


Our work with massive enterprise clients and Amazon groups has revealed that top stakes use instances proceed to profit considerably from superior massive language mannequin (LLM) fine-tuning and post-training strategies. On this publish, we present you ways fine-tuning enabled a 33% discount in harmful treatment errors (Amazon Pharmacy), engineering 80% human effort discount (Amazon International Engineering Providers), and content material high quality assessments bettering 77% to 96% accuracy (Amazon A+). These aren’t hypothetical projections—they’re manufacturing outcomes from Amazon groups. Whereas many use instances may be successfully addressed by means of immediate engineering, Retrieval Augmented Technology (RAG) techniques, and switch key agent deployment,, our work with Amazon and huge enterprise accounts reveals a constant sample: One in 4 high-stakes functions—the place affected person security, operational effectivity, or buyer belief are on the road—demand superior fine-tuning and post-training strategies to attain production-grade efficiency.
This publish particulars the strategies behind these outcomes: from foundational strategies like Supervised Fine-Tuning (SFT) (instruction tuning), and Proximal Policy Optimization (PPO), to Direct Preference Optimization (DPO) for human alignment, to cutting-edge reasoning optimizations similar to Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO) purpose-built for agentic techniques. We stroll by means of the technical evolution of every strategy, look at real-world implementations at Amazon, current a reference structure on Amazon Internet Providers (AWS), and supply a call framework for choosing the correct method based mostly in your use case necessities.
The continued relevance of fine-tuning within the agentic AI
Regardless of the rising capabilities of basis fashions and agent frameworks, roughly one in all 4 enterprise use instances nonetheless require superior fine-tuning to attain the required efficiency ranges. These are sometimes situations the place the stakes are excessive from income or buyer belief views, domain-specific information is crucial, enterprise integration at scale is required, governance and management are paramount, enterprise course of integration is advanced, or multi-modal assist is required. Organizations pursuing these use instances have reported increased conversion to manufacturing, better return on funding (ROI), and as much as 3-fold year-over-year development when superior fine-tuning is appropriately utilized.
Evolution of LLM fine-tuning strategies for agentic AI
The evolution of generative AI has seen a number of key developments in mannequin customization and efficiency optimization strategies. Beginning with SFT, which makes use of labeled knowledge to show fashions to comply with particular directions, the sphere established its basis however confronted limitations in optimizing advanced reasoning. To handle these limitations, reinforcement learning (RL) refines the SFT course of with a reward-based system that gives higher adaptability and alignment with human desire. Amongst a number of RL algorithms, a big leap comes with PPO, which consists of a workflow with a worth (critic) community and a coverage community. The workflow accommodates a reinforcement studying coverage to regulate the LLM weights based mostly on the steerage of a reward mannequin. PPO scales nicely in advanced environments, although it has challenges with stability and configuration complexity.
DPO emerged as a breakthrough in early 2024, addressing PPO’s stability points by eliminating the express reward mannequin and as an alternative working straight with desire knowledge that features most popular and rejected responses for given prompts. DPO optimizes the LLM weights by evaluating the popular and rejected responses, permitting the LLM to be taught and regulate its conduct accordingly. This simplified strategy gained widespread adoption, with main language fashions incorporating DPO into their coaching pipelines to attain higher efficiency and extra dependable outputs. Different alternate options together with Odds Ratio Policy Optimization (ORPO), Relative Preference Optimization (RPO), Identity preference optimization (IPO), Kahneman-Tversky Optimization (KTO), they’re all RL strategies for human desire alignment. By incorporating comparative and identity-based desire buildings, and grounding optimization in behavioral economics, these strategies are computationally environment friendly, interpretable, and aligned with precise human decision-making processes.
As agent-based functions gained prominence in 2025, we noticed growing calls for for customizing the reasoning mannequin in brokers, to encode domain-specific constraints, security tips, and reasoning patterns that align with brokers’ meant capabilities (job planning, device use, or multi-step drawback fixing). The target is to enhance brokers’ efficiency in sustaining coherent plans, avoiding logical contradictions, and making acceptable selections for the area particular use instances. To satisfy these wants, GRPO was launched to boost reasoning capabilities and have become significantly notable for its implementation in DeepSeek-V1.
