


As organizations scale their generative AI implementations, the important problem of balancing high quality, value, and latency turns into more and more complicated. With inference prices dominating 70–90% of huge language mannequin (LLM) operational bills, and verbose prompting methods inflating token quantity by 3–5x, organizations are actively in search of extra environment friendly approaches to mannequin interplay. Conventional prompting strategies, whereas efficient, typically create pointless overhead that impacts each value effectivity and response instances.
This submit explores Chain-of-Draft (CoD), an modern prompting approach launched in a Zoom AI Analysis paper Chain of Draft: Thinking Faster by Writing Less, that revolutionizes how fashions method reasoning duties. Whereas Chain-of-Thought (CoT) prompting has been the go-to technique for enhancing mannequin reasoning, CoD provides a extra environment friendly various that mirrors human problem-solving patterns—utilizing concise, high-signal pondering steps relatively than verbose explanations.
Utilizing Amazon Bedrock and AWS Lambda, we show a sensible implementation of CoD that may obtain outstanding effectivity beneficial properties: as much as 75percentreduction in token utilization and over 78% lower in latency, all whereas sustaining the accuracy ranges of conventional CoT approaches. By detailed examples, code samples, and efficiency metrics, we stroll by way of deploying CoD in an AWS atmosphere and measuring its affect on AI implementations. This method not solely optimizes prices but in addition enhances the general person expertise by way of sooner response instances.
Understanding Chain-of-Thought prompting
Chain-of-Thought (CoT) prompting is a way that guides massive language fashions to purpose by way of issues step-by-step, relatively than leaping on to a solution. This technique has confirmed significantly efficient for complicated duties equivalent to logical puzzles, mathematical issues, and commonsense reasoning eventualities. By mimicking human problem-solving patterns, CoT helps fashions break down complicated issues into manageable steps, bettering each accuracy and transparency.
Instance of CoT prompting:
Query: If there are 5 apples and also you eat 2 apples, what number of apples stay?
CoT response: Begin with 5 apples. I eat 2 apples. Subtract 2 from 5. 5 – 2 = 3 apples remaining.
Nonetheless, as the instance above exhibits, this method comes with some drawbacks in manufacturing environments. The verbose nature of CoT responses results in elevated token utilization and better prices. The prolonged processing time required for producing detailed explanations leads to larger latency, making it in some instances much less appropriate for real-time purposes. Moreover, the detailed outputs can complicate downstream processing and integration with different methods.
Introducing Chain-of-Draft prompting
Chain-of-Draft (CoD) is a novel prompting approach that goals to scale back verbosity by limiting the variety of phrases utilized in every reasoning step, focusing solely on the important calculations or transformations wanted to progress, whereas considerably lowering token utilization and inference latency. CoD attracts inspiration from how people remedy issues with temporary psychological notes relatively than verbose explanations—encouraging LLMs to generate compact, high-signal reasoning steps.
The important thing innovation of CoD lies in its constraint: every reasoning step is proscribed to 5 phrases or much less. This limitation forces the mannequin to deal with important logical elements whereas minimizing pointless verbosity. As an illustration, when fixing a mathematical phrase downside, as an alternative of producing full sentences explaining every step, CoD produces concise numerical operations and key logical markers.
Think about this instance:
Query: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. What number of lollipops did Jason give to Denny?
A CoT response may embrace a number of sentences explaining the reasoning course of like, “Jason had 20 lollipops. He gave some to Denny and now has 12 left. So he gave away 8.”
In distinction, a CoD response would merely state “Begin: 20, Finish: 12, 20 – 12 = 8.”
This minimalist method achieves the identical logical reasoning whereas utilizing considerably fewer tokens.
Why CoD works
The important thing concept behind CoD is that almost all reasoning chains comprise excessive redundancy. By distilling steps to their semantic core, CoD helps the mannequin deal with the logical construction of the duty relatively than language fluency. This leads to decrease inference latency because of shorter outputs, decreased token value from minimized technology and cleaner output for downstream parsing or automation.
This minimalism is achieved with out sacrificing accuracy. Actually, in response to the original Zoom AI paper, CoD “achieved 91.4% accuracy on GSM8K (vs. 95.3% for CoT), whereas lowering output tokens by as much as 92.1%, and chopping latency practically in half in a number of fashions examined.”
