


On this article, you’ll study why manufacturing AI purposes want each a vector database for semantic retrieval and a relational database for structured, transactional workloads.
Matters we are going to cowl embrace:
- What vector databases do properly, and the place they fall quick in manufacturing AI methods.
- Why relational databases stay important for permissions, metadata, billing, and utility state.
- How hybrid architectures, together with the usage of
pgvector, mix each approaches right into a sensible information layer.
Maintain studying for all the main points.
Past the Vector Retailer: Constructing the Full Information Layer for AI Functions
Picture by Creator
Introduction
For those who take a look at the structure diagram of virtually any AI startup right this moment, you will notice a big language mannequin (LLM) linked to a vector retailer. Vector databases have turn out to be so carefully related to fashionable AI that it’s straightforward to deal with them as your entire information layer, the one database you want to energy a generative AI product.
However as soon as you progress past a proof-of-concept chatbot and begin constructing one thing that handles actual customers, actual permissions, and actual cash, a vector database alone isn’t sufficient. Manufacturing AI purposes want two complementary information engines working in lockstep: a vector database for semantic retrieval, and a relational database for the whole lot else.
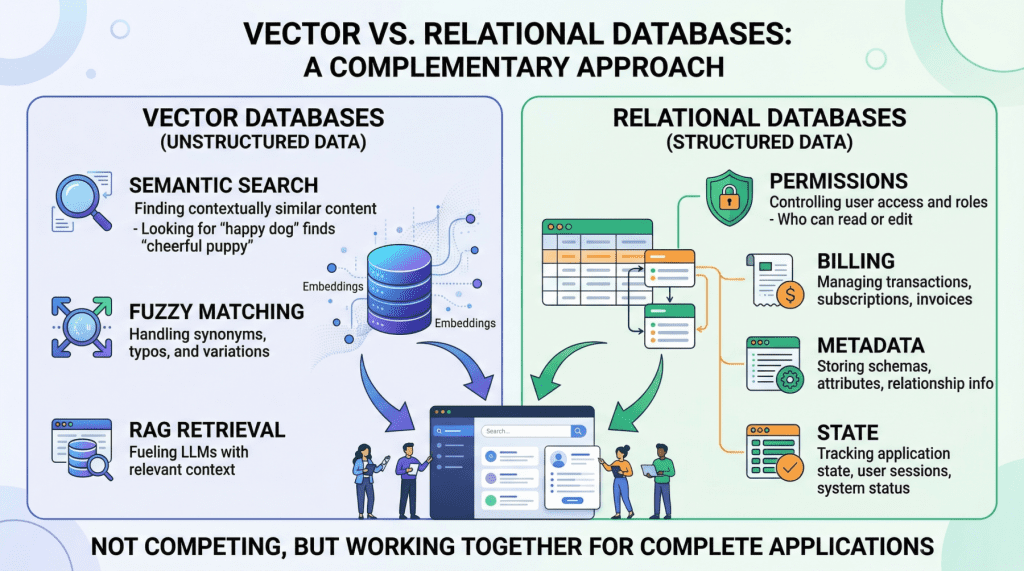
This isn’t a controversial declare when you look at what every system really does — although it’s typically neglected. Vector databases like Pinecone, Milvus, or Weaviate excel at discovering information based mostly on which means and intent, utilizing high-dimensional embeddings to carry out fast semantic search. Relational databases like PostgreSQL or MySQL handle structured information with SQL, offering deterministic queries, complicated filtering, and strict ACID ensures that vector shops lack by design. They serve solely totally different features, and a sturdy AI utility relies on each.
On this article, we are going to discover the particular strengths and limitations of every database kind within the context of AI purposes, then stroll by sensible hybrid architectures that mix them right into a unified, production-grade information layer.
Vector Databases: What They Do Properly and The place They Break Down
Vector databases energy the retrieval step in retrieval augmented technology (RAG), the sample that permits you to feed particular, proprietary context to a language mannequin to cut back hallucinations. When a consumer queries your AI agent, the applying embeds that question right into a high-dimensional vector and searches for essentially the most semantically comparable content material in your corpus.
