


Video modifying has all the time had a unclean secret. It is simple to take away objects from footage. It is very troublesome to make a scene appear to be it by no means occurred. If you happen to take somebody out with a guitar, you may be left with an instrument that defies gravity and floats. VFX groups in Hollywood spend weeks fixing precisely these sorts of issues. Netflix and INSAIT, a crew of researchers from Sofia College St. Paul’s Kliment Ofritsky’ launched empty house (Deleting video objects and interactions) mannequin that may do it robotically.
VOID removes objects and all interactions they trigger on a scene out of your video, together with secondary results resembling shadows and reflections, in addition to bodily interactions resembling objects falling when an individual is eliminated.
What downside does VOID really remedy?
Normal video inpainting fashions (the type utilized in most modifying workflows at the moment) are educated to fill in pixel areas the place objects have been. They’re primarily very refined background painters. It is smart that they do not do it causal relationship: If I delete an actor that has props, what occurs to these props?
Present video object deletion strategies are good at repairing the content material “behind” the item and fixing appearance-level artifacts resembling shadows and reflections. Nonetheless, if the eliminated objects have extra vital interactions, resembling collisions with different objects, the present mannequin can not repair them, producing implausible outcomes.
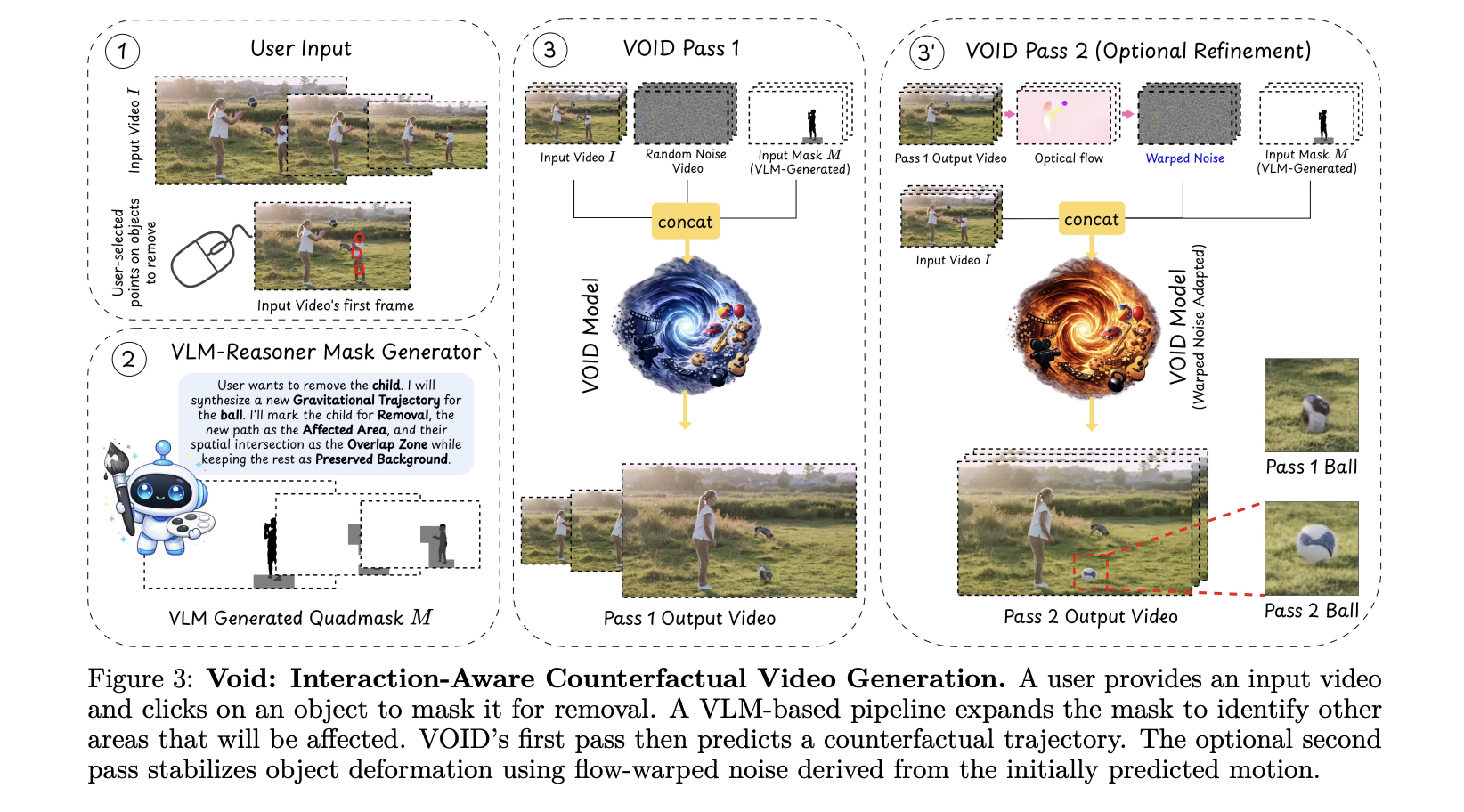
VOID is constructed on CogVideoX and fine-tuned for video inpainting with interaction-aware masks conditioning. The important thing innovation lies in how the mannequin understands the scene, not simply “which pixels ought to I fill?” However, “What may bodily occur to this object after it disappears?”
Normal instance for analysis papers: When the particular person holding the guitar leaves, the VOID additionally removes its affect on the particular person’s guitar, inflicting it to fall by itself. It isn’t straightforward. The mannequin ought to perceive that the guitar was being performed. supported And eradicating individuals means gravity takes over.
Additionally, in contrast to earlier works, VOID was evaluated immediately in opposition to actual opponents. We experimented with each artificial and actual information and located that our method higher preserves constant scene dynamics after object elimination in comparison with earlier video object elimination strategies resembling ProPainter, DiffuEraser, Runway, MiniMax-Remover, ROSE, and Gen-Omnimatte.
Structure: CogVideoX internals
VOID is constructed on CogVideoX-Fun-V1.5-5b-InP — A mannequin of Alibaba PAI — fine-tuned for interaction-aware video restore quad masks conditioning. CogVideoX is a 3D Transformer-based video technology mannequin. Consider it like a video model of steady diffusion. Secure diffusion is a diffusion mannequin that operates on a temporal sequence of frames slightly than a single picture. Sure base fashions (CogVideoX-Enjoyable-V1.5-5b-InP) is a checkpoint launched by Alibaba PAI on Hugging Face that engineers must obtain individually earlier than working VOID.
Wonderful-tuned structure spec: CogVideoX 3D transformer with 5B parameters, takes textual content prompts describing video, quadmask, and deleted scene as enter, operates at default decision of 384 × 672, processes as much as 197 frames, makes use of DDIM scheduler, and runs in BF16 with FP8 quantization for reminiscence effectivity.
of quad masks That is in all probability essentially the most attention-grabbing technical contribution right here. Fairly than being a binary masks (delete this pixel / hold this pixel), a quadmask is a four-valued masks that encodes the principle object to take away, overlapping areas, affected areas (falling objects, moved objects), and the background to maintain.
In actuality, every pixel within the masks will get considered one of 4 values: 0 (major object will probably be deleted), 63 (overlap between major and affected areas), 127 (the world affected by the interplay – what strikes or modifications on account of the deletion), and 255 (Background, as is). This provides the mannequin a structured semantic map. what is going on on the bottomnot simply the place is the item.