Beneath the hood, the CoD approach makes use of pure language prompts that instruct the mannequin to “suppose step-by-step” whereas explicitly limiting the size of every reasoning step: “Solely maintain a minimal draft for every pondering step, with 5 phrases at most.”
The researchers discovered that fashions like GPT-4, Claude, and Cohere Command R+ carried out particularly properly below these constraints, significantly when utilizing few-shot examples to show the concise reasoning sample.
Past arithmetic duties, CoD has demonstrated sturdy efficiency in commonsense reasoning duties. Within the original Zoom AI paper, the authors evaluated CoD utilizing big-bench benchmarks, particularly centered on date understanding and sports activities understanding duties. The identical system prompts had been used as in arithmetic evaluations, sustaining consistency throughout experiments. The outcomes revealed that CoD not solely considerably reduces token technology and latency, however in a number of instances, outperforms CoT in accuracy—particularly when verbose output isn’t mandatory.
One notable discovering was with a big language mannequin on the sports activities understanding activity: CoT produced lengthy, verbose responses with a median of 172.5 output tokens, whereas CoD decreased this to 31.3 tokens, attaining an ~82% discount. Curiously, accuracy improved barely, demonstrating that CoD may be simpler with fewer phrases.
Right here’s a snapshot from the original paper displaying the analysis throughout two LLMs:
| Mannequin | Immediate | Accuracy | Token | Latency |
| LLM-1 | Customary | 72.60% | 5.2 | 0.6s |
| Chain-of-Thought | 90.20% | 75.7 | 1.7s | |
| Chain-of-Draft | 88.10% | 30.2 | 1.3s | |
| LLM-2 | Customary | 84.30% | 5.2 | 1.0s |
| Chain-of-Thought | 87% | 172.5 | 3.2s | |
| Chain-of-Draft | 89.70% | 31.3 | 1.4s |
Desk 1. Date understanding analysis outcomes. (Chain of Draft: Thinking Faster by Writing Less)
These outcomes additional validate CoD’s worth in real-world reasoning eventualities, displaying that fashions can purpose successfully with fewer, smarter tokens. The implication for manufacturing use is obvious: sooner responses and decrease value, with out a trade-off in high quality.
Within the subsequent part, we present how we carried out this prompting technique utilizing Amazon Bedrock and AWS Lambda, and the way CoD compares to CoT throughout basis fashions in real-world situations.
Implementation and analysis on AWS
To judge the effectivity of CoD prompting strategies, we run a take a look at in Amazon Bedrock and remedy the “Crimson, Blue, and Inexperienced Balls” puzzle utilizing an LLM.
The Puzzle: You might have three bins. Every field comprises three balls, however the balls may be crimson, blue, or inexperienced. Field 1 is labelled “Crimson Balls Solely.” Field 2 is labelled “Blue Balls Solely.” Field 3 is labelled “Crimson and Blue Balls Solely.” The labels on the bins are all incorrect. The duty is that you should decide the contents of every field, figuring out that every one labels are incorrect. You possibly can solely take a single ball from one field and observe its shade. Then you should deduce the contents of all three bins.
We selected this puzzle as a result of fixing it requires a measurable variety of tokens, as the issue must be damaged down into a number of logical steps, every requiring the LLM to course of and retain data. The LLM must deal with “if-then” statements and think about completely different prospects resulting in logical reasoning. The LLM additionally wants to take care of the context of the puzzle all through the reasoning course of, and lastly, the LLM wants to know the symbols and relationships between the colours, labels, and balls.
