


Perceive Video utilizing AI It’s essential to course of the sequence of pictures effectively. The primary problem of present video-based AI fashions is that they can not course of video as a steady stream, lack of vital movement particulars and fail to destroy continuity. This lack of time modeling prevents tracing of modifications. Due to this fact, occasions and interactions are partially unknown. Moreover, lengthy movies price plenty of computation and require strategies equivalent to body skipping, which leads to lack of worthwhile info and diminished accuracy. Duplicate between knowledge in frames additionally doesn’t compress properly, leading to useful resource redundancy and waste.
At present, video language fashions deal with movies as static body sequences Picture Encoder and Imaginative and prescient Language Projectorit’s troublesome to specific motion and continuity. Language fashions have to infer temporal relationships independently, leading to partial understanding. Subsampling of frames reduces computational load and impacts accuracy on the expense of eradicating helpful particulars. Token discount strategies equivalent to recursive KV cache compression and body choice add complexity with out bringing a lot enchancment. Superior video encoders and pooling strategies are helpful, however they’re inefficient and render lengthy video processing computationally intensive, relatively than scalable.
To handle these challenges, researchers nvidia, Rutgers College, UC Berkeley, mit, Nanjing Collegeand Caist suggestion storm (Spatio-temporal token discount in multimodal LLMS), a Mamba-based time projector structure for environment friendly processing of lengthy movies. Not like conventional strategies through which temporal relationships are inferred individually for every video body, language fashions are used to deduce temporal relationships, storm Add time info to the video token stage to eradicate computational redundancy and enhance effectivity. This mannequin improves video illustration with a two-way spatio-temporal scanning mechanism, whereas lowering the burden of temporal inference from LLM.
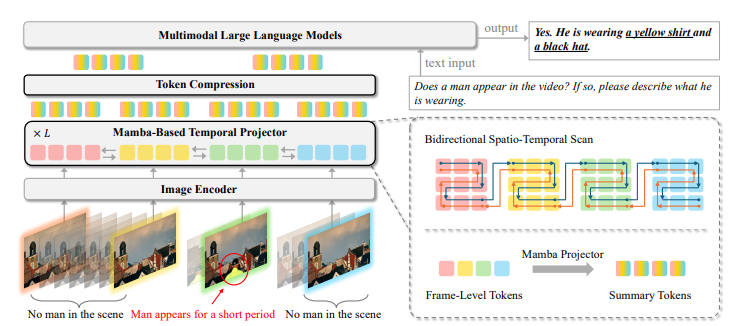
I exploit the framework Mamba Layer To boost temporal modeling, we incorporate a bidirectional scan module to seize dependencies throughout spatial and temporal dimensions. Time Encoder It handles picture and video enter otherwise, acts as a spatial scanner for imagery to combine international spatial contexts, and serves as a spatial scanner for video capturing temporal dynamics. Throughout coaching, token compression know-how improves computational effectivity whereas sustaining vital info and permits single inference GPU. Token subsampling with out coaching throughout testing additional diminished computational load whereas retaining vital temporal particulars. This method facilitated environment friendly processing of lengthy movies with out the necessity for specialised gear or deep adaptation.
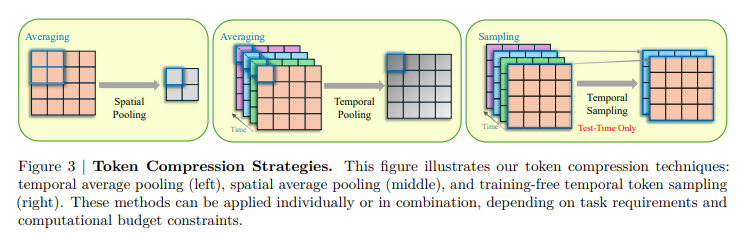
An experiment was performed to judge storm A mannequin for video understanding. Coaching was carried out utilizing pre-trained ones Siglip The mannequin incorporates a momentary projector launched via random initialization. Associated Processes two stage: Alignment stagethe picture encoder and LLM are frozen, solely the time projector is educated utilizing time textual content pairs, Monitored fine-tuning stage (SFT) Makes use of a various dataset of 12.5 million samples, together with textual content, picture textual content and video textual content knowledge. Token compression strategies, together with temporal and spatial pooling, diminished computational burden. The final mannequin was evaluated with a protracted video benchmark, equivalent to: Egokema, mvbench, mlvu, longvideobenchand videommeefficiency is in comparison with different video LLM.
