


On this article, you’ll find out how instrument design — not mannequin functionality — is the basis explanation for most AI agent failures, and what concrete design patterns you’ll be able to apply to repair it.
Matters we are going to cowl embody:
- Instrument design practices that enhance agent reliability, together with single-responsibility instruments, tight schemas, and structured error returns.
- Frequent failure modes reminiscent of unfiltered API publicity, silent partial success, and overlapping instrument names that break real-world workloads.
- Schema and error dealing with patterns that scale back hallucination and unreliable habits on the instrument boundary.
Let’s get into it.
AI Agent Instrument Design: What Works and What Doesn’t
Introduction
Most AI agent failures appear like mannequin errors: selecting the flawed instrument, passing unhealthy arguments, or mishandling errors. However in follow, the mannequin is often working with the interface it was given. The underlying problem is usually the instrument design itself.
A mannequin can solely purpose from the knowledge uncovered by means of the instrument interface: the instrument title, its description, the parameter schema, and the parameter descriptions. These particulars form how the mannequin interprets intent, plans actions, and executes duties. When the instrument design is unclear, incomplete, or loosely structured, failures grow to be predictable somewhat than unintentional.
Issues like obscure naming, ambiguous directions, inconsistent schemas, weak parameter definitions, and poor error dealing with all improve the chance of failures. Stronger fashions can scale back some errors, however they can’t reliably compensate for a flawed interface. This text covers:
- Instrument design practices that enhance reliability
- Failure modes that look wonderful in demos however break beneath actual workloads
- Schema and error design that reduces hallucination on the instrument boundary
Every sample is paired with its failure counterpart, as a result of understanding why a design fails is as essential as understanding what to interchange it with.
What Works in AI Agent Instrument Design
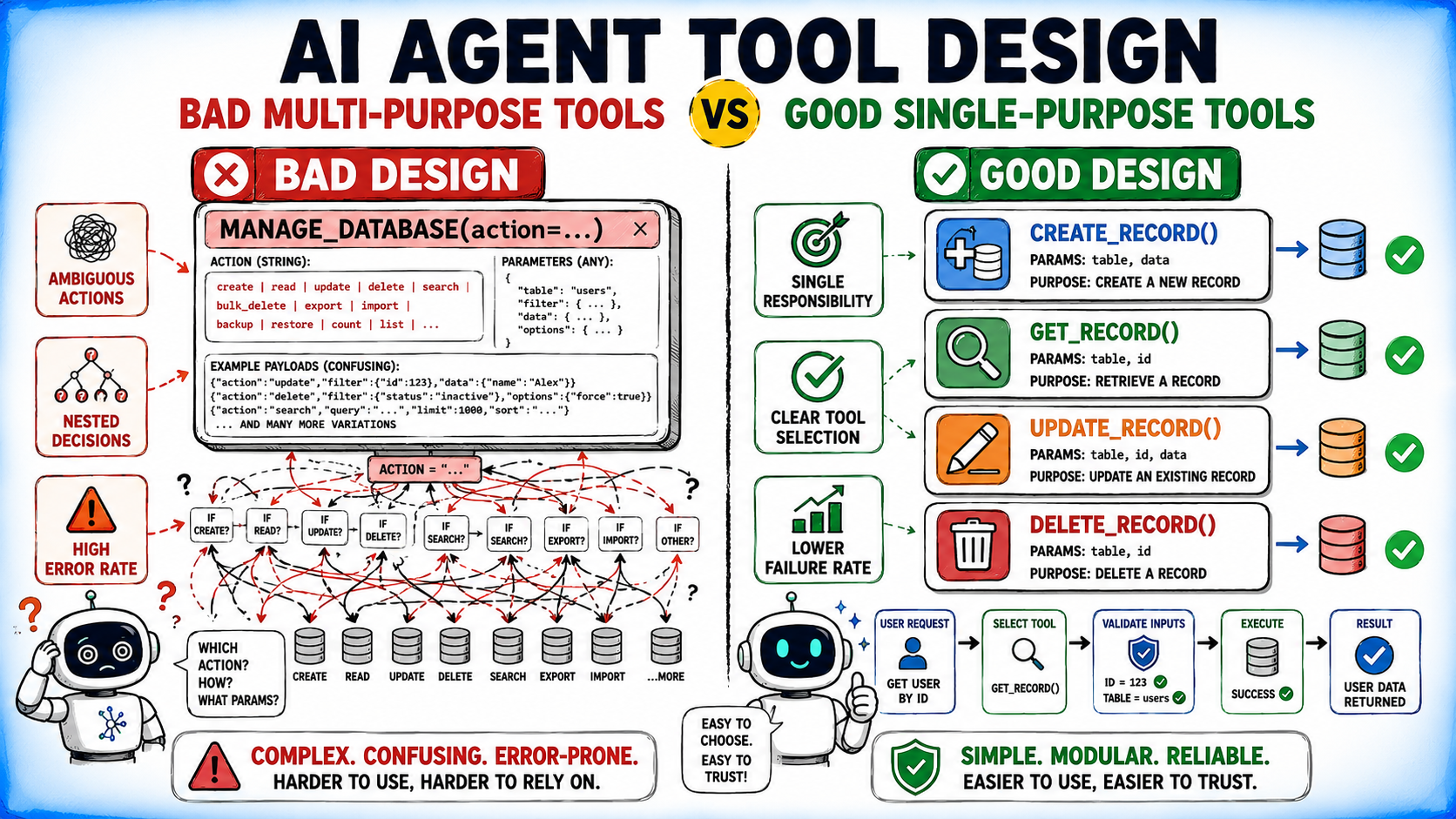
1. One Instrument, One Accountability
In most agent methods, a instrument ought to characterize a single, clear operation. When one instrument handles a number of behaviors by means of an motion parameter, the mannequin should first determine which mode to invoke earlier than it could possibly resolve the precise activity.