The core innovation of GRPO lies in its group-based comparability strategy: somewhat than evaluating particular person responses towards a hard and fast reference, GRPO generates teams of responses and evaluates every towards the common rating of the group, rewarding these performing above common whereas penalizing these under. This relative comparability mechanism creates a aggressive dynamic that encourages the mannequin to provide higher-quality reasoning. GRPO is especially efficient for bettering chain-of-thought (CoT) reasoning, which is the crucial basis for agent planning and sophisticated job decomposition. By optimizing on the group degree, GRPO captures the inherent variability in reasoning processes and trains the mannequin to persistently outperform its personal common efficiency.
Some advanced agent duties would possibly require extra fine-grained and crisp corrections inside lengthy reasoning chains, DAPO addresses these use instances by constructing upon GRPO sequence-level rewards, using a better clip ratio (roughly 30% increased than GRPO) to encourage extra various and exploratory considering processes, implementing dynamic sampling to remove much less significant samples and enhance general coaching effectivity, making use of token-level coverage gradient loss to offer extra granular suggestions on prolonged reasoning chains somewhat than treating whole sequences as monolithic models, and incorporating overlong reward shaping to discourage excessively verbose responses that waste computational sources. Moreover, when the agentic use instances require lengthy textual content outputs within the Mixture-of-Experts (MoE) mannequin coaching, GSPO helps these situations by shifting the optimization from GRPO’s token-level significance weights to the sequence degree. With these enhancements, the brand new strategies (DAPO and GSPO) allow extra environment friendly and complicated agent reasoning and planning technique, whereas sustaining computational effectivity and acceptable suggestions decision of GRPO.
Actual-world functions at Amazon
Utilizing the fine-tuning strategies described within the earlier sections, the post-trained LLMs play two essential roles in agentic AI techniques. First is within the growth of specialised tool-using parts and sub-agents inside the broader agent structure. These fine-tuned fashions act as area consultants, every optimized for particular capabilities. By incorporating domain-specific information and constraints throughout the fine-tuning course of, these specialised parts can obtain considerably increased accuracy and reliability of their designated duties in comparison with general-purpose fashions. The second key utility is to function the core reasoning engine, the place the inspiration fashions are particularly tuned to excel at planning, logical reasoning, and decision-making, for brokers in a extremely particular area. The intention is to enhance the mannequin’s capacity to keep up coherent plans and make logically sound selections—important capabilities for any agent system. This twin strategy, combining a fine-tuned reasoning core with specialised sub-components, was rising as a promising structure in Amazon for evolving from LLM-driven functions to agentic techniques, and constructing extra succesful and dependable generative AI functions. The next desk depicts multi-agent AI orchestration with of superior fine-tuning method examples.
| Amazon Pharmacy | Amazon International Engineering Providers | Amazon A+ Content material | |
|---|---|---|---|
| Area | Healthcare | Building and services | Ecommerce |
| Excessive-stakes issue | Affected person security | Operational effectivity | Buyer belief |
| Problem | $3.5 B annual price from treatment errors | 3+ hour inspection opinions | High quality evaluation at 100 million+ scale |
| Methods | SFT, PPO, RLHF, superior RL | SFT, PPO, RLHF, superior RL | Characteristic-based fine-tuning |
| Key consequence | 33% discount in treatment errors | 80% discount in human effort | 77%–96% accuracy |
Amazon Healthcare Providers (AHS) started its journey with generative AI with a big problem two years in the past, when the workforce tackled customer support effectivity by means of a RAG-based Q&A system. Preliminary makes an attempt utilizing conventional RAG with basis fashions yielded disappointing outcomes, with accuracy hovering between 60 and 70%. The breakthrough got here once they fine-tuned the embedding mannequin particularly for pharmaceutical area information, resulted in a big enchancment to 90% accuracy and an 11% discount in buyer assist contacts. In treatment security, treatment course errors can pose critical security dangers and value as much as $3.5 billion yearly to appropriate. By fine-tuning a mannequin with hundreds of expert-annotated examples, Amazon Pharmacy created an agent element that validates treatment instructions utilizing pharmacy logic and security tips. This lowered near-miss occasions by 33%, as indicated of their Nature Medicine publication. In 2025, AHS is increasing their AI capabilities and rework these separate LLM-driven functions right into a holistic multi-agent system to boost affected person expertise. These particular person functions pushed by fine-tuned fashions play a vital position within the general agentic structure, serving as area knowledgeable instruments to deal with particular mission-critical capabilities in pharmaceutical providers.