The important thing benefit right here is meaning-based retrieval. Contemplate a authorized AI agent the place a consumer asks about “tenant rights concerning mould and unsafe dwelling circumstances.” A vector search will floor related passages from digitized lease agreements even when these paperwork by no means use the phrase “unsafe dwelling circumstances”; maybe they reference “habitability requirements” or “landlord upkeep obligations” as an alternative. This works as a result of embeddings seize conceptual similarity relatively than simply string matches. Vector databases deal with typos, paraphrasing, and implicit context gracefully, which makes them excellent for looking out the messy, unstructured information of the true world.
Nonetheless, the identical probabilistic mechanism that makes semantic search versatile additionally makes it imprecise, creating critical issues for operational workloads.
Vector databases can’t assure correctness for structured lookups. If you want to retrieve all help tickets created by consumer ID user_4242 between January 1st and January thirty first, a vector similarity search is the unsuitable device. It is going to return outcomes which might be semantically much like your question, but it surely can’t assure that each matching document is included or that each returned document really meets your standards. A SQL WHERE clause can.
Aggregation is impractical. Counting energetic consumer periods, summing API token utilization for billing, computing common response occasions by buyer tier — these operations are trivial in SQL and both unattainable or wildly inefficient with vector embeddings alone.
State administration doesn’t match the mannequin. Conditionally updating a consumer profile area, toggling a characteristic flag, recording {that a} dialog has been archived — these are transactional writes towards structured information. Vector databases are optimized for insert-and-search workloads, not for the read-modify-write cycles that utility state calls for.
In case your AI utility does something past answering questions on a static doc corpus (i.e. if it has customers, billing, permissions, or any idea of utility state), you want a relational database to deal with these tasks.
Relational Databases: The Operational Spine
The relational database manages each “arduous reality” in your AI system. In follow, this implies it’s answerable for a number of vital domains.
Person id and entry management. Authentication, role-based entry management (RBAC) permissions, and multi-tenant boundaries have to be enforced with absolute precision. In case your AI agent decides which inside paperwork a consumer can learn and summarize, these permissions should be retrieved with 100% accuracy. You can’t depend on approximate nearest neighbor search to find out whether or not a junior analyst is permitted to view a confidential monetary report. This can be a binary yes-or-no query, and the relational database solutions it definitively.
Metadata on your embeddings. This can be a level that’s ceaselessly neglected. In case your vector database shops the semantic illustration of a chunked PDF doc, you continue to must retailer the doc’s authentic URL, the writer ID, the add timestamp, the file hash, and the departmental entry restrictions that govern who can retrieve it. That “one thing” is nearly all the time a relational desk. The metadata layer connects your semantic index to the true world.
Pre-filtering context to cut back hallucinations. Some of the mechanically efficient methods to forestall an LLM from hallucinating is to make sure it solely causes over exactly scoped, factual context. If an AI undertaking administration agent must generate a abstract of “all high-priority tickets resolved within the final 7 days for the frontend group,” the system should first use actual SQL filtering to isolate these particular tickets earlier than feeding their unstructured textual content content material into the mannequin. The relational question strips out irrelevant information so the LLM by no means sees it. That is cheaper, quicker, and extra dependable than counting on vector search alone to return a wonderfully scoped outcome set.
Billing, audit logs, and compliance. Any enterprise deployment requires a transactionally constant document of what occurred, when, and who licensed it. These usually are not semantic questions; they’re structured information issues, and relational databases resolve them with many years of battle-tested reliability.
