


On this planet of large-scale language fashions (LLMs), as soon as accuracy is resolved, pace is the one factor that issues. As a human, it is okay to attend a second for search outcomes to look. If an AI agent performs 10 consecutive searches to unravel a fancy activity, a 1 second delay between every search leads to a ten second delay. This delay impairs the consumer expertise.
exercisethe search engine startup previously generally known as Metaphor, has been launched train prompt. A search mannequin designed to offer net knowledge from world wide to AI brokers 200ms. This eliminates the most important agent workflow bottleneck for software program engineers and knowledge scientists constructing acquisition augmentation era (RAG) pipelines.
Why latency is the enemy of RAGs
If you construct a RAG utility, the system follows a loop. The consumer asks a query, the system searches the online for context, and LLM processes that context. If it takes a search step 700ms to 1000msthe full “time to first token” will likely be slower.
Exa Instantaneous is 100ms and 200ms. In assessments performed from Western US-1 (Northern California) area, community latency is roughly 50ms. This pace permits the agent to carry out a number of searches in a single “thought” course of with out the consumer experiencing any delays.
No extra “wrapping” Google
A lot of the presently out there search APIs are “wrappers”. It sends queries to conventional engines like google like Google and Bing, retrieves the outcomes, and sends them again to the consumer. This provides an extra layer of overhead.
ExaInstant is completely different. It’s constructed on a proprietary end-to-end neural search and retrieval stack. As a substitute of matching key phrases, Exa embedded and transformer To grasp the which means of the question. This neural strategy ensures that the outcomes are related to the AI’s intent, not simply the precise phrases used. By proudly owning the whole stack from the crawler to the inference engine, Exa can optimize for pace in ways in which “wrapper” APIs can not.
