


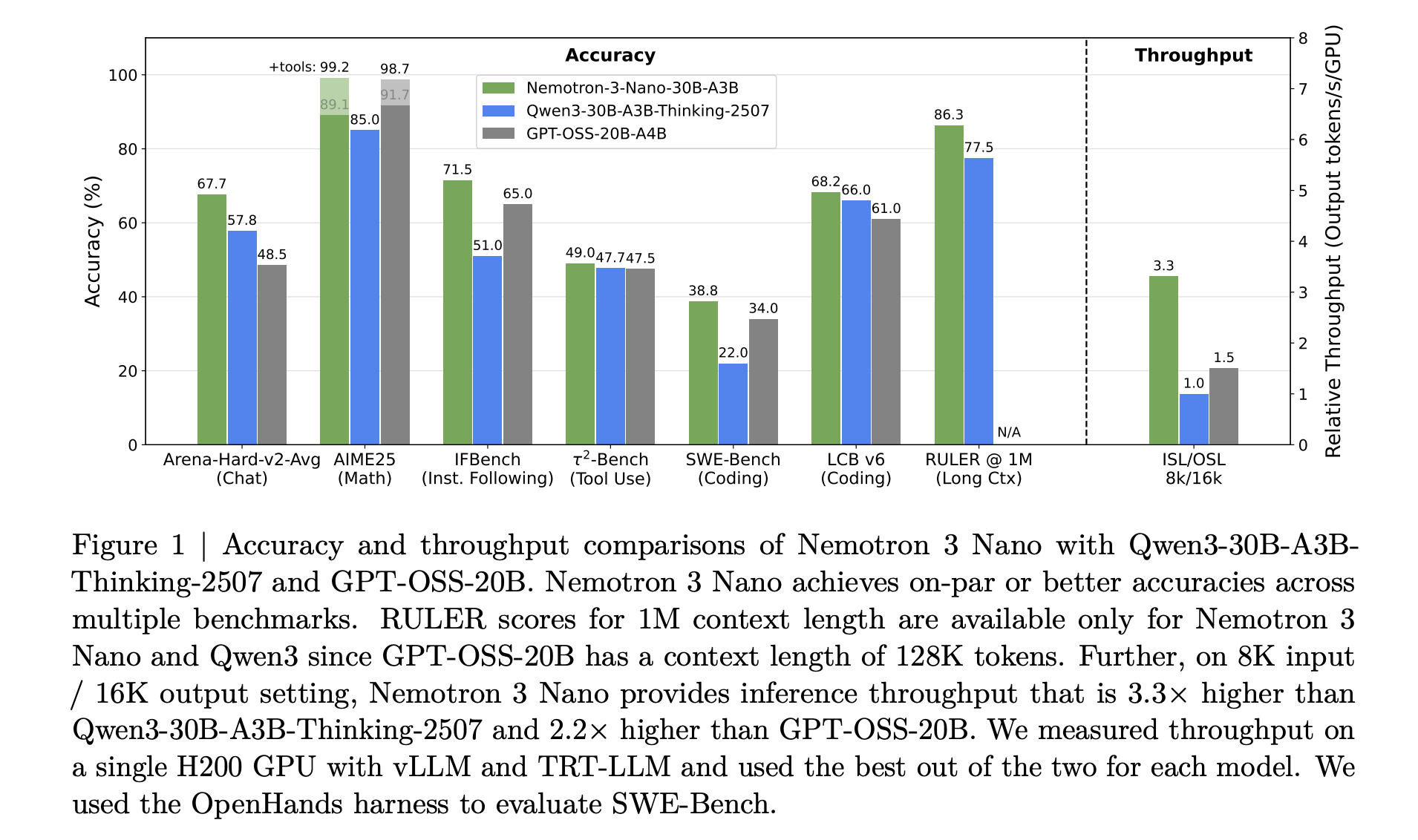
NVIDIA has launched the Nemotron 3 household of open fashions as a part of a full stack of agent AI, together with mannequin weights, datasets, and reinforcement studying instruments. This household is available in three sizes: Nano, Tremendous, and Extremely, and targets multi-agent techniques that require lengthy context inferences with tight management over inference prices. Nano has about 30 billion parameters and about 3 billion actives per token, Tremendous has about 100 billion parameters and as much as 10 billion actives per token, and Extremely has about 500 billion parameters and as much as 50 billion actives per token.