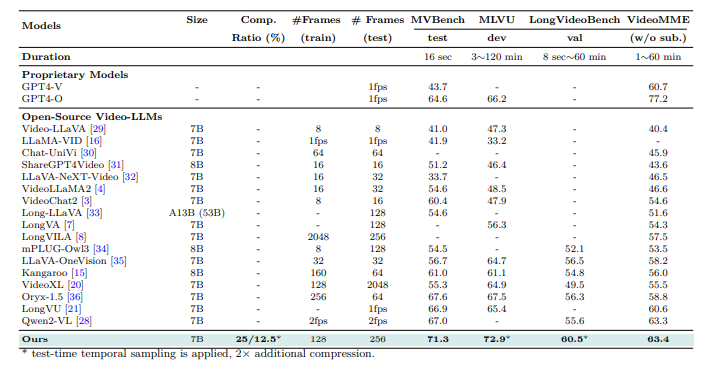
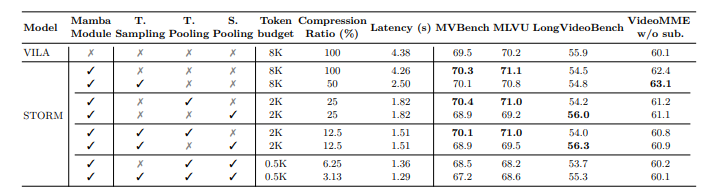
As soon as evaluated, Storm surpassed present fashions and achieved the most recent outcomes on the benchmark. MAMBA modules have improved effectivity by compressing visible tokens whereas retaining vital info and lowering inference time 65.5%. Short-term pooling works greatest on lengthy movies, optimizing efficiency with fewer tokens. Storm additionally carried out a lot better than baseline Villa Duties that contain understanding fashions, particularly international contexts. The outcomes examined the significance of MAMBA for optimized token compression. 8 In 128 Body.
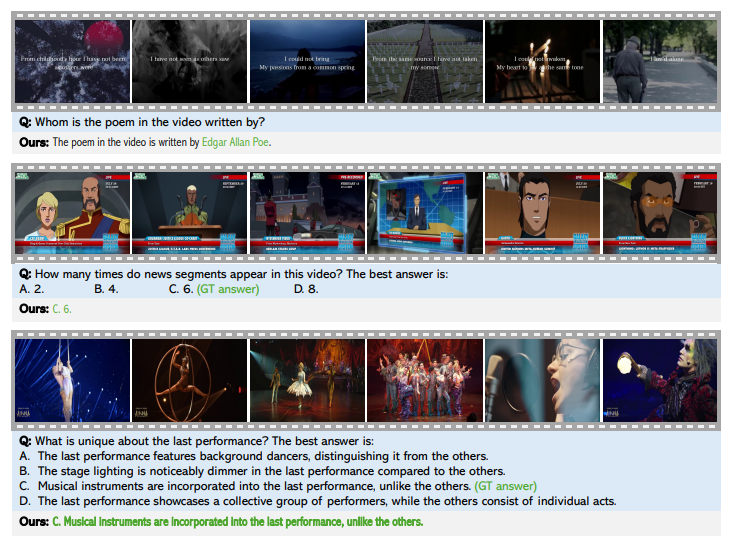
In abstract, the proposed storm mannequin improved lengthy video understanding utilizing Mamba-based time encoder and environment friendly token discount. It permits for highly effective compression with out shedding vital time info, protecting calculations low whereas recording cutting-edge efficiency with lengthy video benchmarks. This technique serves as a baseline for future analysis, selling innovation in token compression, multimodal alignment, and real-world deployments, enhancing the accuracy and effectivity of video language fashions.
Check out paper. All credit for this examine might be despatched to researchers on this challenge. Additionally, please be at liberty to observe us Twitter And remember to hitch us 80k+ ml subreddit.
Divyesh is a consulting intern at MarkTechPost. He pursues Btech in agriculture and meals engineering at Indian Institute of Expertise, Haragpur. He’s a knowledge science and machine studying fanatic who needs to combine these key applied sciences into the agriculture area and clear up challenges.

{kind=link}