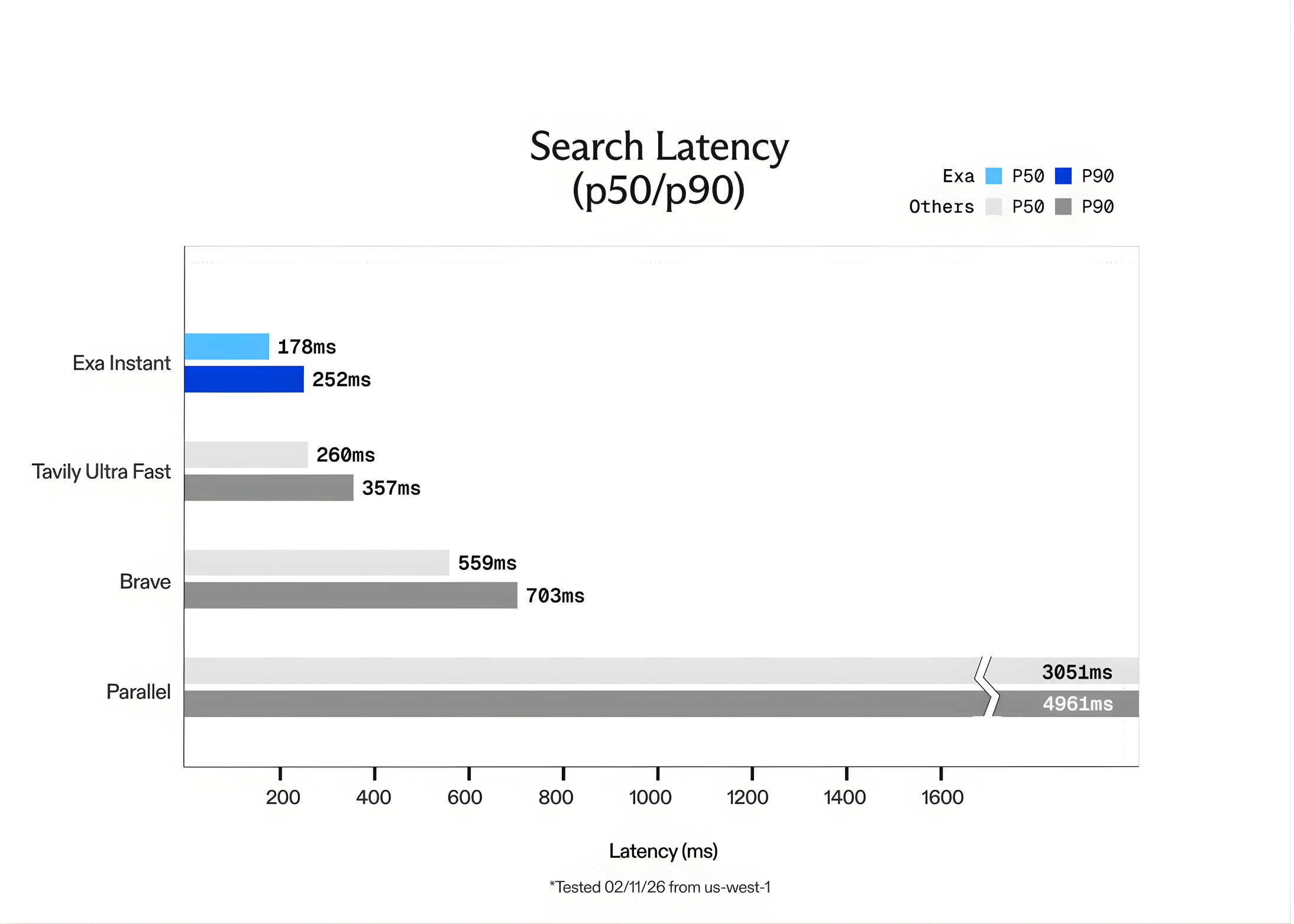
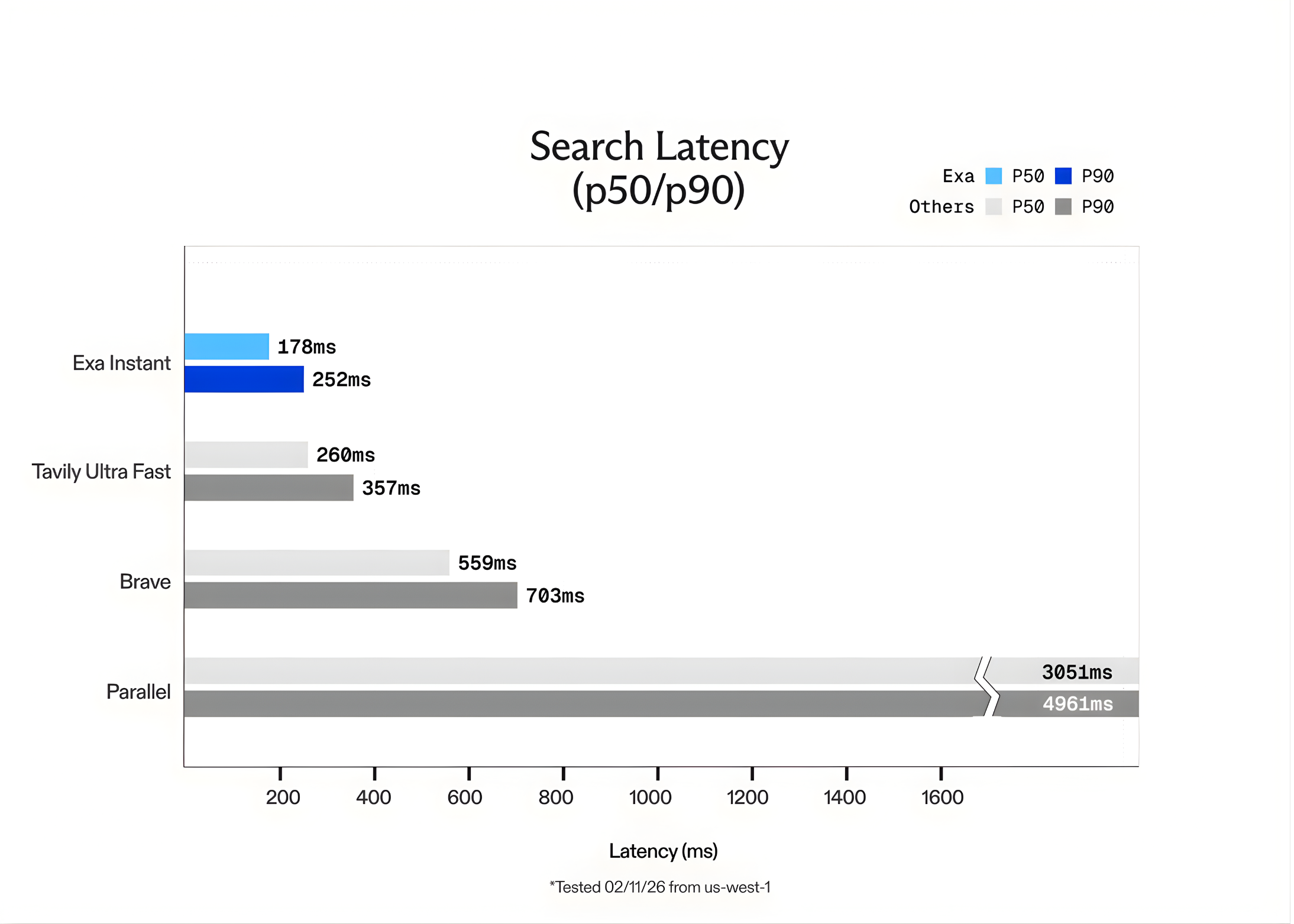
Pace benchmark
The Exa group benchmarked Exa Instantaneous in opposition to different widespread choices, together with: Tabilly tremendous quick and courageous. To make sure the assessments are truthful and keep away from “cached” outcomes, the group Seal QA question dataset. Additionally added random phrases that had been generated. GPT-5 Forces the engine to carry out a brand new search every time for every question.
The outcomes confirmed that Exa Instantaneous has the next options: 15 instances Quicker than our rivals. Though Exa provides different fashions corresponding to: exafast and exaauto For greater high quality inference, Exa Instantaneous is right for real-time purposes the place each millisecond counts.
Pricing and developer integration
Migrating to Exa Instantaneous is straightforward. You’ll be able to entry the API within the following methods: dashboard.exa.ai platform.
- Price: Exa Instantaneous value is 5 {dollars} Hit 1,000 request.
- capability: Search the identical big index of the online as Exa’s extra highly effective mannequin.
- Accuracy: Designed for pace, but staying related. For specialised entity searches, see Exa’s net set The product stays the gold customary; 20 instances Extra correct than Google for complicated queries.
The API returns clear, LLM-enabled content material, eliminating the necessity for builders to jot down customized scraping or HTML cleansing code.
Vital factors
