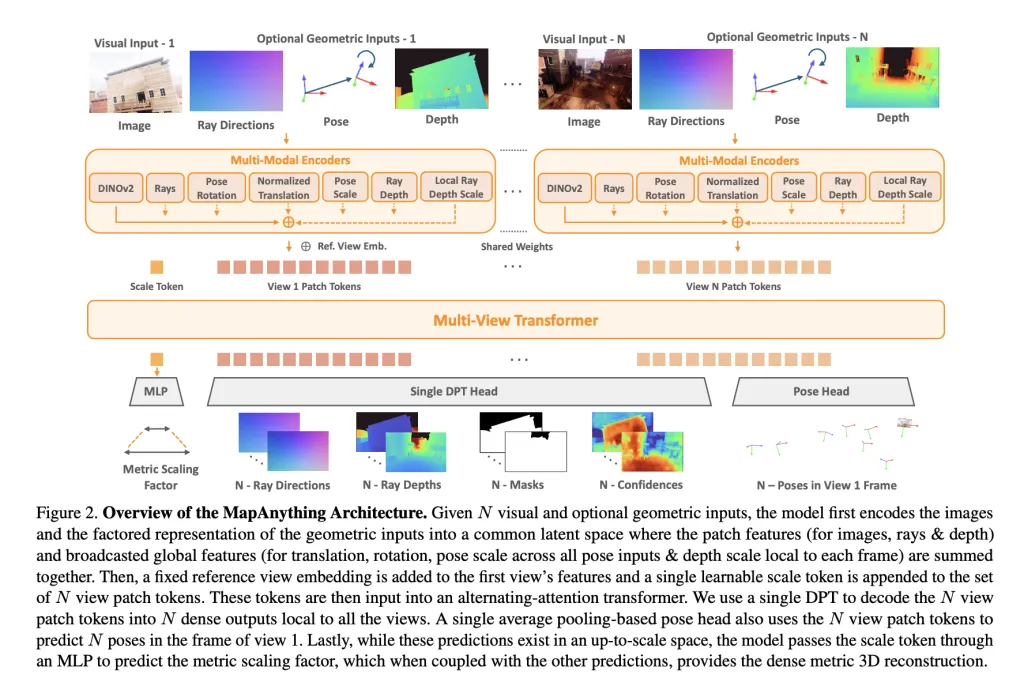
Structure and Expression
At its coronary heart, Mapanything makes use of a Multi-view alternating motion transformer. Every enter picture is encoded with dinov2 vit-l Options embody elective inputs (rays, depth, poses) being encoded into the identical latent house through shallow CNN or MLP. a Learnable scale token Allows metric normalization throughout views.
Community output a Factored illustration:
- Every view Lei path (Digicam calibration).
- Depth alongside the raynewest forecast scale.
- Digicam pose For reference views.
- single Metric Scale Issue Converts native reconfigurations into globally constant frames.
This express factoring avoids redundancy and permits the identical mannequin to deal with monocular depth estimation, multi-view stereo, construction from construction (SFM), or depth completion with out particular heads.
Coaching Technique
Mapanything has been totally skilled 13 Numerous Information Units Spanning indoor, out of doors and artificial domains, together with blended MVs, paralysis planetary depth, scannet++, and tartanairv2. Two variants can be launched.
- Apache 2.0 license Mannequin skilled on six datasets.
- CC by-nc mannequin It’s skilled on all 13 datasets to reinforce efficiency.
Key coaching methods embody:
- Probabilistic enter dropout: Throughout coaching, geometric inputs (rays, depths, poses) are supplied with various odds, permitting for robustness of your complete heterogeneous configuration.
- Co-based sampling: Verify that there are significant duplicates within the enter view and assist rebuilding as much as 100 or extra views.
- Issue log house loss: Depth, scale, and pose are optimized utilizing scale-invariant and sturdy regression losses for improved stability.
Coaching was accomplished 64 H200 GPU It combines precision, gradient checkpoints, and curriculum scheduling to scale 4-24 enter views.