The distinction turns into clearer when evaluating a multi-action instrument towards devoted single-purpose instruments:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Keep away from: action-based multi-behavior instrument @instrument def manage_customer( motion: str, customer_id: str | None = None, information: dict | None = None ): “”“ motion: create | get | replace | delete | droop ““” ...
# Favor: single-responsibility instruments @instrument def create_customer(information: CustomerInput) -> Buyer: “”“Create a brand new buyer file.”“” ...
@instrument def get_customer(customer_id: str) -> Buyer: “”“Retrieve a buyer by ID.”“” ...
@instrument def suspend_customer(customer_id: str, purpose: str) -> SuspensionResult: “”“Droop a buyer account.”“” ... |
One Instrument, One Accountability
Single-responsibility instruments give the mannequin an unambiguous perform and offer you cleaner error dealing with and simpler observability.
⚠️ Observe: It is a helpful default somewhat than a common rule. Some domains — reminiscent of shell, filesystem, browser, or calendar instruments — might profit from a constrained multi-action interface as a result of the motion area itself is a part of the underlying abstraction.
2. Schemas That Make Invalid States Not possible
In tool-calling brokers, the mannequin constructs instrument name arguments by reasoning out of your schema.
- A free schema means the mannequin guesses at constraints.
- A decent schema encodes these constraints so no guessing is required.
Right here’s an instance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from pydantic import BaseModel, Subject from enum import Enum
class Precedence(str, Enum): LOW = “low” MEDIUM = “medium” HIGH = “excessive”
class CreateTaskInput(BaseModel): title: str = Subject( description=“Quick, actionable activity title. Use crucial type: ‘Evaluate PR’, not ‘PR Evaluate’.”, min_length=5, max_length=100 ) precedence: Precedence = Subject( description=“Activity precedence. Use HIGH just for blockers affecting different work.”, default=Precedence.MEDIUM ) due_date: str = Subject( description=“Due date in ISO 8601 format: YYYY-MM-DD. Have to be a future date.”, sample=r“^d{4}-d{2}-d{2}$” ) |
Enums are notably helpful for fields with a small set of legitimate values as a result of they get rid of a category of plausible-but-invalid outputs. Validation failures floor on the instrument boundary somewhat than as cryptic downstream errors.