Conditions
To check and evaluate the prompting strategies in Amazon Bedrock, confirm you may have the next stipulations:
- AWS account with permission to create and execute Lambda features
- Amazon Bedrock entry enabled in your AWS Area (for instance, us-east-1) together with Mannequin Entry for instance, Mannequin-1 and Mannequin-2; choose any mannequin of your alternative
- AWS IAM position for the Lambda perform execution
- Permissions to invoke Amazon Bedrock fashions (bedrock:Converse)
- Permissions to place customized metrics in Amazon CloudWatch (cloudwatch:PutMetricData)
- (Elective) CloudWatch Logs permissions for logging
- Crucial Python libraries (boto3), included within the AWS Lambda runtime atmosphere for Python 3.9 or later
Analysis with Amazon Bedrock Converse API
We begin by making a Python Lambda perform designed to work together with fashions utilizing Amazon Bedrock to resolve the puzzle. This AWS Lambda perform makes use of the Amazon Bedrock Converse API, which offers a unified, constant interface to work together with numerous basis fashions. The Converse API simplifies sending conversational messages to fashions and receiving their replies, supporting multi-turn dialogue and superior options whereas managing AWS authentication and infrastructure. The Lambda perform initializes shoppers for Amazon Bedrock Runtime and CloudWatch and ship a static puzzle immediate as a person message to the Converse API, retrieve the response textual content, and calculate latency and token utilization for each enter and output. These metrics are printed to CloudWatch, and related logs are recorded. Lastly, the perform returns the mannequin’s reply together with enter/output token counts. Errors are logged and returned with correct HTTP error code.
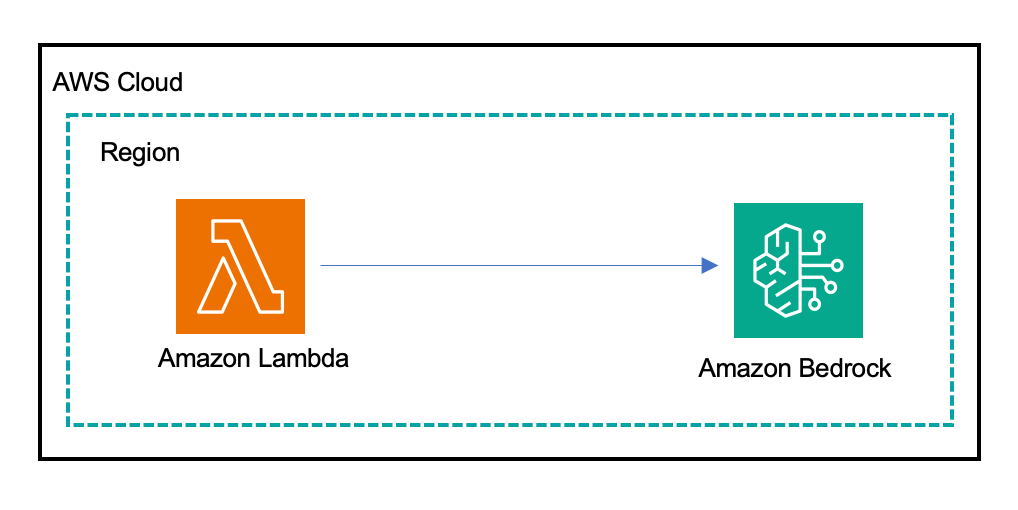
The Lambda perform
import json
import boto3
import time
import logging
from botocore.exceptions import ClientError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
bedrock = boto3.shopper('bedrock-runtime', region_name="us-east-1")
cloudwatch = boto3.shopper('cloudwatch')
MODEL_ID = "model1-id" # Exchange with precise Mannequin 1 ID
PROMPT = (
"You might have three bins. Every field comprises three balls, however the balls may be crimson, blue, or inexperienced. "
"Field 1 is labeled as 'Crimson Balls Solely'. Field 2 is labeled 'Blue Balls Solely'. "
"Field 3 is labeled 'Crimson and Blue Balls Solely'. The labels on the bins are all incorrect. "
"The Job: You need to decide the contents of every field, figuring out that every one labels are incorrect. "
"You possibly can solely take a single ball from one field and observe its shade. "
"Then you should deduce the contents of all three bins. "
"Assume step-by-step to reply the query, however solely maintain a minimal draft for every pondering step, with 5 phrases at most. "
"Return the reply on the finish of the response after separator ###."
