


The substitute intelligence panorama continues to evolve quickly with breakthroughs that push the boundaries that fashions can obtain with inference, effectivity, and utility versatility. Newest launch from Nvidia – The Llama Nemotron Tremendous v1.5– Exhibits a notable leap in each efficiency and usefulness, particularly for agent-intensive duties. This text examines intimately the technological advances and sensible implications of the Llama Nemotron Tremendous V1.5.
Abstract: Llama Nemotron Tremendous V1.5 Context
Nvidia’s Nemotron household is understood for constructing on probably the most highly effective open supply large-scale language fashions, growing and enhancing accuracy, effectivity and transparency. Llama Nemotron Tremendous v1.5 It stands as the newest and most superior iterations explicitly designed for high-stakes inference situations similar to arithmetic, science, code technology, agent performance.
What units the Nemotron Tremendous v1.5 aside?
The mannequin is designed as follows:
- Offers innovative accuracy Science, Arithmetic, Coding, and Agent Duties.
- Please obtain 3x larger throughput In comparison with earlier fashions, will probably be sooner and more cost effective in the direction of deployment.
- Works effectively with a Single GPUcatering from particular person builders to enterprise-scale purposes.
Technical innovation behind the model
1. Post-training improvements for high-level data
Nemotron Super V1.5 is based on an efficient reasoning foundation established by Llama Nemotron Ultra. The advances in Super V1.5 come from Post-training improvements using new proprietary datasets,This focuses on high signal inference tasks. This targeted data amplifies the functionality of the model with complex, multi-step problems.
2. Searching and pruning neural architectures for efficiency
The key innovation in v1.5 is Neural Architecture Search and Using Advanced Pruning Techniques:
- By optimizing the network structure, Nvidia increased throughput (inference speed) without sacrificing accuracy.
- The model runs faster, allowing more complex inferences per unit of calculation, and lower inference costs.
- The ability to deploy on a single GPU minimizes hardware overhead and provides strong access to small teams as well as large organizations.
3. Benchmarks and performance
Crossing a wide range of public and internal benchmarks, The Llama Nemotron Super V1.5 is consistently leading in its weight classespecially for required tasks:
- Multi-step reasoning.
- Using structured tools.
- Next instruction, code integration, and agent workflow.
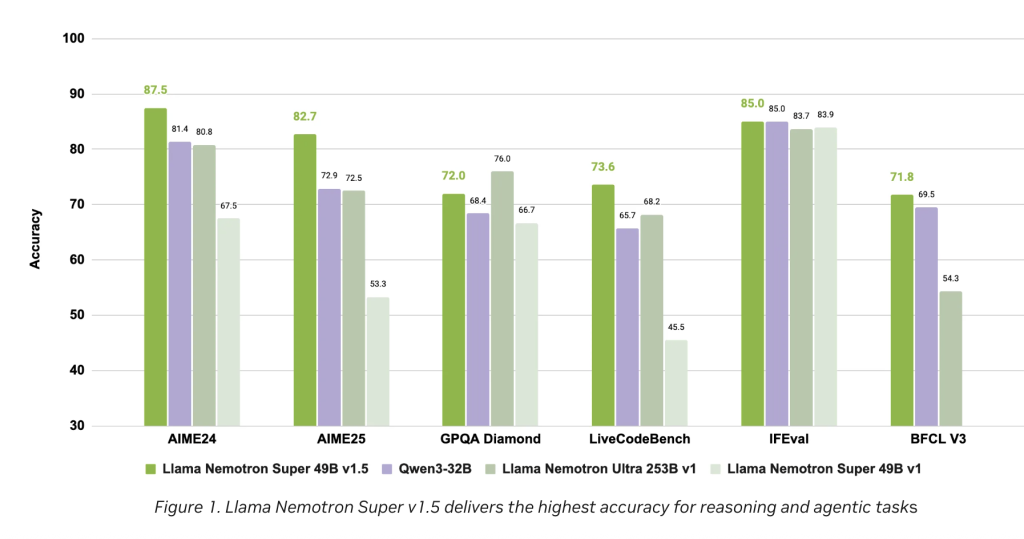
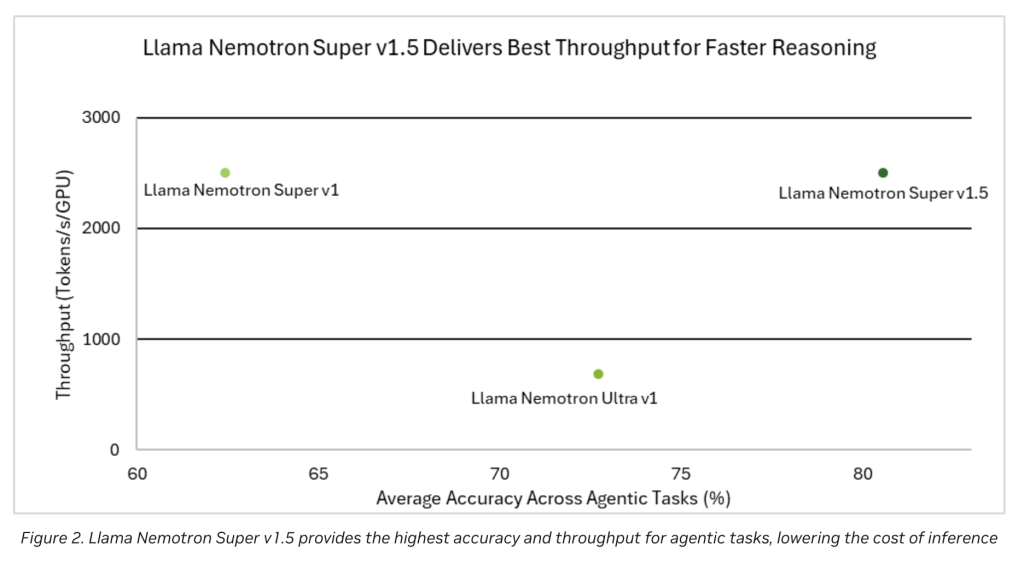
The performance chart (see Figures 1 and 2 in the release notes) is visible.
- The highest accuracy of core inference and agent tasks Compare with major open models of similar sizes.
- Best ThroughputTransform processing and inference faster when reducing operational costs.
Key Features and Benefits
Cutting-edge accuracy in reasoning
Improvements to the high signal dataset ensure that Llama Nemotron Super v1.5 is excellent at scientific refined queries, complex mathematical problem solving, and generating reliable, maintainable code. This is important for real AI agents who must interact, infer, and act in action within their applications.
Throughput and operational efficiency