3. Descriptions That Outline Scope, Not Simply Objective
Tool descriptions are model-facing documentation. They should do two issues: clarify when to make use of the instrument, and clarify when to not. Most descriptions solely do the primary.
|
# Weak: explains what it does, not when to not use it “”“Seek for paperwork within the information base.”“”
# Sturdy: defines objective, scope, and limits “”“ Search the inner information base for paperwork, insurance policies, and reference materials. Use this when the consumer asks about firm procedures, product specs, or documented workflows. Do NOT use this for real-time information (costs, availability, present standing) — use get_live_data() as a substitute. Returns as much as 5 outcomes ranked by relevance. If no outcomes are returned, the knowledge isn’t within the information base. ““” |
With out the disambiguation, the mannequin infers scope from the instrument title alone, which is usually a dependable supply of choice errors at scale. instrument definition contains clear boundaries from different instruments, not simply utilization directions.
4. Structured, Actionable Error Returns
When a instrument fails, the mannequin reads the error and decides what to do subsequent. An unhandled exception or stack hint produces noise-driven follow-up habits. A structured error offers the mannequin one thing to department on.
Structured errors mustn’t solely report what failed but additionally assist the agent determine what to do subsequent. error format makes retry habits specific and provides the mannequin a transparent restoration path:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class ToolError(BaseModel): error_code: str # machine-readable, for the mannequin to department on message: str # human-readable description recoverable: bool # can the agent retry? suggested_action: str # what the agent ought to do subsequent
# File not discovered: retryable return ToolError( error_code=“RECORD_NOT_FOUND”, message=“No consumer file discovered with ID ‘usr_123’.”, recoverable=True, suggested_action=“Use list_users() to get legitimate consumer IDs earlier than calling get_user().” )
# Quota exceeded: not retryable return ToolError( error_code=“QUOTA_EXCEEDED”, message=“API quota for this instrument has been reached for at this time.”, recoverable=False, suggested_action=“Notify the consumer and cease. Don’t retry this instrument at this time.” ) |
The recoverable flag and suggested_action area are what change agent habits. With out them, fashions retry non-retryable errors or abandon recoverable ones.
5. Idempotent State-Altering Operations
Each instrument that mutates state — creates a file, sends a message, transfers funds — should be protected to name twice. In follow, brokers retry, networks fail, and the LLM loop might problem a second name as a result of affirmation of the primary by no means arrived.
A easy solution to stop duplicate negative effects is to require an idempotency key for each write operation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@instrument def send_email( to: str, topic: str, physique: str, idempotency_key: str = Subject( description=“Distinctive key for this ship operation. Use a hash of recipient + topic + timestamp. “ “Similar key on retry returns the unique end result with out re-sending.” ) ) -> dict: “”“Ship an electronic mail. Idempotent: the identical idempotency_key won’t set off a second ship.”“” present = idempotency_store.get(idempotency_key) if present: return present end result = email_service.ship(to=to, topic=topic, physique=physique) idempotency_store.set(idempotency_key, end result, ttl=86400) return end result |
With out idempotency ensures, transient failures can simply flip into duplicate actions.
What Doesn’t Work in AI Agent Instrument Design
1. Skinny Wrappers Round Unfiltered APIs
Pointing an agent at a REST API and surfacing it as a instrument is the most typical shortcut and the most typical supply of manufacturing failures. APIs built for developers often expose far more detail than agents actually need. Responses come full of tons of of fields, even when solely a handful are related. They depend on pagination, use opaque inside IDs with little contextual that means, and return error codes that require deep area information to interpret.
A purpose-built wrapper handles pagination internally, tasks solely the fields the agent wants, and maps API errors to the structured ToolError format mentioned above. The agent by no means constructs API paths or manages pages; it receives typed objects it could possibly purpose about.
That stated, over-wrapping may also be dangerous. If each endpoint turns into a separate, narrowly outlined instrument with no shared construction, the instrument floor can grow to be fragmented and tougher for the mannequin to navigate. The purpose isn’t maximal abstraction, however a constant, agent-friendly abstraction layer.
2. Loading All Instruments Into Each Context
Accuracy degrades because the instrument catalog grows. LongFuncEval, a 2025 examine on tool-calling efficiency throughout lengthy contexts, discovered performance drops substantially as the tool catalog size increased — even in fashions with 128K context home windows. Loading each instrument into each system immediate compounds this by consuming token funds earlier than any activity content material is processed.