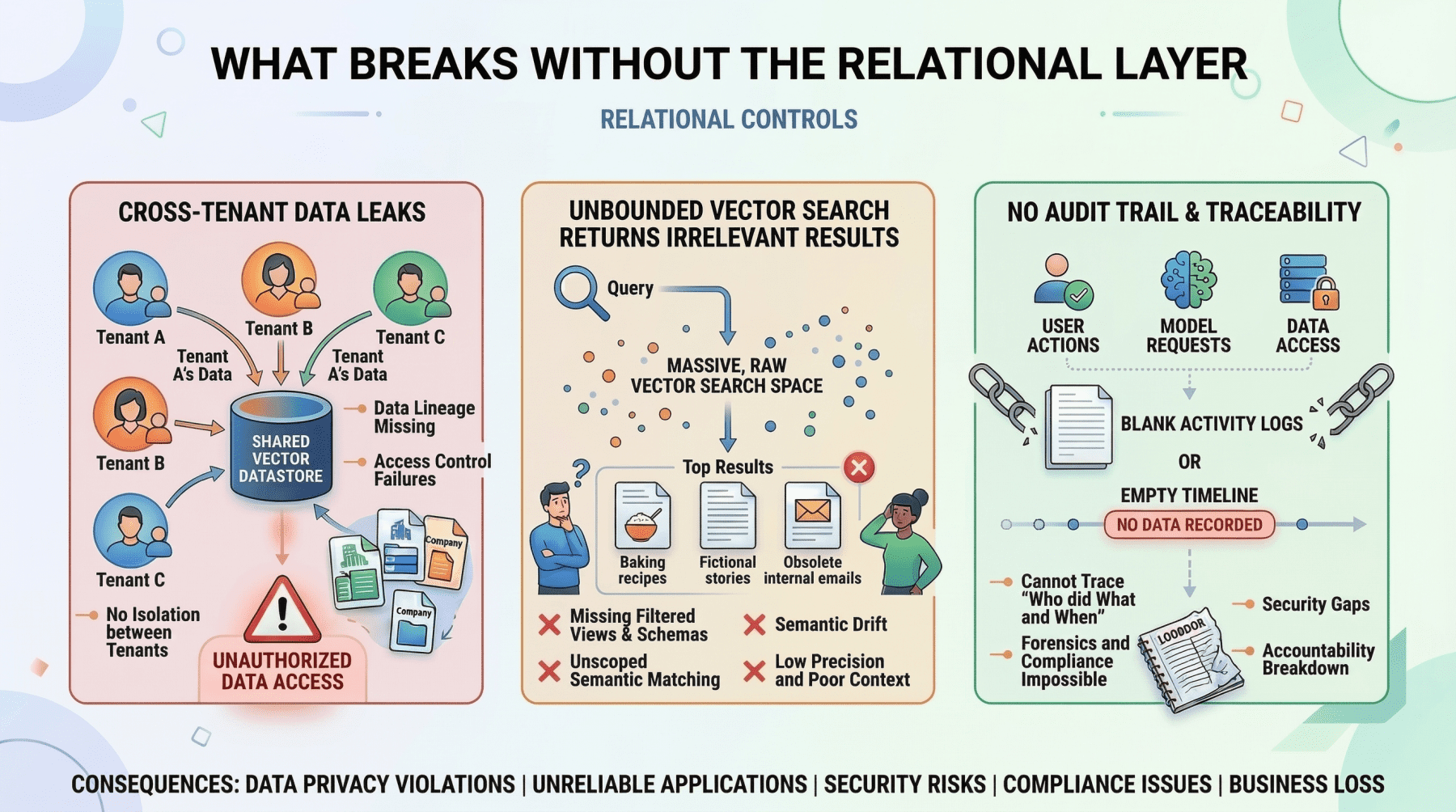
What Breaks With out The Relational Layer
Picture by Creator
The limitation of relational databases within the AI period is simple: they haven’t any native understanding of semantic which means. Looking for conceptually comparable passages throughout tens of millions of rows of uncooked textual content utilizing SQL is computationally costly and produces poor outcomes. That is exactly the hole that vector databases fill.
The Hybrid Structure: Placing It Collectively
The simplest AI purposes deal with these two database varieties as complementary layers inside a single system. The vector database handles semantic retrieval. The relational database handles the whole lot else. And critically, they speak to one another.
The Pre-Filter Sample
The most typical hybrid sample is to make use of SQL to scope the search house earlier than executing a vector question. Here’s a concrete instance of how this works in follow.