The Amazon International Engineering Providers (GES) workforce, answerable for overseeing lots of of Amazon success facilities worldwide, launched into an bold journey to make use of generative AI of their operations. Their preliminary foray into this know-how centered on creating a complicated Q&A system designed to help engineers in effectively accessing related design info from huge information repositories. The workforce’s strategy was fine-tuning a basis mannequin utilizing SFT, which resulted in a big enchancment in accuracy (measured by semantic similarity rating) from 0.64 to 0.81. To raised align with the suggestions from the subject material consultants (SMEs), the workforce additional refined the mannequin utilizing PPO incorporating the human suggestions knowledge, which boosted the LLM-judge scores from 3.9 to 4.2 out of 5, a exceptional achievement that translated to a considerable 80% discount within the effort required from the area consultants. Much like the Amazon Pharmacy case, these fine-tuned specialised fashions will proceed to perform as area knowledgeable instruments inside the broader agentic AI system.
In 2025, the GES workforce ventured into uncharted territory by making use of agentic AI techniques to optimize their enterprise course of. LLM fine-tuning methodologies represent a crucial mechanism for enhancing the reasoning capabilities in AI brokers, enabling efficient decomposition of advanced targets into executable motion sequences that align with predefined behavioral constraints and goal-oriented outcomes. It additionally serves as crucial structure element in facilitating specialised job execution and optimizing for task-specific efficiency metrics.
Amazon A+ Content material powers wealthy product pages throughout lots of of thousands and thousands of annual submissions. The A+ workforce wanted to guage content material high quality at scale—assessing cohesiveness, consistency, and relevancy, not simply surface-level defects. Content material high quality straight impacts conversion and model belief, making this a high-stakes utility.
Following the architectural sample seen in Amazon Pharmacy and International Engineering Providers, the workforce constructed a specialised analysis agent powered by a fine-tuned mannequin. They utilized feature-based fine-tuning to Nova Lite on Amazon SageMaker—coaching a light-weight classifier on imaginative and prescient language mannequin (VLM)-extracted options somewhat than updating full mannequin parameters. This strategy, enhanced by expert-crafted rubric prompts, improved classification accuracy from 77% to 96%. The end result: an AI agent that evaluates thousands and thousands of content material submissions and delivers actionable suggestions. This demonstrates a key precept from our maturity framework—method complexity ought to match job necessities. The A+ use case, whereas high-stakes and working at huge scale, is essentially a classification job well-suited to those strategies. Not each agent element requires GRPO or DAPO; deciding on the correct method for every drawback is what delivers environment friendly, production-grade techniques.
