


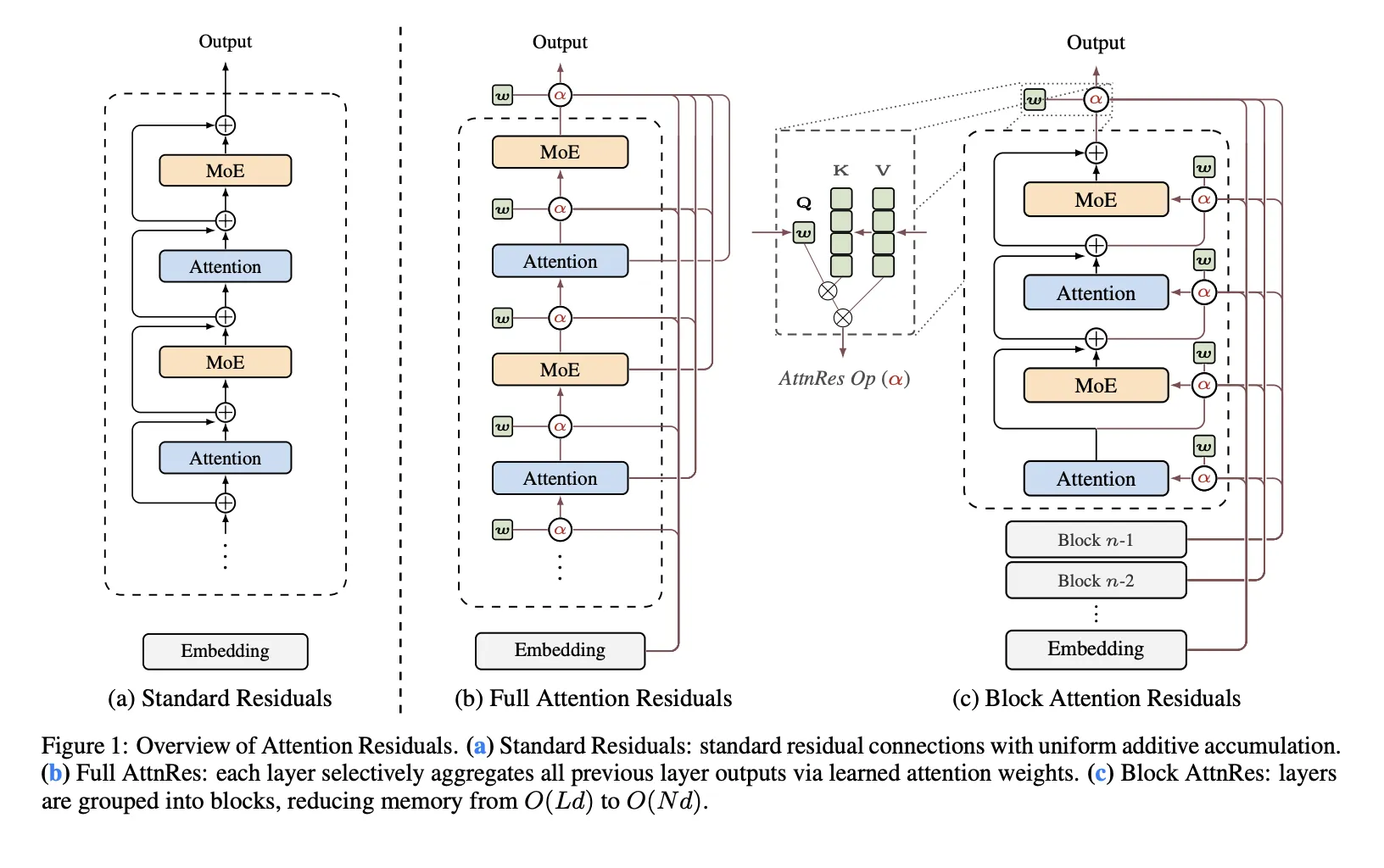
Residual connections are one of many least questioned elements of recent transformer design. Within the PreNorm structure, every layer provides its output to the working hidden state, protecting the optimization secure and permitting deep fashions to be skilled. Moonshot AI researchers argue that this normal mechanism additionally poses structural issues. That’s, the outputs of earlier layers are all collected with a set unit weight, so the magnitude of hidden states will increase with depth and the contribution of a single layer progressively weakens.
The analysis crew proposes: Consideration residual (AttnRes) As a drop-in substitute for traditional residual build-up. AttnRes makes use of softmax consideration to depth to permit every layer to combination its earlier representations, somewhat than forcing all layers to eat the identical uniformly blended residual stream. The enter to layer (l) is a weighted sum of the token embedding and the output of the earlier layer, the place the weights are computed on the earlier depth place somewhat than on the sequence place. The core concept is easy. If sequence modeling may be improved by changing fastened iterations over time, an identical concept may be utilized to the depth dimension of the community.