Think about a multi-tenant buyer help AI. A consumer at Firm A asks: “What’s our coverage on refunds for enterprise contracts?” The appliance must:
- Question the relational database to retrieve the tenant ID for Firm A, affirm the consumer’s function has permission to entry coverage paperwork, and fetch the doc IDs of all energetic coverage paperwork belonging to that tenant.
- Question the vector database with the consumer’s query, however constrained to solely search throughout the doc IDs returned by the first step.
- Go the retrieved passages to the LLM together with the consumer’s query.
With out the first step, the vector search would possibly return semantically related passages from Firm B’s coverage paperwork, or from Firm A paperwork that they don’t have permission to entry. Both case leads to a knowledge leak. The relational pre-filter isn’t elective; it’s a safety boundary.
The Publish-Retrieval Enrichment Sample
The reverse sample can be widespread. After a vector search returns semantically related chunks, the applying queries the relational database to complement these outcomes with structured metadata earlier than presenting them to the consumer or feeding them to the LLM.
For instance, an inside data base agent would possibly retrieve the three most related doc passages through vector search, then be a part of towards a relational desk to connect the writer title, the last-updated timestamp, and the doc’s confidence score. The LLM can then use this metadata to qualify its response: “Based on the Q3 safety coverage (final up to date October twelfth, authored by the compliance group)…”
Unified Storage with pgvector
For a lot of groups, working two separate database methods introduces operational complexity that’s arduous to justify, particularly at a average scale. That is the place pgvector, the vector similarity extension for PostgreSQL, turns into a compelling choice.
With pgvector, you retailer embeddings as a column instantly alongside your structured relational information. A single question can mix actual SQL filters, joins, and vector similarity search in a single atomic operation. As an illustration:
|
SELECT d.title, d.writer, d.updated_at, d.content_chunk, 1 – (d.embedding <=> query_embedding) AS similarity FROM paperwork d JOIN consumer_permissions p ON p.department_id = d.department_id WHERE p.user_id = ‘user_98765’ AND d.standing = ‘printed’ AND d.updated_at > NOW() – INTERVAL ’90 days’ ORDER BY d.embedding <=> query_embedding LIMIT 10; |
Inside one transaction, with no synchronization between separate methods, this single question:
- enforces consumer permissions