Benchmark outcomes
Multiview dense reconstruction
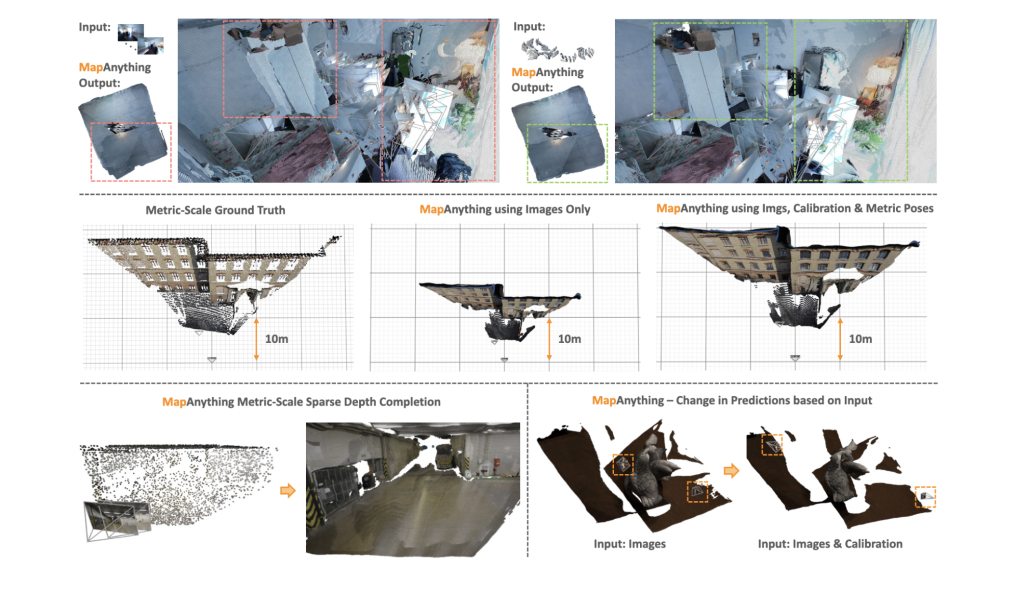
Mapanything achieves with ETH3D, Scannet++ V2, and Tartanairv2-WB The innovative (Sota) General efficiency of level maps, depth, poses, and ray estimates. Even if you’re restricted to pictures solely, you may nonetheless surpass baselines comparable to VGGT and Pow3R, and enhance additional with calibration or pause preferences.
for instance:
- Level Map Relative Error (REL) In comparison with VGGT’s 0.20, the picture alone improves to 0.16.
- Picture + Intricix + Pause + Depth, the error will drop to 0.01achieves an inlier ratio of greater than 90%.
Reconfigure 2 views
For Dust3R, Mast3R, and Pow3R, Mapanything constantly outperforms past scale, depth, and pose accuracy. Particularly, further advances are achieved > 92% inlier ratio The two-view process considerably exceeds the earlier feedforward mannequin.
Single View Calibration
Regardless of not being specifically skilled for single picture calibration, mapanything is 1.18° common angle erroroutperforms Anycalib (2.01°) and Moge-2 (1.95°).
Depth Estimation
Concerning the sturdy MVD benchmark:
- mapanything units up a brand new Sota Multiview Metric Depth Estimated.
- With auxiliary enter, its error price is comparable or exceeded that of particular depth fashions comparable to MVSA and Metric3D V2.
General, the benchmark has been confirmed 2x enhancements over the earlier SOTA methodology Many duties study the advantages of unified coaching.
Vital contributions
The analysis crew highlights 4 main contributions:
- Unified feedforward mannequin It may possibly deal with over 12 drawback settings, from monocular depth to SFM and stereo.
- Factored scene illustration Permits express separation of rays, depth, poses, and metric scales.
- Slicing-edge efficiency A various total benchmark with little redundancy and excessive scalability.
- Open Supply Launch Contains information processing, coaching scripts, benchmarks and pre-protected weights underneath Apache 2.0.
Conclusion
Mapanything establishes new benchmarks for 3D imaginative and prescient by integrating a number of reconstruction duties of SFM, stereo, depth estimation, and calibration, underneath a single transformer mannequin that takes under consideration scene illustration. Not solely is it higher than the skilled strategies throughout benchmarks, it additionally seamlessly adapts to heterogeneous inputs comparable to endogenousness, poses, and depth. With open supply code, prerequisite fashions and assist for over 12 duties, Mapanything lays the inspiration for a really generic 3D reconstruction spine.
Please test paper, code and Project Page. Please be happy to test GitHub pages for tutorials, code and notebooks. Additionally, please be happy to comply with us Twitter And remember to hitch us 100k+ ml subreddit And subscribe Our Newsletter.

Mikal Sutter is an information science professional with a Grasp’s diploma in Information Science from Padova College. With its stable foundations of statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.
🔥[Recommended Read] Nvidia AI Open-Sources Vipe (Video Pause Engine): A robust and versatile 3D video annotation instrument for spatial AI

{kind=link}