Dynamic tool loading addresses each issues. Decide which instruments are related to the present step and embody solely these:
|
STEP_TOOL_MAP = { “analysis”: [“search_documents”, “search_web”, “get_url_content”], “write”: [“create_document”, “update_document”, “format_text”], “ship”: [“send_email”, “post_to_slack”, “create_calendar_event”], }
def get_tools_for_step(step_type: str, available_tools: checklist) -> checklist: relevant_names = STEP_TOOL_MAP.get(step_type, []) return [t for t in available_tools if t.name in relevant_names] |
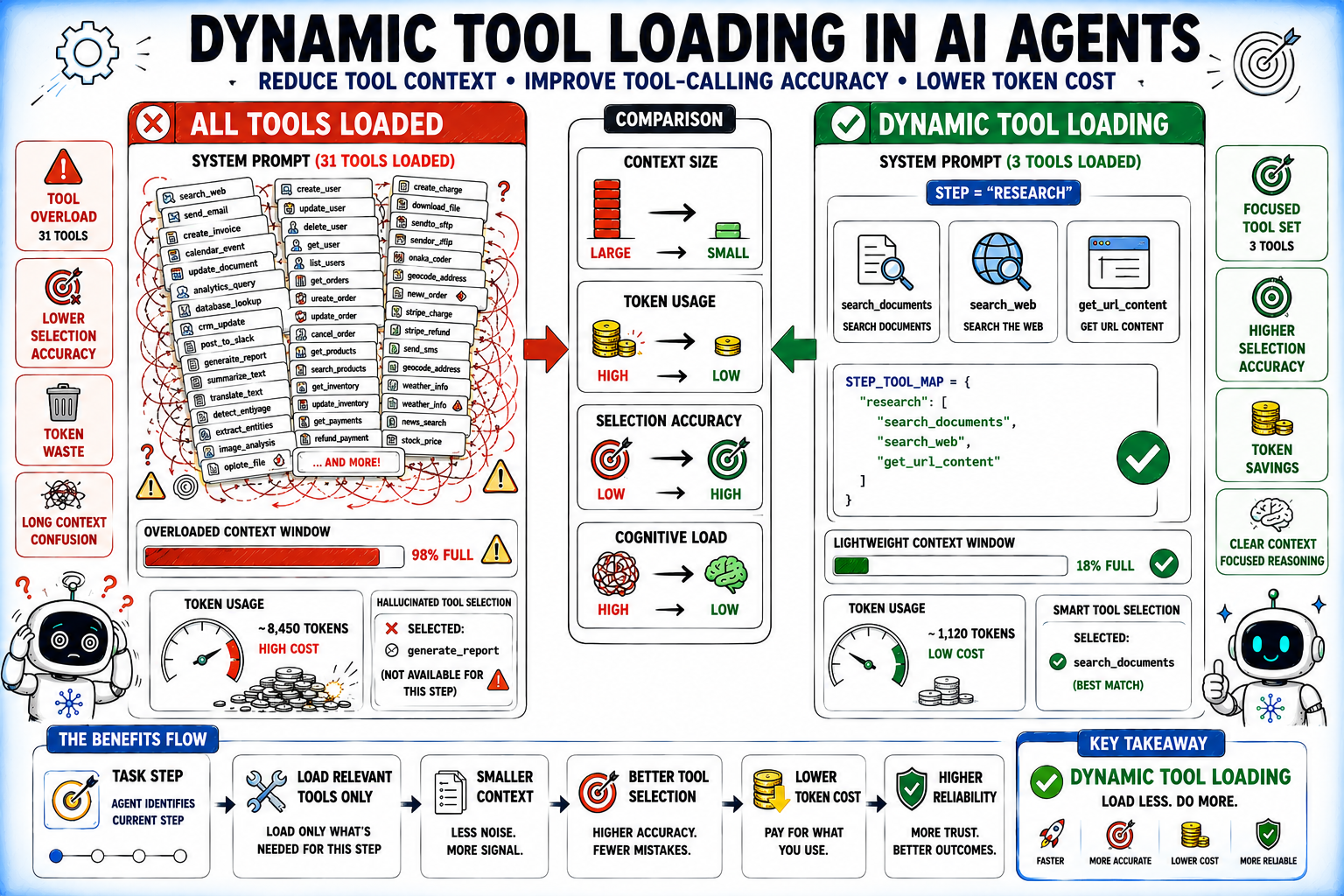
Dynamic Instrument Loading
Exposing solely a small, related subset of instruments at every step — somewhat than the total toolset — typically improves choice accuracy and reduces per-call token value.