)
def lambda_handler(occasion, context):
dialog = [{"role": "user", "content": [{"text": PROMPT}]}]
start_time = time.time()
attempt:
response = bedrock.converse(
modelId=MODEL_ID,
messages=dialog,
inferenceConfig={"maxTokens": 2000, "temperature": 0.7}
)
response_text = response["output"]["message"]["content"][0]["text"]
latency = time.time() - start_time
input_tokens = len(PROMPT.break up())
output_tokens = len(response_text.break up())
cloudwatch.put_metric_data(
Namespace="ChainOfDraft",
MetricData=[
{"MetricName": "Latency", "Value": latency, "Unit": "Seconds"},
{"MetricName": "TokensUsed", "Value": input_tokens + output_tokens, "Unit": "Count"},
]
)
logger.data({
"request_id": context.aws_request_id,
"latency_seconds": spherical(latency, 2),
"total_tokens": input_tokens + output_tokens
})
return {
"statuscode": 200,
"physique": json.dumps({
"response": response_text,
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"metrics": {
"latency_seconds": spherical(latency, 2),
"total_tokens": input_tokens + output_tokens,
},
}),
}
besides ClientError as e:
logger.error(f"AWS service error: {e}")
return {"statuscode": 500, "physique": json.dumps("Service error occurred")}
besides Exception as e:
logger.error(f"Surprising error: {e}")
return {"statusCode": 500, "physique": json.dumps(f"Inside error occurred: {e}")}Should you’re utilizing Mannequin 2, change the MODEL_ID within the above code to Mannequin 2 id. The remainder of the code stays the identical.
Testing
Listed below are the three prompts used with the fashions to check the Lambda perform. Change the PROMPT within the Lambda perform to check out the prompting strategies.
Customary immediate:
“You might have three bins. Every field comprises three balls, however the balls may be crimson, blue, or inexperienced. Field 1 is labelled as ‘Crimson Balls Solely’. Field 2 is labelled ‘Blue Balls Solely’. Field 3 is labelled ‘Crimson and Blue Balls Solely’. The labels on the bins are all incorrect. The Job: You need to decide the contents of every field, figuring out that every one labels are incorrect. You possibly can solely take a single ball from one field and observe its shade. Then you should deduce the contents of all three bins. Reply the query immediately. Don’t return any preamble clarification or reasoning.”
Chain-of-Thought immediate:
“You might have three bins. Every field comprises three balls, however the balls may be crimson, blue, or inexperienced. Field 1 is labelled as ‘Crimson Balls Solely’. Field 2 is labelled ‘Blue Balls Solely’. Field 3 is labelled ‘Crimson and Blue Balls Solely’. The labels on the bins are all incorrect. The Job: You need to decide the contents of every field, figuring out that every one labels are incorrect. You possibly can solely take a single ball from one field and observe its shade. Then you should deduce the contents of all three bins. Assume step-by-step to reply the query. Return the reply on the finish of the response after separator.”
Chain-of-Draft immediate:
“You might have three bins. Every field comprises three balls, however the balls may be crimson, blue, or inexperienced. Field 1 is labelled as ‘Crimson Balls Solely’. Field 2 is labelled ‘Blue Balls Solely’. Field 3 is labelled ‘Crimson and Blue Balls Solely’. The labels on the bins are all incorrect. The Job: You need to decide the contents of every field, figuring out that every one labels are incorrect. You possibly can solely take a single ball from one field and observe its shade. Then you should deduce the contents of all three bins. Assume step-by-step to reply the query however solely maintain a minimal draft for every pondering step, with 5 phrases at most. Return the reply on the finish of the response after separator.”
Outcomes
On testing the lambda perform with the above prompts with the 2 fashions, the outcomes are as follows:
| Mannequin | Immediate approach | Enter tokens | Output tokens | Complete Tokens | Tokens Discount COD vs. COT |
Latency in seconds | Latency Discount COD vs. COT |
| Mannequin-1 | Customary Immediate | 102 | 23 | 125 | 0.8 | ||
| Chain of Thought | 109 | 241 | 350 | 3.28 | |||
| Chain of Draft | 123 | 93 | 216 | ((350-216)/350) × 100 = 39% discount | 1.58 | ((3.28-1.58)/3.28) × 100 = 52% discount | |
| Mannequin-2 | Customary Immediate | 102 | 17 | 119 | 0.6 | ||
| Chain of Thought | 109 | 492 | 601 | 3.81 | |||
| Chain of Draft | 123 | 19 | 142 | ((601-142)/601) × 100 = 76% discount | 0.79 | ((3.81-0.79)/3.81) × 100 = 79% discount |
Desk 2: Outcomes of Testing with Customary immediate, CoD immediate and CoT immediate throughout the fashions
The comparability exhibits that Chain of Draft (CoD) is way extra environment friendly than Chain of Thought (CoT) throughout each fashions. For Mannequin-1, CoD reduces whole token utilization from 350 to 216 (a 39% discount) and cuts latency from 3.28 to 1.58 seconds (a 52% discount). The beneficial properties are even better for Mannequin-2 the place COD lowers tokens from 601 to 142 (a 76% discount) and latency from 3.81 to 0.79 seconds (a 79% discount). Total, COD delivers vital enhancements in pace and token effectivity in comparison with COT, with particularly sturdy outcomes on Mannequin-2.