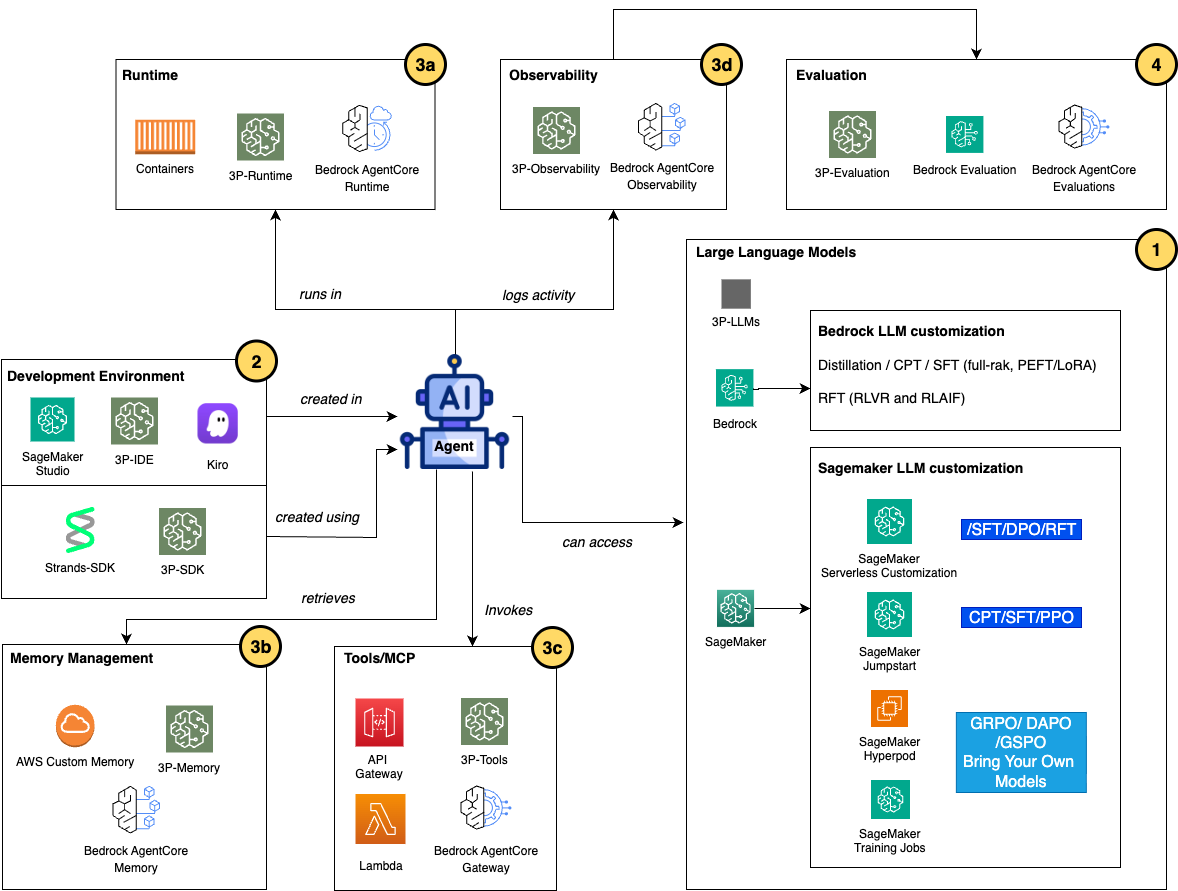
Reference structure for superior AI orchestration utilizing fine-tuning
Though fine-tuned fashions serve various functions throughout totally different domains and use instances in an agentic AI system, the anatomy of an agent stays largely constant and may be encompassed in element groupings, as proven within the following structure diagram.
This modular strategy adopts a variety of AWS generative AI providers, together with Amazon Bedrock AgentCore, Amazon SageMaker, and Amazon Bedrock, that maintains construction of key groupings that make up an agent whereas offering numerous choices inside every group to enhance an AI agent.
- LLM customization for AI brokers
Builders can use numerous AWS providers to fine-tune and post-train the LLMs for an AI agent utilizing the strategies mentioned within the earlier part. Should you use LLMs on Amazon Bedrock in your brokers, you should utilize a number of mannequin customization approaches to fine-tune your fashions. Distillation and SFT by means of parameter-efficient fine-tuning (PEFT) with low-rank adaptation (LoRA) can be utilized to deal with easy customization duties. For superior fine-tuning, Continued Pre-training (CPT) extends a basis mannequin’s information by coaching on domain-specific corpora (medical literature, authorized paperwork, or proprietary technical content material), embedding specialised vocabulary and area reasoning patterns straight into mannequin weights. Reinforcement fine-tuning (RFT), launched at re:Invent 2025, teaches fashions to know what makes a high quality response with out massive quantities of pre-labeled coaching knowledge. There are two approaches supported for RFT: Reinforcement Studying with Verifiable Rewards (RLVR) makes use of rule-based graders for goal duties like code technology or math reasoning, whereas Reinforcement Studying from AI Suggestions (RLAIF) makes use of AI-based judges for subjective duties like instruction following or content material moderation.
Should you require deeper management over mannequin customization infrastructure in your AI brokers, Amazon SageMaker AI gives a complete platform for customized mannequin growth and fine-tuning. Amazon SageMaker JumpStart accelerates the customization journey by providing pre-built options with one-click deployment of standard basis fashions (Llama, Mistral, Falcon, and others) and end-to-end fine-tuning notebooks that deal with knowledge preparation, coaching configuration, and deployment workflows. Amazon SageMaker Coaching jobs present managed infrastructure for executing customized fine-tuning workflows, routinely provisioning GPU cases, managing coaching execution, and dealing with cleanup after completion. This strategy fits most fine-tuning situations the place customary occasion configurations present enough compute energy and coaching completes reliably inside the job length limits. You should utilize SageMaker Coaching jobs with customized Docker containers and code dependencies housing any machine studying (ML) framework, coaching library, or optimization method, enabling experimentation with rising strategies past managed choices.
