


Since its debut in 2017, the Transformer structure has revolutionized nearly each pure language processing activity, from language fashions and masked phrase prediction to translation and query answering. It took only a few years for Transformers to start out excelling in pc imaginative and prescient duties as nicely. On this story, we’ll talk about two elementary architectures that enabled Transformers to enter the world of pc imaginative and prescient.
desk of contents
· Vision Transformer
∘ Key Idea
∘ Surgery
∘ Hybrid Architecture
∘ Loss of structure
∘ result
∘ Self-supervised learning by masking
· Mask Autoencoder Vision Transformer
∘ Key Idea
∘ Architecture
∘ Final comments and examples

Key Concept
Imaginative and prescient Transformer is Standard Transformer An structure that processes and learns from picture enter. There are some key concepts in regards to the structure that the authors clearly spotlight.
“Impressed by the success of scaling the Transformer in NLP, we’re experimenting with making use of the usual Transformer straight to photographs, with as few modifications as potential.”
Surgical procedure
““Minimal adjustments potential” As a result of it actually adjustments little or no – it really adjustments the enter construction.
- In NLP, the transformer encoder Sequence of one-hot vectors (or the equal token index) Represents an entered sentence/paragraph It then returns a sequence of context embedding vectors that can be utilized for additional duties (e.g. classification).
- To generalize CV, the imaginative and prescient transformer A sequence of patch vectors Represents Enter picture It then returns a sequence of context embedding vectors that can be utilized for additional duties (e.g. classification).
Specifically, assuming your enter picture has dimensions (n,n,3) and also you cross this because the enter to the transformer, the imaginative and prescient transformer does the next:
- As proven within the diagram above, for some okay (say, okay=3), we divide it into k² patches.
- Now every patch is (n/okay,n/okay,3) and the subsequent step is to flatten every patch right into a vector.
The patch vector can have dimension 3*(n/okay)*(n/okay). For instance, in case your picture is (900,900,3) and you utilize okay=3, then the patch vector can have dimension 300*300*3 and it represents the pixel values of the flattened patch. Within the paper, the authors use okay=16. So, the paper is titled “An Picture is Value 16×16 Phrases: Transformers for Picture Recognition at Scale”, and as an alternative of inputting a one-hot vector representing a phrase, you enter a vector pixel representing a patch of the picture.
The remaining operations are the identical as the unique transformer encoder.
- These patch vectors are handed by a learnable embedding layer.
- To protect a way of spatial data within the picture, a location embedding is added to every vector.
- The output is Variety of patches Encoder representations (one per patch) that can be utilized for classification at patch or picture stage
- Typically (as within the paper), the CLS token is prepended to the illustration used to make predictions on your entire picture (as in BERT).
What about transdecoders?
Nicely, keep in mind that that is precisely the identical as a Transformer Encoder, the distinction is that it makes use of masked self-attention as an alternative of self-attention (however the enter signature stays the identical). In any case, it is best to anticipate to not often use a decoder-only Transformer structure, since simply predicting the subsequent patch might not be a really fascinating activity.
Hybrid Structure
The authors state that it is usually potential to type a hybrid structure (the place the CNN feeds its output to a imaginative and prescient transformer) ranging from a CNN characteristic map slightly than the picture itself, by which case we contemplate the enter as a common (n,n,p) characteristic map, and the patch vector has dimensions (n/okay)*(n/okay)*p.
Lack of construction
You would possibly suppose that this structure cannot be that good, because it treats the picture as a linear construction, which it is not. The authors attempt to painting this as intentional,
“2D neighborhood buildings are used very not often… The situation embedding at initialization has no details about the 2D areas of the patches, and all spatial relationships between patches should be realized from scratch.”
We present that Transformers can be taught this, as evidenced by their wonderful efficiency in experiments and, extra importantly, by the structure of our subsequent paper.
outcome
The principle conclusion from the outcomes is that imaginative and prescient transformers have a tendency to not carry out higher than CNN-based fashions on small datasets, however strategy or outperform CNN-based fashions on giant datasets, and in any case require considerably much less computation.

Right here, for the JFT-300M dataset (containing 300 million pictures), we see {that a} ViT mannequin pre-trained on the dataset outperforms a ResNet-based baseline whereas drastically lowering the computational sources required for pre-training. As we will see, the most important imaginative and prescient transformer they used (ViT-Large with 632 million parameters and okay=16) makes use of about 25% of the computation utilized by the ResNet-based mannequin and nonetheless outperforms it. ViT-Massive makes use of lower than 6.8% of the computation, so its efficiency doesn’t lower as a lot.
Then again, it has been proven that ResNet performs considerably higher when educated on ImageNet-1K, which has just one.3 million pictures.
Self-supervised studying by masking
The authors carried out a preliminary research on masked patch prediction for self-supervision, mimicking the masked language modeling activity utilized in BERT (i.e., masking patches and making an attempt to foretell).
“In our preliminary self-supervised experiments, we make use of a masked patch prediction goal, by both changing 50% of the patch embeddings with learnable ones or [mask] Fill it in (80%), fill it with random different patches (10%), or go away it as is (10%).”
With self-supervised pre-training, the small ViT-Base/16 mannequin achieves 79.9% accuracy on ImageNet, a big 2% enchancment over coaching from scratch, however nonetheless 4% behind supervised pre-training.