Mannequin household and goal workload
Nemotron 3 is delivered as a household of environment friendly open fashions for agent purposes. The road consists of Nano, tremendous and extremely fashionsevery tailor-made to completely different workload profiles.
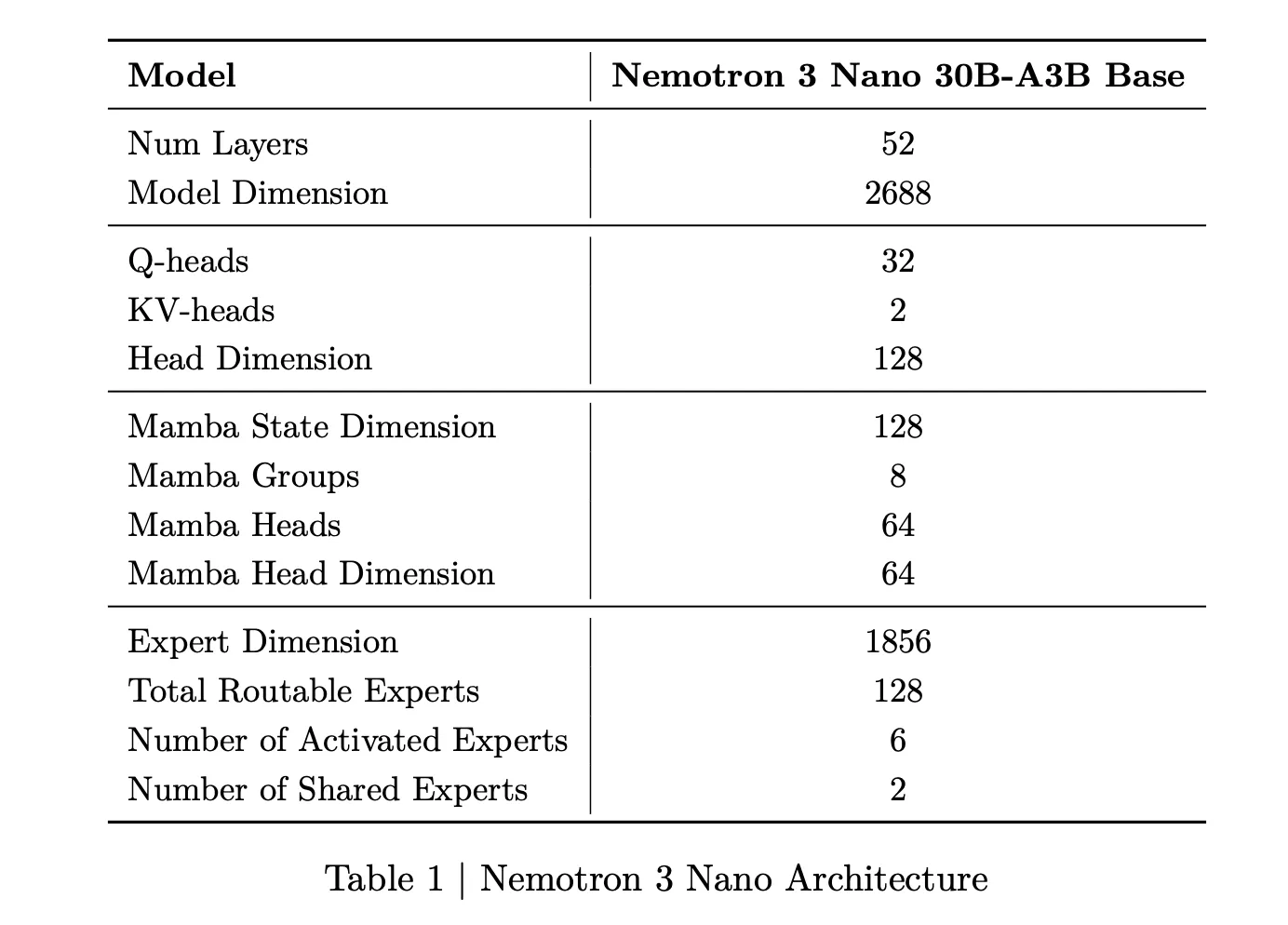
Nemotron 3 nano is a Combination of Specialists hybrid Mamba Transformer language mannequin with roughly 31.6 billion parameters. There are solely about 3.2 billion parameters lively per ahead move, or 3.6 billion together with padding. This sparse activation permits the mannequin to take care of excessive expressiveness whereas holding computational prices low.