Why normal residuals are a bottleneck
The analysis crew recognized three issues with normal residual accumulation. first, No selective entry: All layers obtain the identical aggregated state, even when the eye layer and the feedforward layer or the MoE layer profit from a unique mixture of earlier info. Second, irreparable loss: As soon as the knowledge is mixed right into a single residual stream, later layers can’t selectively restore sure earlier representations. Thirdly, Improve in manufacturing: Deeper layers have a tendency to supply bigger outputs with the intention to preserve affect throughout the ever-growing collected state, which may make coaching unstable.
That is the primary body construction of the analysis crew. Customary residuals behave like compressed recursion throughout layers. AttnRes replaces that fastened repetition with specific consideration to the output of the earlier layer.
Full AttnRes: Consideration to all earlier layers
in full assault energy,Every layer computes consideration weights for all previous depth,sources. Within the default design, do not need Use enter conditional queries. As an alternative, every layer has a discovered layer-specific pseudo-query vector w.I ∈ Rdwhereas the keys and values are obtained from the output of the earlier layer after token embedding and RMSNorm. The RMSNorm step is necessary as a result of it prevents massive layer outputs from dominating the depth consideration weights.
Full AttnRes is simpler, but it surely will increase value. For every token, O(L2 d) Arithmetic and (O(Ld)) reminiscence for storing layer outputs. For normal coaching, this reminiscence primarily overlaps with the activations already required for backpropagation, however recalculating activations and parallelizing the pipeline introduces extra overhead as earlier outputs should stay obtainable and should should be despatched between phases.
Block AttnRes: A sensible variant for giant fashions
To allow this system for use at scale, the Moonshot AI analysis crew launched: Block AttnRes. As an alternative of processing all earlier layer outputs, the mannequin splits the layers into: N block. Inside every block, the outputs are collected right into a single block illustration, and a focus is utilized solely to their block-level representations and token embeddings. This reduces reminiscence and communication overhead. outdated) to O(ND).
The researchers describe a cache-based pipeline communication and two-phase computational technique that makes Block AttnRes sensible for distributed coaching and inference. This leads to lower than 4% coaching overhead for pipeline parallelism, whereas the repository studies lower than 2% inference latency overhead for typical workloads.
Scaling the outcomes
The analysis crew evaluates 5 mannequin sizes and compares three variants at every measurement: PreNorm baseline, Full AttnRes, and Block AttnRes of about eight blocks. All variants inside every measurement group share the identical hyperparameters chosen within the baseline, and the researchers be aware that this makes the comparability conservative. The fitted scaling legislation is reported as:
Baseline: L = 1.891 × C-0.057
Block AttnRes: L = 1.870 × C-0.058
Full attentionless: L = 1.865 × C-0.057
The sensible implication is that AttnRes achieves decrease validation loss over all the computational vary examined, and block AttnRes achieves a decrease validation lack of roughly 1.25x extra computing energy.
Integration into Kimilinia
Moonshot AI additionally integrates AttnRes Kimi Linearits MoE structure 48B whole parameters and 3B activation parametersand pre-train it 1.4T token. In response to the analysis paper, AttnRes reduces PreNorm dilution by extra constraining the magnitude of the output throughout depth and distributing gradients extra evenly throughout the layer. One other implementation element is that every one pseudo-query vectors are initialized to zero, so the preliminary consideration weights are uniform throughout the supply layer, successfully lowering AttnRes to an equal-weighted common originally of coaching, avoiding preliminary instability.
In downstream evaluations, the reported positive factors are constant throughout all duties listed. 73.5 to 74.6 in MMLU, 36.9 to 44.4 in GPQA-Diamond, 76.3 to 78.0 in BBH, 53.5 to 57.1 in Math, 59.1 to 62.2 in HumanEval, 72.0 to 73.9 in MBPP, CMMLU, C-Eval 79.6 to 82.5.
Essential factors
- Consideration residuals exchange fastened residual accumulation with softmax consideration to earlier layers.
- The default AttnRes design makes use of discovered layer-specific pseudo-queries as an alternative of enter conditional queries.
- Block AttnRes makes this methodology sensible by lowering depth reminiscence and O(Ld) to O(Nd) communication.
- The Moonshot analysis crew studies that with decrease scaling losses than the PreNorm baseline, Block AttnRes matches the baseline compute by roughly 1.25x.
- At Kim Linear, AttnRes improves outcomes throughout inference, coding, and analysis benchmarks with restricted overhead.
try paper and lipo. Additionally, be at liberty to observe us Twitter Do not forget to affix us 120,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.

{kind=link}