At re:Invent 2025, Amazon SageMaker HyperPod launched two capabilities for large-scale mannequin customization: Checkpointless coaching reduces checkpoint-restart cycles, shortening restoration time from hours to minutes. Elastic coaching routinely scales workloads to make use of idle capability and yields sources when higher-priority workloads peak. These options construct on the core strengths of HyperPod—resilient distributed coaching clusters with computerized fault restoration for multi-week jobs spanning hundreds of GPUs. HyperPod helps NVIDIA NeMo and AWS Neuronx frameworks, and is right when coaching scale, length, or reliability necessities exceed what job-based infrastructure can economically present.
In SageMaker AI, for builders who wish to customise fashions with out managing infrastructure, Amazon SageMaker AI serverless customization, launched at re:Invent 2025, gives a totally managed, UI- and SDK-driven expertise for mannequin fine-tuning. This functionality gives infrastructure administration—SageMaker routinely selects and provisions acceptable compute sources (P5, P4de, P4d, and G5 cases) based mostly on mannequin measurement and coaching necessities. By means of the SageMaker Studio UI, you may customise standard fashions (Amazon Nova, Llama, DeepSeek, GPT-OSS, and Qwen) utilizing superior strategies together with SFT, DPO, RLVR, and RLAIF. You too can run the identical serverless customization utilizing SageMaker Python SDK in your Jupyter pocket book. The serverless strategy gives pay-per-token pricing, computerized useful resource cleanup, built-in MLflow experiment monitoring, and seamless deployment to each Amazon Bedrock and SageMaker endpoints.
If it is advisable to customise Amazon Nova fashions in your agentic workflow, you are able to do it by means of recipes and prepare them on SageMaker AI. It gives end-to-end customization workflow together with mannequin coaching, analysis, and deployment for inference. with better flexibility and management to fine-tune the Nova fashions, optimize hyperparameters with precision, and implement strategies similar to LoRA PEFT, full-rank SFT, DPO, RFT, CPT, PPO, and so forth. For the Nova fashions on Amazon Bedrock, you can even prepare your Nova fashions by SFT and RFT with reasoning content material to seize intermediate considering steps or use reward-based optimization when actual appropriate solutions are tough to outline. You probably have extra superior agentic use instances that require deeper mannequin customization, you should utilize Amazon Nova Forge—launched at re:Invent 2025—to construct your personal frontier fashions from early mannequin checkpoints, mix your datasets with Amazon Nova-curated coaching knowledge, and host your customized fashions securely on AWS.
- AI agent growth environments and SDKs
The event atmosphere is the place builders creator, check, and iterate on agent logic earlier than deployment. Builders use built-in growth environments (IDEs) similar to SageMaker AI Studio (Jupyter Notebooks in comparison with code editors), Amazon Kiro, or IDEs on native machines like PyCharm. Agent logic is carried out utilizing specialised SDKs and frameworks that summary orchestration complexity—Strands gives a Python framework purpose-built for multi-agent techniques, providing declarative agent definitions, built-in state administration, and native AWS service integrations that deal with the low-level particulars of LLM API calls, device invocation protocols, error restoration, and dialog administration. With these growth instruments dealing with the low-level particulars of LLM API calls, builders can give attention to enterprise logic somewhat than infrastructure design and upkeep.
- AI agent deployment and operation
After your AI agent growth is accomplished and able to deploy in manufacturing, you should utilize Amazon Bedrock AgentCore to deal with agent execution, reminiscence, safety, and gear integration with out requiring infrastructure administration. Bedrock AgentCore gives a set of built-in providers, together with:
-
- AgentCore Runtime provides purpose-built environments that summary away infrastructure administration, whereas container-based alternate options (SageMaker AI jobs, AWS Lambda, Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon Elastic Container Service (Amazon ECS)) present extra management for customized necessities. Primarily, the runtime is the place your rigorously crafted agent code meets actual customers and delivers enterprise worth at scale.
- AgentCore Reminiscence offers your AI brokers the flexibility to recollect previous interactions, enabling them to offer extra clever, context-aware, and customized conversations. It gives a simple and highly effective option to deal with each short-term context and long-term information retention with out the necessity to construct or handle advanced infrastructure.
- With AgentCore Gateway, builders can construct, deploy, uncover, and connect with instruments at scale, offering observability into device utilization patterns, error dealing with for failed invocations, and integration with id techniques for accessing instruments on behalf of customers (utilizing OAuth or API keys). Groups can replace device backends, add new capabilities, or modify authentication necessities with out redeploying brokers as a result of the gateway structure decouples device implementation from agent logic—sustaining flexibility as enterprise necessities evolve.
