


Demystifying GQA — Grouped Question Consideration for Environment friendly LLM Pre-Coaching
Multi-head consideration variants that improve LLM corresponding to LLaMA-2, Mistral7B, and so forth.
In our earlier article on coaching giant fashions, we mentioned LoRA. On this article, we think about Grouped Question Consideration (GQA), one other technique employed by varied large-scale language fashions for environment friendly coaching. In different phrases, grouped querier consideration (GQA) is a generalization of multihead consideration (MHA) and multiquerier consideration (MQA), every of which is a particular case of his GQA. Subsequently, earlier than we get into grouped question consideration, let’s take one other have a look at the standard multi-headed consideration proposed by Vaswani et al. In his seminal “Warning is the Necessity” paper. Subsequent, we think about multiquery consideration and the way it addresses MHA challenges. Lastly, I’ll reply the query, “What’s GQA?” “How can we get the very best of each worlds?”
Multi-headed consideration is a key element of the Transformer mannequin, permitting it to effectively course of and perceive advanced sequences in duties corresponding to language translation and summarization. To grasp its complexity, we have to delve into the mathematical foundations and perceive how the a number of heads of the eye mechanism work.
The fundamental consideration mechanism computes a weighted sum of values utilizing weights relying on the question and set of keys. Mathematically, that is expressed as:
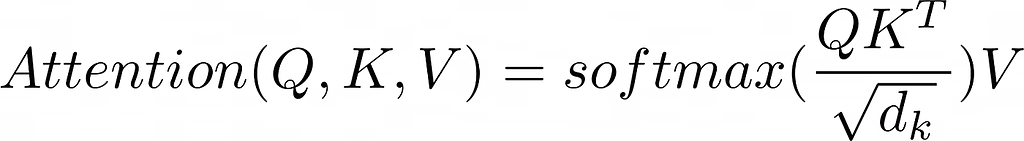
That is referred to as Notes on scaled dot merchandise. On this system, Q (question) and Ok (key) are matrices representing the question and key. V (worth) is a matrix of values. “d_k” is the important thing dimension and is used for scaling.
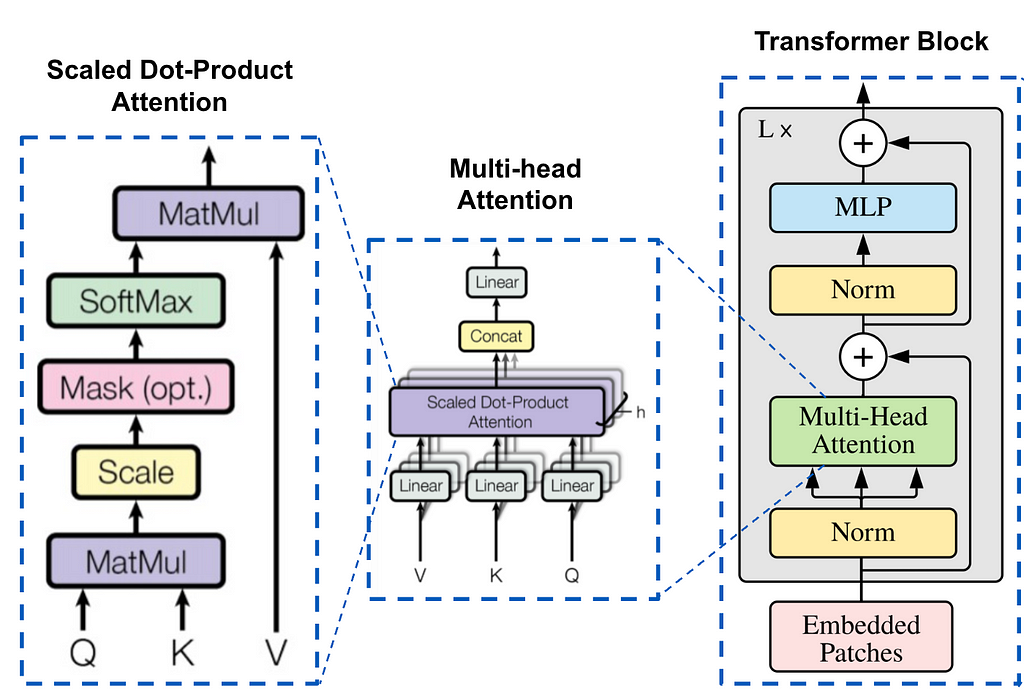
Augmented with Multi-Head Consideration (MHA)
Multi-head consideration employs an consideration layer of a number of “heads” that enables the mannequin to take care of data from totally different representational subspaces. Every head has a set of unbiased linear layers (projection matrices) of queries, keys, and values (this is a vital level and can be revisited in GQA). For every head (h numbered):
headʰ = consideration(Q.Wqʰ、Ok.Wkʰ、V.Wvʰ)
Connection of head outputs
The outputs of the person heads are concatenated after which linearly remodeled.