- filters by doc standing and recency
- ranks by semantic similarity
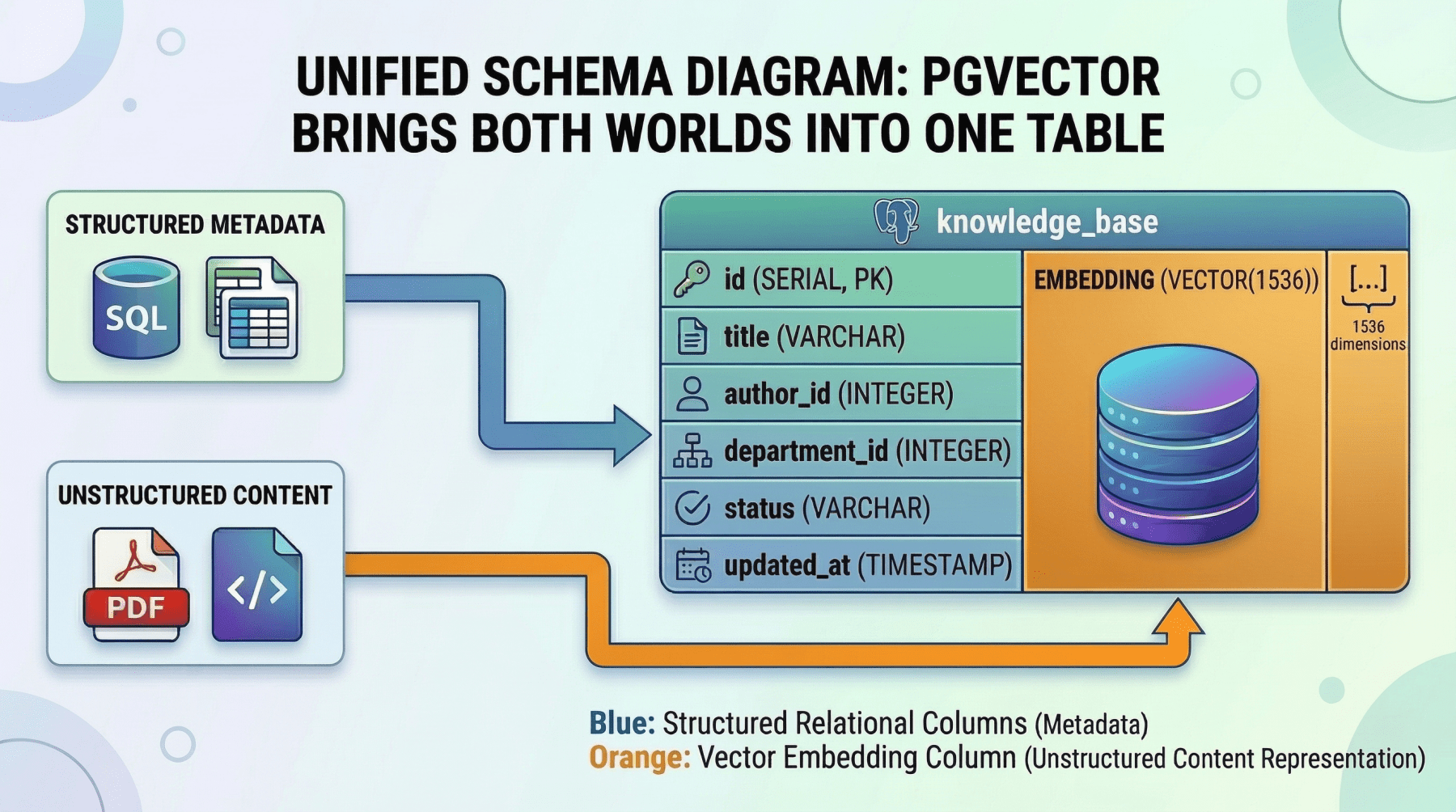
Unified Schema Diagram: Pgvector Brings Each Worlds Into One Desk
Picture by Creator
The tradeoff is efficiency at scale. Devoted vector databases like Pinecone or Milvus are purpose-built for approximate nearest neighbor (ANN) search throughout billions of vectors and can outperform pgvector at that scale. However for purposes with corpora within the lots of of hundreds to low tens of millions of vectors, pgvector eliminates a complete class of infrastructure complexity. For a lot of groups, it’s the proper start line, with the choice emigrate the vector workload to a devoted retailer later if scale calls for it.
Selecting Your Strategy
The choice framework is comparatively easy:
- In case your corpus is small to average and your group values operational simplicity, begin with PostgreSQL and
pgvector. You get a single database, a single deployment, and a single consistency mannequin. - If you’re working at an enormous scale (billions of vectors), want sub-millisecond ANN latency, or require specialised vector indexing options, use a devoted vector database alongside your relational system, linked by the pre-filter and enrichment patterns described above.
In both case, the relational layer is non-negotiable. It manages your customers, permissions, metadata, billing, and utility state. The one query is whether or not the vector layer lives inside it or beside it.
Conclusion
Vector databases are a vital part of any AI system that depends on RAG. They permit your utility to go looking by which means relatively than by key phrase, which is foundational to creating generative AI helpful in follow.
However they’re solely half of the info layer. The relational database is what makes the encompassing utility really work; it enforces permissions, manages state, offers transactional consistency, and provides the structured metadata that connects your semantic index to the true world.
If you’re constructing a manufacturing AI utility, it will be a mistake to deal with these as competing selections. Begin with a stable relational basis to handle your customers, permissions, and system state. Then combine vector storage exactly the place semantic retrieval is technically mandatory, both as a devoted exterior service or, for a lot of workloads, as a pgvector column sitting proper subsequent to the structured information it pertains to.
Probably the most resilient AI architectures usually are not those that wager the whole lot on the most recent know-how. They’re those who use every device precisely the place it’s strongest.

{kind=link}