


After the success of large-scale language fashions (LLMS), present analysis extends past text-based understanding to multimodal inference duties. These duties combine imaginative and prescient and language. That is important for synthetic basic data (AGI). Cognitive benchmarks akin to PuzzleVQA and algopuzzleVQA consider the AI’s means to course of summary visible data and algorithmic inference. Regardless of advances, LLMS struggles with multimodal inference, significantly sample recognition and spatial downside fixing. Excessive computational prices exacerbate these challenges.
Earlier evaluations relied on iconic benchmarks akin to ARC-AGI and visible assessments akin to Raven’s progressive matrix. Nonetheless, these don’t correctly problem the AI’s means to deal with multimodal inputs. Just lately, datasets akin to PuzzleVQA and AlgopuzzleVQA have been launched to judge summary visible inference and algorithm downside fixing. These datasets require fashions that combine visible notion, logical deductions, and structured inference. Earlier fashions akin to GPT-4-Turbo and GPT-4O demonstrated enhancements, however nonetheless confronted the restrictions of summary inference and multimodal interpretation.
Researchers at the Singapore Institute of Technology Design (SUTD) have introduced a systematic assessment of Openai’s GPT.[n] and o-[n] A model series about multimodal puzzle solving tasks. Their examine examined how reasoning means advanced throughout completely different mannequin generations. This examine goals to determine gaps in AI recognition, summary reasoning and problem-solving abilities. The staff in contrast the efficiency of fashions akin to GPT-4-Turbo, GPT-4O, and O1 in PuzzlevQA and AlgopuzzlevQA datasets, together with summary visible puzzles and algorithmic inference duties.
The researchers performed a structured evaluation utilizing two predominant information units.
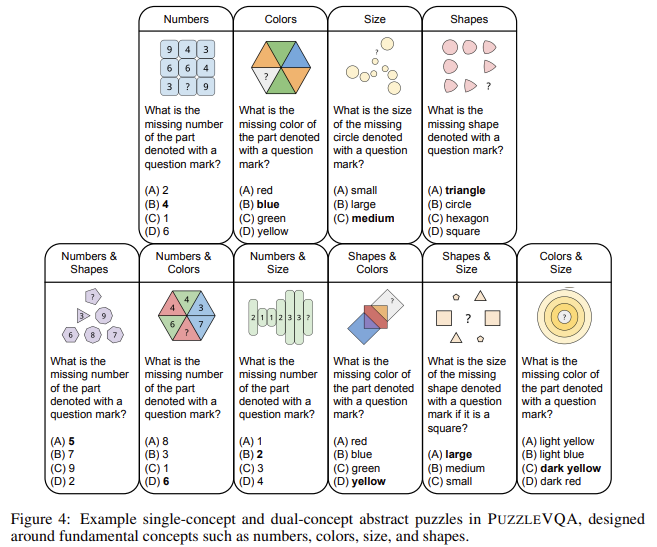
- PuzzleVQA: PuzzleVQA focuses on summary visible inference and requires a mannequin that acknowledges patterns of numbers, shapes, colours and sizes.
- algopuzzlevqa:algopuzzlevqa describes an algorithmic problem-solving job that requires logical deductions and computational inference.
Evaluations had been carried out utilizing each a number of alternative and open-ended query codecs. On this examine, we adopted a zero-shot chain (COT) to encourage inference and analyzed efficiency degradation when switching from a number of option to open-ended responses. The fashions had been additionally examined below circumstances the place visible notion and induced inference had been supplied individually to diagnose particular weaknesses.
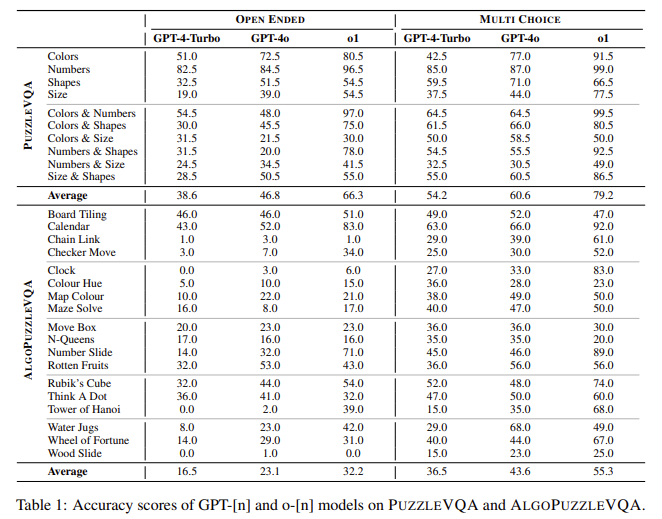
This examine noticed a gentle enchancment within the reasoning means of varied mannequin generations. The GPT-4o carried out higher than the GPT-4-turbo, whereas O1 achieved probably the most notable advances, significantly within the algorithmic inference job. Nonetheless, these advantages resulted in a pointy enhance in computational prices. Regardless of total advances, AI fashions nonetheless struggled with duties that required correct visible interpretation, akin to recognizing lacking shapes and deciphering summary patterns. O1 labored effectively with numerical inference, however was tough to deal with shape-based puzzles. The distinction in accuracy between a number of choice and open-ended duties signifies a powerful dependency on reply prompts. Additionally, recognition remained a significant problem in all fashions, as accuracy was vastly improved when specific visible particulars had been supplied.
With a easy abstract, the duty will be summarised into a number of detailed factors.
- On this examine, a big upward development in inference means from GPT-4-turbo to GPT-4O and O1 was noticed. GPT-4O confirmed reasonable advantages, however the transition to O1 resulted in important enhancements, however elevated computational prices by 750 instances in comparison with GPT-4O.
- Total, O1 achieved a median accuracy of 79.2% within the a number of choice setting, surpassing GPT-4O’s 60.6% and GPT-4-Turbo’s 54.2%. Nonetheless, within the open-ended job, all fashions confirmed efficiency drops, with O1 being 66.3%, GPT-4O being 46.8% and GPT-4-Turbo being 38.6%.
- In algopuzzlevqa, O1 was vastly improved in earlier fashions, particularly puzzles that require numerical and spatial deductions. O1 scored 55.3% in comparison with 43.6% for GPT-4O and 36.5% for GPT-4-Turbo on a number of alternative duties. Nonetheless, for open-ended duties, its accuracy was lowered by 23.1%.
- On this examine, notion was recognized as a significant limitation throughout all fashions. Injecting specific visible particulars improves accuracy by 22%-30%, indicating a dependence on exterior perceptual AIDS. Specifically, in numerical and spatial sample recognition, the inductive inference steerage elevated efficiency by 6% to 19%.
- O1 was wonderful at numerical reasoning, however struggled with shape-based puzzles, exhibiting a 4.5% drop in comparison with the form recognition job of GPT-4O. It additionally labored effectively in structured downside fixing, however confronted challenges in open-ended eventualities that require unbiased deductions.
Try paper and github page. All credit for this examine can be directed to researchers on this mission. Additionally, do not forget to observe us Twitter And be a part of us Telegram Channel and LinkedIn grOUP. Do not forget to affix us 75k+ ml subreddit.
Sana Hassan, a consulting intern at MarkTechPost and a dual-level scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a powerful curiosity in fixing actual issues, he brings a brand new perspective to the intersection of AI and actual options.

{kind=link}