- Actual-time agent latency is lower than 200ms: Exa Instantaneous is optimized for “agent” workflows the place pace is the bottleneck. By producing leads to the next interval, 200ms (Community latency can also be minimized) 50ms) permits AI brokers to carry out multi-step inference and parallel search with out the delays related to conventional engines like google.
- Proprietary Neural Stack vs. Wrapper‘: Not like many search APIs that merely “wrap” Google or Bing (including over 700ms of overhead), Exa Instantaneous is constructed by itself end-to-end neural search engine. Index and retrieve net knowledge utilizing a customized transformer-based structure, offering as much as the next capabilities: 15 instances Quicker efficiency than present options corresponding to Tavily and Courageous.
- Price-effective scaling: This mannequin is designed to make search “primitive” moderately than an costly luxurious. The value is 5 {dollars} Hit 1,000 This enables builders to combine real-time net lookups at each stage of an agent’s thought course of with out breaking the finances.
- Semantic intent moderately than key phrases: Exa Instantaneous Leverage embedded Prioritizes the “which means” of a question moderately than actual phrase matches. That is significantly efficient in RAG (Search Augmentation Technology) purposes the place discovering “link-worthy” content material that matches the LLM context is extra priceless than a easy key phrase hit.
- Optimized for LLM consumption: The API supplies extra than simply URLs. Clear and parsed HTML, Markdown, and Token environment friendly highlights. This reduces the necessity for customized scraping scripts and minimizes the variety of tokens that LLM must course of, additional dashing up the whole pipeline.
Please examine technical details. Additionally, be at liberty to comply with us Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.


{kind=link}