3. Silent Partial Success
Partial success turns into an issue when a instrument completes solely a part of the requested work however returns a response that appears totally profitable. The agent continues execution with an incomplete or deceptive view of the system state.
This often occurs when instruments suppress inside failures and return solely the profitable portion of the end result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# This model silently misleads the agent @instrument def bulk_create_tasks(duties: checklist) -> dict: created = [] for activity in duties: attempt: end result = task_api.create(activity) created.append(end result.id) besides Exception: move # silent failure: that is the bug return {“created”: created}
# This model makes partial success specific @instrument def bulk_create_tasks(duties: checklist) -> BulkCreateResult: created, failed = [], [] for activity in duties: attempt: created.append(task_api.create(activity).id) besides TaskCreationError as e: failed.append({“enter”: activity.title, “purpose”: str(e)}) return BulkCreateResult( created_ids=created, failed_items=failed, success=len(failed) == 0, partial_success=len(created) > 0 and len(failed) > 0 ) |
The partial_success flag offers the mannequin one thing to department on: retry the failed gadgets, floor the partial end result to the consumer, or halt the workflow.
4. Overlapping Instrument Names and Descriptions
When two instruments do related issues, the mannequin causes about which to make use of on each name. That reasoning prices tokens and introduces errors. Some widespread examples embody:
search_documentsandfind_documentswith equivalent objectiveget_userandfetch_user_profilewith unclear variationscreate_task,add_task, andnew_taskas three instruments for one operation
In such instances, renaming alone isn’t the repair. Each instrument wants a objective that may be described irrespective of different instruments within the set. If an outline requires “in contrast to X, this one…” to make sense, that’s a design downside. Instrument sprawl — too many instruments with overlapping scope — is a supply of unreliable agent habits in enterprise deployments.
5. Damaging Actions With no Affirmation Gate
Any instrument that takes an irreversible motion — deleting information, messaging actual customers, executing monetary transactions — wants a structural two-step affirmation, not an in-prompt “are you certain?” A staged method introduces an specific affirmation boundary that reduces the chance of unintentional or unauthorized execution.
The most secure sample is to separate staging from execution and require a short-lived affirmation token between the 2 steps:
|
@instrument def stage_deletion(record_ids: checklist[str], purpose: str) -> StagedDeletion: “”“Stage information for deletion. Does NOT delete something. Returns a affirmation token that expires in 60 seconds. Name confirm_deletion() with this token to proceed.”“” token = generate_deletion_token(record_ids) staged_deletions[token] = {“ids”: record_ids, “expires”: now() + 60} return StagedDeletion(token=token, records_to_delete=len(record_ids), expires_in_seconds=60)
@instrument def confirm_deletion(token: str) -> DeletionResult: “”“Execute a staged deletion. IRREVERSIBLE. Affirm solely after specific consumer approval.”“” staged = staged_deletions.get(token) if not staged or staged[“expires”] < now(): increase ValueError(“Token invalid or expired. Stage the deletion once more.”) # proceed |
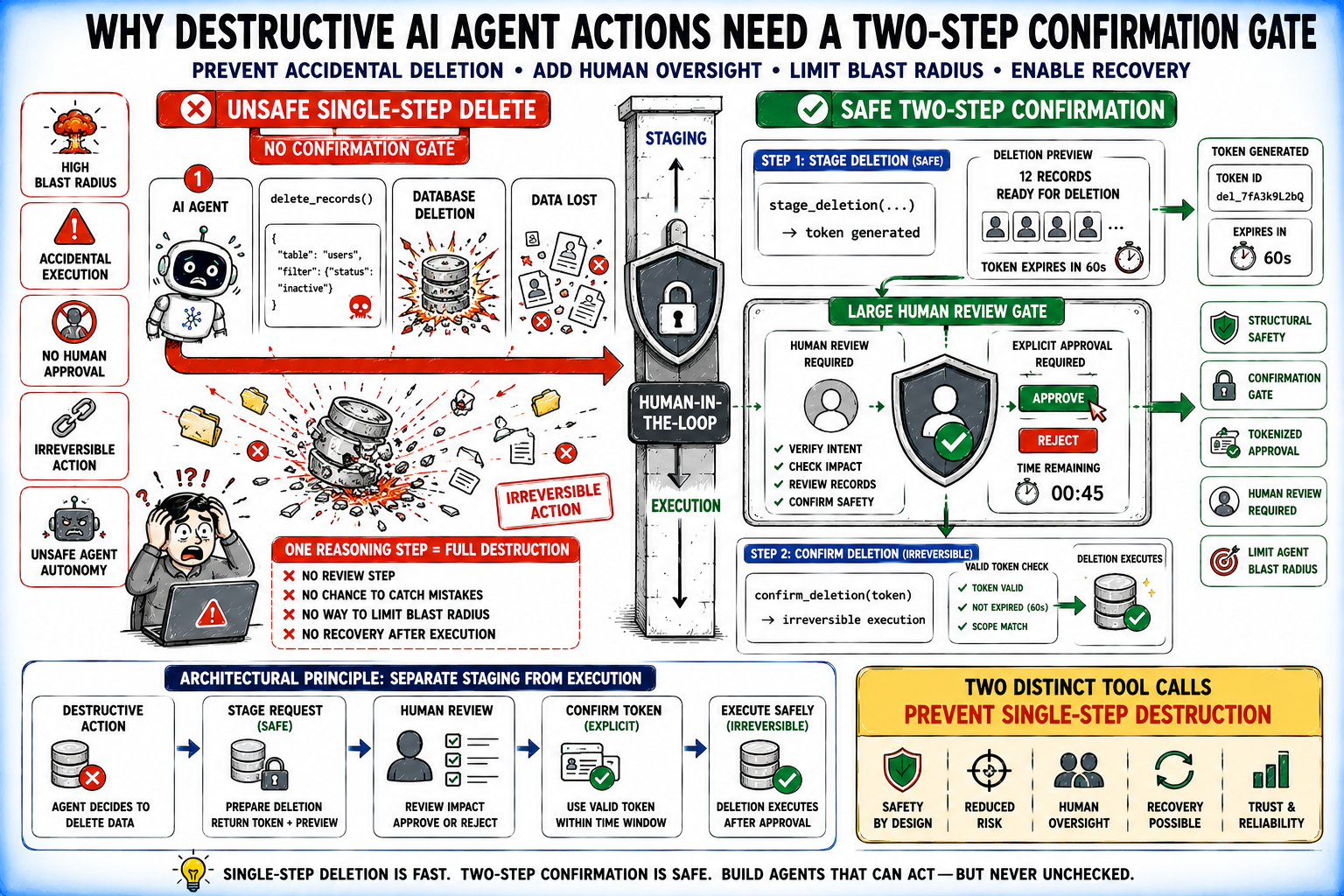
Damaging Actions With no Affirmation Gate
Two distinct instrument calls imply the mannequin can’t full a harmful operation in a single reasoning step, which is the purpose.
⚠️ Observe: Two-step security flows, nonetheless, are sometimes not adequate on their very own in lots of methods. Even when staging and affirmation are used, extra safeguards — reminiscent of short-lived, single-use tokens, strict session binding, and replay safety — are mandatory to forestall token reuse, leakage, or cross-session execution that may bypass the meant security boundary.
AI Agent Instrument Design Choices at a Look
Each row represents a key choice in AI agent instrument design:
| Design Space | Works | Doesn’t Work |
|---|---|---|
| Instrument Scope | Single duty per instrument | Motion-parameter instruments like manage_database(motion="create") |
| Schema | Tight: enums, validators, typed fields | Free: free strings, untyped dicts |
| Descriptions | Embrace scope boundaries and when to not use | Blissful path solely |
| Write Operations | Idempotent with idempotency keys | Hearth-and-forget, no retry security |
| Error Returns | Structured: error_code, recoverable, suggested_action |
Unhandled exceptions or untyped strings |
| Instrument Rely | Dynamic loading per step | All instruments in each context |
| API Wrapping | Objective-built wrapper with agent-facing schema | Unfiltered API publicity |
| Partial Success | Specific partial_success area in return |
Silent exception swallowing |
| Damaging Actions | Two-step staging + affirmation | Single-call delete/ship/execute |
| Instrument Overlap | Semantically distinct, audited earlier than deploy | Comparable names and descriptions competing |
Writing effective tools for AI agents — using AI agents from Anthropic is a helpful reference on instrument design.

{kind=link}