2-pass inference pipeline
VOID makes use of two transformer checkpoints which might be educated in sequence. You may carry out inference on move 1 alone, or you’ll be able to concatenate each passes for higher temporal consistency.
Path 1 (void_pass1.safetensors) is the fundamental restore mannequin and is adequate for many movies. Cross 2 serves the precise goal of correcting a identified failure mode. If the mannequin detects object morphing, a identified failure mode for small-scale video diffusion fashions, an elective second move reruns the inference utilizing the flowwarp noise from the primary move to stabilize the item’s form alongside the newly synthesized trajectory.
It is value understanding this distinction. Cross 2 is not only for lengthy clips, particularly Form stability correction. If the diffusion mannequin produces objects that regularly warp or deform between frames (a well-documented artifact in video diffusion), move 2 makes use of optical move to warp the potentials from move 1 and feed them as initialization to the second diffusion run, fixing the form of the synthesized object from body to border.
Methods to generate coaching information
Now that is the place issues get actually attention-grabbing. Paired movies are required to coach a mannequin to know bodily interactions. That’s, the identical scene with and with out objects, the physics working appropriately in each. Paired information at this scale doesn’t exist in the actual world. So the crew constructed it holistically.
For coaching, we used paired counterfactual movies generated from two sources. HUMOTO (human-object interplay rendered in Blender utilizing physics simulation) and Kubric (object-only interplay utilizing Google scan objects).
HUMOTO makes use of movement seize information of human-object interactions. The first mechanism is Blender resimulation. The scene is about up with people and objects, rendered as soon as with people current, then people are faraway from the simulation and physics is re-run from that time on. The result’s a bodily true counterfactual. Objects that have been held or supported now fall as anticipated. Kubric, developed by Google Analysis, applies the identical thought to collisions between objects. Collectively, they produce a dataset of paired movies that aren’t approximated by human annotators and whose physics is confirmed to be right.
Necessary factors
- VOID is greater than a pixel fill. Not like present video restore instruments that solely repair visible artifacts resembling shadows and reflections, VOID understands bodily cause-and-effect relationships. If you happen to take away the particular person holding the item, the item will match naturally into the output video.
- Quad Masks is the core innovation. As a substitute of a easy binary delete/retain masks, VOID makes use of a 4-valued quad masks (values 0, 63, 127, 255). This encodes not solely what to take away, but in addition which surrounding areas of the scene. be bodily affected — Supplies structured scene understanding for diffusion fashions.
- Two-pass inference resolves precise failure modes. Cross 1 handles many of the video. Cross 2 exists particularly to right object morphing artifacts, a identified weak spot of video diffusion fashions, through the use of the optical move warp latent of move 1 as an initialization for the second diffusion run.
- Coaching is now doable with artificial paired information. Video information for real-world counterfactual pairs doesn’t exist at scale, so the researchers used Blender’s Physics Resimulation (HUMOTO) and Google’s Kubric framework to construct the info and generate before-and-after floor reality for video pairs that proves the physics to be right.
Please verify paper, model weight and lipo. Please be happy to comply with us too Twitter Remember to affix us 120,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.

Michal Sutter is a knowledge science knowledgeable with a grasp’s diploma in information science from the College of Padova. With a robust basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.

{kind=link}