When to keep away from utilizing CoD
Whereas CoD prompting provides compelling advantages by way of effectivity and efficiency, it’s not universally relevant. There are eventualities the place conventional CoT or much more verbose reasoning could also be simpler or applicable. Primarily based on our experimentation and findings from the unique analysis, listed here are some key concerns:
- Zero-shot or prompt-only use instances: CoD performs finest when paired with sturdy few-shot examples. In zero-shot eventualities—the place no reasoning patterns are supplied—fashions typically battle to undertake the minimalist drafting type on their very own. This may result in decrease accuracy or incomplete reasoning steps.
- Duties requiring excessive interpretability: To be used instances like authorized or medical doc evaluation, audit trails, or regulated environments, verbose reasoning could also be important. In such instances, CoT’s extra clear, step-by-step explanations present higher traceability and belief.
- Small language fashions: CoD underperformed on fashions with fewer than 3 billion parameters. These fashions lack the instruction-following constancy and reasoning energy wanted to execute CoD-style prompts successfully. CoT could yield higher leads to these instances.
- Inventive or open-ended duties: Duties that profit from elaboration—like writing, ideation, or user-facing conversations—could lose worth if too condensed. CoD is finest fitted to structured reasoning, logic, and deterministic duties the place brevity improves efficiency.
In brief, CoD shines when the objective is environment friendly reasoning with minimal overhead—however cautious immediate design, mannequin choice, and activity match are key to success.
Conclusion and key takeaways
CoD prompting emerges as an environment friendly approach for organizations in search of to optimize their generative AI implementations. By encouraging language fashions to purpose in concise, centered steps, CoD achieves outstanding enhancements in each efficiency and useful resource utilization. Our implementation utilizing Amazon Bedrock and AWS Lambda demonstrated vital advantages in token utilization and enchancment in latency in comparison with conventional CoT prompting, whereas sustaining comparable accuracy throughout numerous basis fashions and complicated reasoning duties. As AI continues to evolve, CoD represents a big step in the direction of extra environment friendly and performant language fashions. It’s significantly precious for structured reasoning duties the place pace and token effectivity are important, although it’s not a one-size-fits-all resolution. We encourage practitioners to discover CoD in their very own AI workflows, leveraging its potential to scale back prices, enhance response instances, and improve scalability. The way forward for AI lies in smarter, extra environment friendly reasoning approaches, and CoD prompting is on the forefront of this transformation.
To study extra about immediate engineering and CoD approach, check with the next sources:
In regards to the authors
 Ahmed Raafat is a Senior Supervisor at AWS main the AI/ML Specialist crew within the UK & Eire, with over 20 years of know-how expertise serving to main corporations remodel by way of AI and cloud applied sciences. As a trusted C-suite advisor and thought chief, he guides organizations in AI technique and adoption, serving to them use rising applied sciences for innovation and development.
Ahmed Raafat is a Senior Supervisor at AWS main the AI/ML Specialist crew within the UK & Eire, with over 20 years of know-how expertise serving to main corporations remodel by way of AI and cloud applied sciences. As a trusted C-suite advisor and thought chief, he guides organizations in AI technique and adoption, serving to them use rising applied sciences for innovation and development.
 Kiranpreet Chawla is a Options Architect at Amazon Net Companies, leveraging over 15 years of numerous know-how expertise to drive cloud and AI transformations. Kiranpreet’s experience spans from cloud modernization to AI/ML implementations, enabling her to offer complete steerage to clients throughout numerous industries.
Kiranpreet Chawla is a Options Architect at Amazon Net Companies, leveraging over 15 years of numerous know-how expertise to drive cloud and AI transformations. Kiranpreet’s experience spans from cloud modernization to AI/ML implementations, enabling her to offer complete steerage to clients throughout numerous industries.

{kind=link}
{kind=link}