Multi head (Q,Ok,V) = Concat(head¹,head²,…,headʰ) .Wᵒ
Wᵒ is one other weight matrix that linearly transforms the concatenated vectors to the ultimate output dimensions.
The instinct behind multi-headed consideration is that by making use of the eye mechanism a number of instances in parallel, the mannequin can seize totally different sorts of relationships within the knowledge.
Nevertheless, MHA permits for a extra nuanced understanding of the relationships between totally different elements of the enter. Nonetheless, this complexity comes at a value, requiring important reminiscence bandwidth, particularly throughout decoder inference.
Reminiscence bandwidth challenges with multihead consideration
The core of the issue lies in reminiscence overhead. Every decoding step of an autoregressive mannequin like Transformers requires loading the decoder weights together with all consideration keys and values. This course of will not be solely computationally intensive, but in addition reminiscence bandwidth intensive. As the scale of the mannequin will increase, this overhead additionally will increase, making scaling up an more and more troublesome activity.
The emergence of multi-query consideration (MQA)
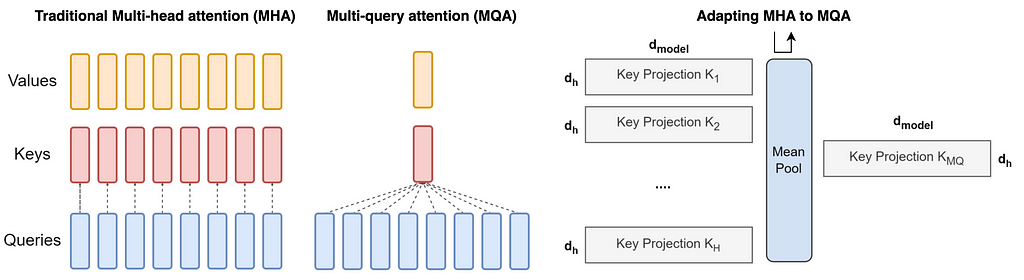
Multi-query consideration (MQA) has emerged as an answer to alleviate this bottleneck. This concept is easy however efficient. Use a number of question heads, however just one key-value head. This strategy considerably reduces reminiscence stress and will increase inference pace. It has been adopted by a number of large-scale fashions corresponding to PaLM, StarCoder, and Falcon.
Multi-query consideration averages the important thing and worth heads so that each one question heads share the identical key and worth heads. That is achieved by replicating the typical pooled “head” H instances. Right here, H is the variety of question heads.
An attention-grabbing query to ask right here is the best way to convert an current pre-trained multi-head consideration mannequin to a multi-query consideration mannequin (MQA). Making a multi-querier rigidity mannequin from an current multi-head mannequin requires his two-step course of: transformation of the mannequin’s construction and subsequent pre-training. [1]
Checkpoint conversion: This step converts the construction of the multihead mannequin right into a multiquery mannequin. That is achieved by merging the key-value projection matrices (linear layers) from a number of heads of the unique mannequin right into a single key-value projection matrix (common pooling). This common pooling strategy has been discovered to be more practical than selecting one of many current key-value heads or initializing a brand new key-value head from scratch. The ensuing construction features a unified key-value projection that’s attribute of multiquery fashions.
Pre-training the remodeled mannequin: After the structural transformation, the mannequin undergoes extra coaching. This coaching will not be as intensive because the coaching of the unique mannequin. That is a part of the coaching step (denoted α) of the unique mannequin. The aim of this pre-training section is to permit the mannequin to tune and optimize its efficiency in line with the brand new simplified consideration mechanism. Coaching follows the identical recipe as the unique, making certain consistency in studying dynamics.