Key Concept
As we noticed within the Imaginative and prescient Transformer paper, the advantages from pre-training by masking patches of the enter pictures weren’t as pronounced as in common NLP, the place masked pre-training may yield state-of-the-art outcomes on some fine-tuning duties.
On this paper, we suggest a imaginative and prescient transformer structure, together with an encoder and a decoder, that, when pre-trained with masking, considerably improves the bottom imaginative and prescient transformer mannequin (as much as 6% enchancment in comparison with coaching a base-sized imaginative and prescient transformer in a supervised method).

Listed here are the examples (enter, output, precise labels): That is an autoencoder within the sense that it tries to reconstruct the enter whereas filling within the lacking patches.
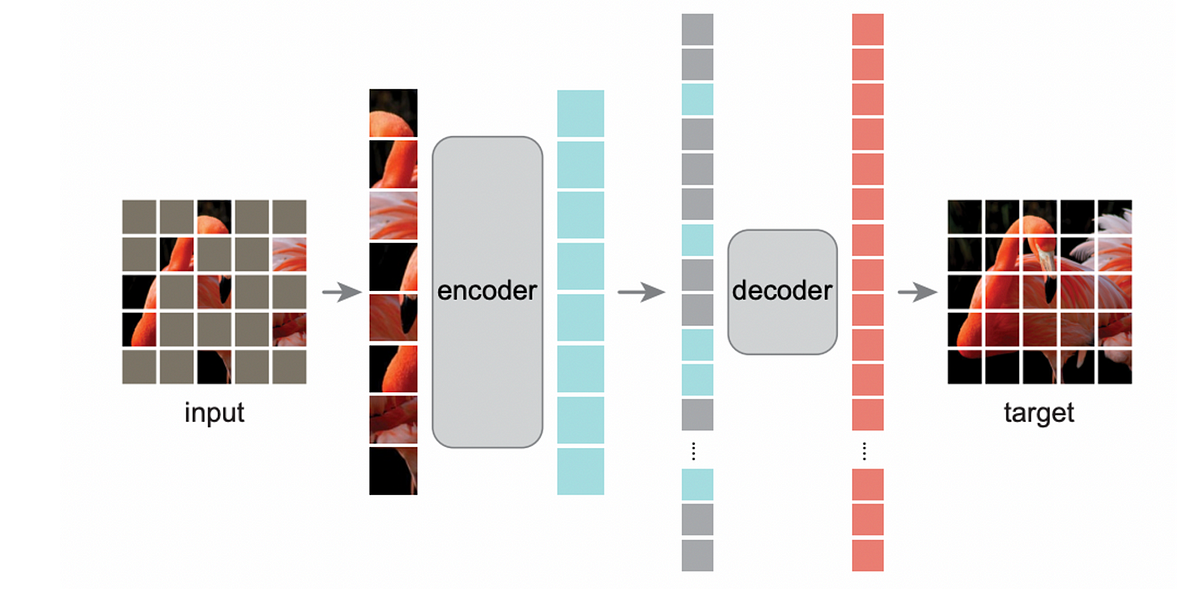
Structure
their Encoder is the common imaginative and prescient transformer encoder we mentioned earlier. For coaching and inference, we solely use the “noticed” patches.
Then again, their decoder Once more, this is identical as an everyday imaginative and prescient transformer encoder, however with the next extra processing:
- Masked token vector of lacking patch
- Encoder output vector for a given patch
For pictures [ [ A, B, X], [C, X, X], [X, D, E]]the place X represents a lacking patch and the decoder obtains a sequence of patch vectors. [Enc(A), Enc(B), Vec(X), Vec(X), Vec(X), Enc(D), Enc(E)]Enc returns the encoder output vector given a patch vector, the place X is a vector representing lacking tokens.
of Final layer The decoder has a linear layer that maps the context embeddings (produced by the decoder’s imaginative and prescient transformer encoder) to vectors with size equal to the patch measurement. The loss perform is the imply squared error, which is the squared distinction between the unique patch vector and the vector predicted by this layer. The loss perform solely considers the decoder predictions from the masked tokens and ignores the predictions similar to the present token (i.e. Dec(A), Dec(B), Dec(C), and so on.).
Remaining feedback and examples
It could be stunning that the authors recommend masking round 75% of the patches in a picture; BERT solely masks round 15% of the phrases. The authors justify this as follows:
Photographs are pure alerts with a excessive diploma of spatial redundancy: for instance, lacking patches may be restored from neighboring patches with no high-level understanding of the half, object, or scene. To beat this distinction and encourage the training of helpful options, we masks out many of the random patches.
Need to attempt it for your self? Test it out right here Demo Notebook Written by Niels Rogge.
That is all for this speak. We have now been on a journey to grasp how the fundamental Transformer mannequin generalizes to the world of Pc Imaginative and prescient. I hope this speak was clear, insightful, and value your time.
References:
[1] Dosovitsky, A. and so on (2021) An image is price 16×16 phrases: Transformers for giant scale picture recognition, arXiv.orgout there: https://arxiv.org/abs/2010.11929 (Accessed: June 28, 2024).
[2] He, Okay. and so on (2021) Masks Autoencoders are Scalable Visible Learners, arXiv.orgout there: https://arxiv.org/abs/2111.06377 (Accessed: June 28, 2024).

{kind=link}