- AgentCore Observability helps you hint, debug, and monitor agent efficiency in manufacturing environments. It gives real-time visibility into agent operational efficiency by means of entry to dashboards powered by Amazon CloudWatch and telemetry for key metrics similar to session rely, latency, length, token utilization, and error charges, utilizing the OpenTelemetry (OTEL) protocol customary.
- LLM and AI agent analysis
When your fine-tuned LLM pushed AI brokers are operating in manufacturing, it’s necessary to guage and monitor your fashions and brokers constantly to make sure prime quality and efficiency. Many enterprise use instances require customized analysis standards that encode area experience and enterprise guidelines. For the Amazon Pharmacy treatment course validation course of, analysis standards embrace: drug-drug interplay detection accuracy (proportion of identified contraindications accurately recognized), dosage calculation precision (appropriate dosing changes for age, weight, and renal perform), near-miss prevention price (discount in treatment errors that would trigger affected person hurt), FDA labeling compliance (adherence to authorised utilization, warnings, and contraindications), and pharmacist override price (proportion of agent suggestions accepted with out modification by licensed pharmacists).
On your fashions on Amazon Bedrock, you should utilize Amazon Bedrock evaluations to generate predefined metrics and human assessment workflows. For superior situations, you should utilize SageMaker Coaching jobs to fine-tune specialised choose fashions on domain-specific analysis datasets. For holistic AI agent analysis, AgentCore Evaluations, launched at re:Invent 2025, gives automated evaluation instruments to measure your agent or instruments efficiency on finishing particular duties, dealing with edge instances, and sustaining consistency throughout totally different inputs and contexts.
Choice information and beneficial phased strategy
Now that you simply perceive the technical evolution of superior fine-tuning strategies—from SFT to PPO, DPO, GRPO, DAPO and GSPO—the crucial query turns into when and why it’s best to use them. Our expertise reveals that organizations utilizing a phased maturity strategy obtain 70–85% manufacturing conversion charges (in comparison with the 30–40% trade common) and 3-fold year-over-year ROI development. The 12–18 month journey from preliminary agent deployment to superior reasoning capabilities delivers incremental enterprise worth at every part. The hot button is letting your use case necessities, obtainable knowledge, and measured efficiency information development—not technical sophistication for its personal sake.
The maturity path progresses by means of 4 phases (proven within the following desk). Strategic persistence on this development builds reusable infrastructure, collects high quality coaching knowledge, and validates ROI earlier than main investments. As our examples exhibit, aligning technical sophistication with human and enterprise wants delivers transformative outcomes and sustainable aggressive benefits in your most crucial AI functions.
| Section | Timeline | When to make use of | Key outcomes | Knowledge wanted | Funding |
| Section 1: Immediate engineering | 6–8 weeks |
|
|
Minimal prompts, examples | $50K–$80K (2–3 full-time workers (FTE)) |
| Section 2: Supervised Wonderful-Tuning (SFT) | 12 weeks |
|
|
500–5,000 labeled examples | $120K–$180K (3–4 FTE and compute) |
| Section 3: Direct Desire Optimization (DPO) | 16 weeks |
|
|
1,000–10,000 desire pairs | $180K–$280K (4–5 FTE and compute) |
| Section 4: GRPO and DAPO | 24 weeks |
|
|
10,000+ reasoning trajectories | $400K-$800K (6–8 FTE and HyperPod) |
Conclusion
Whereas brokers have remodeled how we construct AI techniques, superior fine-tuning stays a crucial element for enterprises looking for aggressive benefit in high-stakes domains. By understanding the evolution of strategies like PPO, DPO, GRPO, DAPO and GSPO, and making use of them strategically inside agent architectures, organizations can obtain vital enhancements in accuracy, effectivity, and security. The true-world examples from Amazon exhibit –that the mixture of agentic workflows with rigorously fine-tuned fashions delivers dramatic enterprise outcomes.