Nemotron 3 Tremendous has roughly 100 billion parameters, with as much as 10 billion lively per token. Nemotron 3 Extremely scales this design to roughly 500 billion parameters, delivering as much as 50 billion actives per token. Tremendous is focused at high-precision inference for large-scale multi-agent purposes, whereas Extremely is focused at complicated exploration and planning workflows.
Nemotron 3 nano is now obtainable in Open Weights and Recipes on Hugging Face and as an NVIDIA NIM microservice. Tremendous and Extremely are scheduled for early 2026.
NVIDIA Nemotron 3 Nano helps native context lengths of as much as 1 million tokens whereas delivering roughly 4x greater token throughput than Nemotron 2 Nano, considerably decreasing inference token utilization. This mix is focused at multi-agent techniques working in massive workspaces, akin to lengthy paperwork or massive code bases.
Hybrid Mamba Transformer MoE Structure
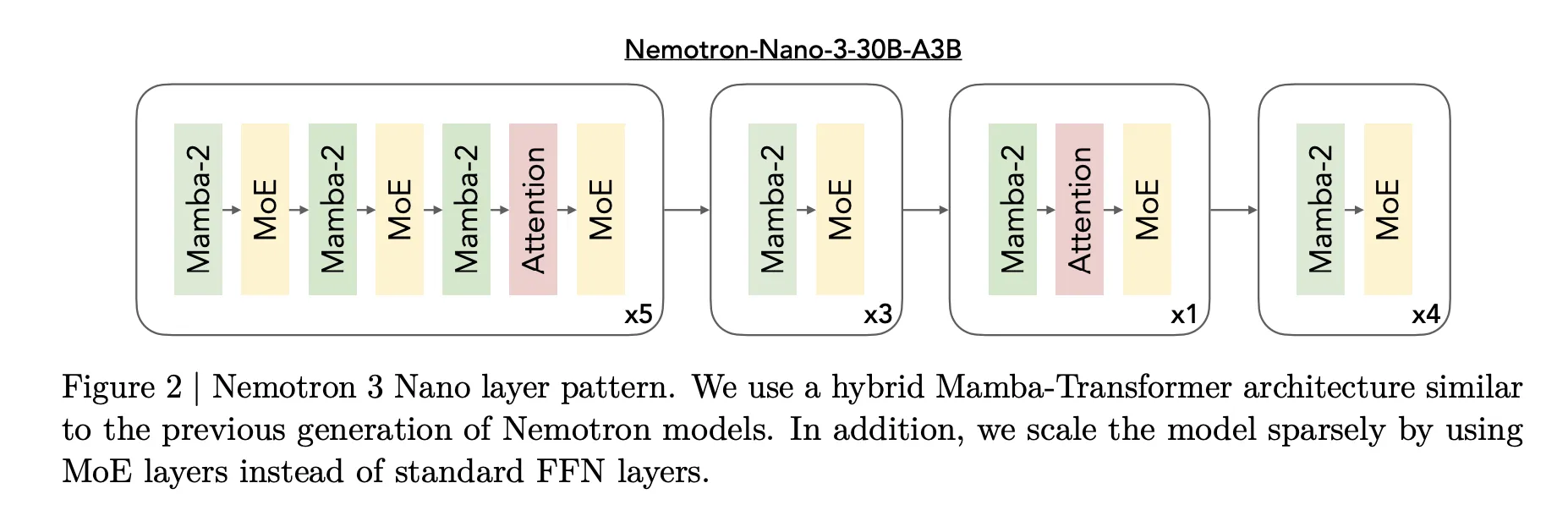
The core design of Nemotron 3 is the knowledgeable blended hybrid Mamba Transformer structure. This mannequin mixes Mamba sequence blocks, consideration blocks, and sparse knowledgeable blocks right into a single stack.