Nevertheless, MQA will not be with out its drawbacks. Lowering complexity can result in lowered high quality and coaching instability.
Grouped question consideration
Grouped Question Consideration (GQA) is a straightforward strategy that mixes components of Multihead Consideration (MHA) and Multiquery Consideration (MQA) to create a extra environment friendly consideration mechanism. The mathematical framework of GQA will be understood as follows.
Partitioning into teams: In GQA, the question head (Q) of the standard multi-head mannequin is partitioned into G teams. Every group is assigned a single key (Ok) and worth (V) head. This configuration is denoted as GQA-G. Right here, G represents the variety of teams.
Particular case of GQA:
- GQA-1 = MQA: If there is just one group (G = 1), GQA is equal to MQA as a result of there is just one key-value head for each question head.
- GQA-H = MHA: When the variety of teams is the same as the variety of heads (G = H), GQA behaves like conventional MHA, and every question head has a novel key-value head.
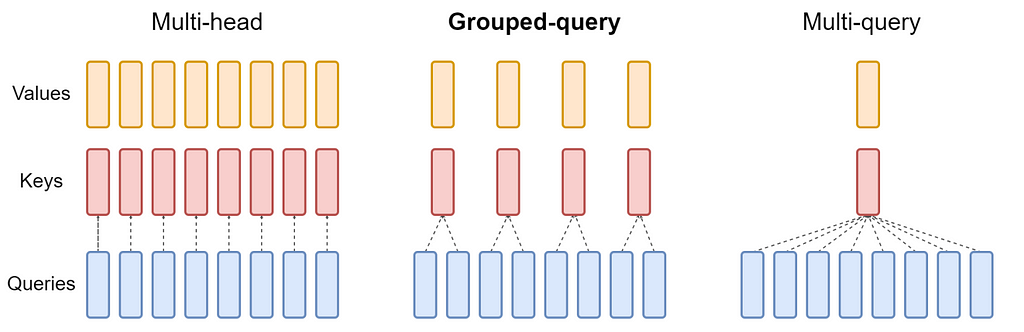
Convert the multi-head mannequin to a GQA mannequin by averaging pooling the important thing and worth projection matrices of the unique heads in every group. On this approach, the projection matrices of every head in a bunch are averaged to acquire a single key-value projection for that group.
By leveraging GQA, this mannequin maintains a stability between MHA high quality and MQA pace. Fewer key-value pairs reduce reminiscence bandwidth and knowledge loading necessities. There are trade-offs in selecting G. Extra teams (nearer to MHA) present increased high quality however decrease efficiency. Alternatively, having fewer teams (nearer to MQA) will increase pace however dangers sacrificing high quality. Moreover, because the mannequin measurement will increase, GQA can proportionally scale back reminiscence bandwidth and mannequin capability relying on the mannequin scale. In distinction, for bigger fashions, MQA’s discount to a single key-value head will be too harsh.
conclusion
On this publish, we first mentioned conventional multi-head consideration (MHA) and its variation, multi-query consideration. Subsequent, we turned our consideration to a extra normal formulation, GQA, which is utilized in many LLM fashions for efficient pre-training. GQA combines multi-head consideration (MHA) and multi-query consideration (MQA) to supply a good trade-off between high quality and pace. GQA minimizes reminiscence bandwidth calls for by grouping question heads, making it appropriate for mannequin scaling. GQA is used rather than typical multi-head consideration in current fashions corresponding to LLaMA-2 and Mistral7B.
References:
[1] GQA: Coaching generalized multi-query transformer fashions from multi-head checkpoints —https://arxiv.org/pdf/2305.13245.pdf
[2] MQA: Quick Transformer Decoding: Just one write head required —https://arxiv.org/abs/1911.02150
[3] MHA: All you want is consideration. https://arxiv.org/abs/1706.03762
Demystifying GQA — Grouped Question Consideration was initially printed on In direction of Information Science on Medium and hold the dialog going by highlighting and responding to this story.

{kind=link}