- 3x higher throughput: Optimization makes the model work more queries per second, making it suitable for real-time use cases and large numbers of applications.
- Reduce calculation costs: Efficient architectural design and ability to run on a single GPU removes scaling barriers for many organizations.
- Reduce deployment complexity: Streamline your deployment pipeline across platforms by minimizing hardware requirements while improving performance.
Built for agent applications
llama nemotron super v1.5 doesn’t just answer questions. Agent Task,If the AI model needs to work proactively, you need to follow the instructions, invoke functions and integrate them with tools and workflows. This adaptability gives the model the ideal foundation for:
- Conversation agent.
- Autonomous Code Assistant.
- Science and Research AI Tools.
- An intelligent automation agent deployed in an enterprise workflow.
Practical development
The model is Available now For practical experiences and integration:
- Interactive Access: Enable users and developers to test their functionality in live scenarios directly to Nvidia Build (build.nvidia.com).
- Open Model Download: Available with embraced faces, ready for deployment on custom infrastructure, or include in a wider AI pipeline.
How Nemotron Super V1.5 pushes the ecosystem forward
Openweights and community impact
Continuing Nvidia’s philosophy, the Nemotron Super V1.5 is now available as an open model. This transparency grows:
- Fast community-driven benchmarking and feedback.
- Easy customization of special domains.
- Larger collective scrutiny and iteration, reliable and robust AI models appear all over.
Companies and research preparation
With a unique blend of performance, efficiency and openness, the Super V1.5 is The backbone of the next generation AI agent in:
- Enterprise Knowledge Management.
- Customer support automation.
- Advanced research and scientific computing.
Working with AI best practices
Combine it High quality synthetic data set From Nvidia and cutting-edge model improvement technology, the Nemotron Super v1.5 adheres to key standards.
- Transparency in data and method training.
- Strict quality assurance for model output.
- Responsible and interpretable AI.
Conclusion: A new era of AI inference models
Llama Nemotron Super v1.5 An important advancement in the open source AI landscape, offering top-notch reasoning aptitude, transformational efficiency and wide applicability. Developers who aim to build trustworthy AI agents, whether individual projects or complex enterprise solutions, this release marks milestones and sets new standards for accuracy and throughput.
With its continued commitment to openness, efficiency and community collaboration, the Llama Nemotron Super V1.5 is poised to accelerate the development of smarter, more capable AI agents designed for the diverse challenges of tomorrow.
Please check Open Source Weight and Technical details. All credit for this examine will probably be directed to researchers on this mission. Additionally, please be happy to comply with us Twitter And do not forget to affix us 100k+ ml subreddit And subscribe Our Newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the probabilities of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is simple to know by a technically sound and huge viewers. The platform has over 2 million views every month, indicating its reputation amongst viewers.


{kind=link}