AWS continues to speed up these capabilities with a number of key launches at re:Invent 2025. Reinforcement fine-tuning (RFT) on Amazon Bedrock now permits fashions to be taught high quality responses by means of RLVR for goal duties and RLAIF for subjective evaluations—with out requiring massive quantities of pre-labeled knowledge. Amazon SageMaker AI Serverless Customization eliminates infrastructure administration for fine-tuning, supporting SFT, DPO, and RLVR strategies with pay-per-token pricing. For giant-scale coaching, Amazon SageMaker HyperPod launched checkpointless coaching and elastic scaling to scale back restoration time and optimize useful resource utilization. Amazon Nova Forge empowers enterprises to construct customized frontier fashions from early checkpoints, mixing proprietary datasets with Amazon-curated coaching knowledge. Lastly, AgentCore Analysis gives automated evaluation instruments to measure agent efficiency on job completion, edge instances, and consistency—closing the loop on production-grade agentic AI techniques.
As you consider your generative AI technique, use the choice information and phased maturity strategy outlined on this publish to determine the place superior fine-tuning can tip the scales from ok to transformative. Use the reference structure as a baseline to construction your agentic AI techniques, and use the capabilities launched at re:Invent 2025 to speed up your journey from preliminary agent deployment to production-grade outcomes.
Concerning the authors
 Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
 Kristine Pearce is a Principal Worldwide Generative AI GTM Specialist at AWS, centered on SageMaker AI mannequin customization, optimization, and inference at scale. She combines her MBA, BS Industrial Engineering background, and human-centered design experience to convey strategic depth and behavioral science to AI-enabled transformation. Outdoors work, she channels her creativity by means of artwork.
Kristine Pearce is a Principal Worldwide Generative AI GTM Specialist at AWS, centered on SageMaker AI mannequin customization, optimization, and inference at scale. She combines her MBA, BS Industrial Engineering background, and human-centered design experience to convey strategic depth and behavioral science to AI-enabled transformation. Outdoors work, she channels her creativity by means of artwork.
 Harsh Asnani is a Worldwide Generative AI Specialist Options Architect at AWS specializing in ML idea, MLOPs, and manufacturing generative AI frameworks. His background is in utilized knowledge science with a give attention to operationalizing AI workloads within the cloud at scale.
Harsh Asnani is a Worldwide Generative AI Specialist Options Architect at AWS specializing in ML idea, MLOPs, and manufacturing generative AI frameworks. His background is in utilized knowledge science with a give attention to operationalizing AI workloads within the cloud at scale.
 Sung-Ching Lin is a Principal Engineer at Amazon Pharmacy, the place he leads the design and adoption of AI/ML techniques to enhance buyer expertise and operational effectivity. He focuses on constructing scalable, agent-based architectures, ML analysis frameworks, and production-ready AI options in regulated healthcare domains.
Sung-Ching Lin is a Principal Engineer at Amazon Pharmacy, the place he leads the design and adoption of AI/ML techniques to enhance buyer expertise and operational effectivity. He focuses on constructing scalable, agent-based architectures, ML analysis frameworks, and production-ready AI options in regulated healthcare domains.
 Elad Dwek is a Senior AI Enterprise Developer at Amazon, working inside International Engineering, Upkeep, and Sustainability. He companions with stakeholders from enterprise and tech aspect to determine alternatives the place AI can improve enterprise challenges or utterly rework processes, driving innovation from prototyping to manufacturing. With a background in building and bodily engineering, he focuses on change administration, know-how adoption, and constructing scalable, transferable options that ship steady enchancment throughout industries. Outdoors of labor, he enjoys touring world wide together with his household.
Elad Dwek is a Senior AI Enterprise Developer at Amazon, working inside International Engineering, Upkeep, and Sustainability. He companions with stakeholders from enterprise and tech aspect to determine alternatives the place AI can improve enterprise challenges or utterly rework processes, driving innovation from prototyping to manufacturing. With a background in building and bodily engineering, he focuses on change administration, know-how adoption, and constructing scalable, transferable options that ship steady enchancment throughout industries. Outdoors of labor, he enjoys touring world wide together with his household.
 Carrie Music is a Senior Program Supervisor at Amazon, engaged on AI-powered content material high quality and buyer expertise initiatives. She companions with utilized science, engineering, and UX groups to translate generative AI and machine studying insights into scalable, customer-facing options. Her work focuses on bettering content material high quality and streamlining the procuring expertise on product element pages.
Carrie Music is a Senior Program Supervisor at Amazon, engaged on AI-powered content material high quality and buyer expertise initiatives. She companions with utilized science, engineering, and UX groups to translate generative AI and machine studying insights into scalable, customer-facing options. Her work focuses on bettering content material high quality and streamlining the procuring expertise on product element pages.

{kind=link}
{kind=link}