For Nemotron 3 Nano, the analysis crew describes a sample that interleaves Mamba 2 blocks, consideration blocks, and MoE blocks. The usual feedforward layer of earlier generations of Nemotron is changed by the MoE layer. The realized router selects a small subset of consultants for every token. For instance, for Nano, choose 6 out of 128 routable consultants. This retains the variety of lively parameters shut to three.2 billion whereas the complete mannequin has 31.6 billion parameters.
Mamba 2 handles long-range sequence modeling utilizing state-space fashion updates, the eye layer supplies direct token-to-token interplay for structure-sensitive duties, and MoE supplies parameter scaling with out proportional computational scaling. The important thing level is that almost all layers are both quick sequences or sparse knowledgeable computations, and full consideration is used solely when it’s most vital for inference.
With Nemotron 3 Tremendous and Extremely, NVIDIA provides LatentMoE. The tokens are projected right into a low-dimensional latent house, an knowledgeable operates on that latent house, and the output is back-projected. This design permits for a number of instances as many consultants at related communication and computational prices, supporting better specialization throughout duties and languages.
Tremendous and Extremely additionally embrace multi-token predictions. A number of output heads share a standard trunk and predict a number of future tokens in a single move. This enables for higher optimization throughout coaching and speculative decoding that performs fewer full ahead passes throughout inference.
Coaching knowledge, accuracy format, and context window
Nemotron 3 is educated on large-scale textual content and code knowledge. The analysis crew studies pre-training on roughly 25 trillion tokens, together with greater than 3 trillion new distinctive tokens on Nemotron 2 generations. Nemotron 3 Nano makes use of Nemotron Frequent Crawl v2 level 1, Nemotron CC Code, Nemotron Pretraining Code v2, in addition to specialised datasets for science and reasoning content material.
Tremendous and Extremely are primarily educated in NVFP4, a 4-bit floating level format optimized for NVIDIA accelerators. Matrix multiplication operations are carried out in NVFP4, however accumulation makes use of greater precision. This reduces reminiscence strain and will increase throughput whereas sustaining accuracy shut to plain codecs.
All Nemotron 3 fashions help context home windows of as much as 1 million tokens. The structure and coaching pipeline are tailor-made for long-term inference over this size. That is important in multi-agent environments that move massive traces and shared working reminiscence between brokers.
Vital factors
- Nemotron 3 is a three-layer open mannequin household for agent AI.: Nemotron 3 is available in Nano, Tremendous, and Extremely variants. Nano has about 30 billion parameters and about 3 billion actives per token, Tremendous has about 100 billion parameters and as much as 10 billion actives per token, and Extremely has about 500 billion parameters and as much as 50 billion actives per token. This household targets multi-agent purposes that require environment friendly lengthy context inference.
- Hybrid Mamba Transformer MoE with 1 million token context: The Nemotron 3 mannequin makes use of a hybrid Mamba 2 and Transformer structure with a sparse mixture of consultants and helps a 1 million token context window. This design permits processing lengthy contexts with excessive throughput. Solely a small subset of consultants is lively for every token, and a focus is used the place it’s most helpful for inference.
- Potential MoE and multi-token predictions in Tremendous and Extremely: The Tremendous and Extremely variants add a latent MoE the place the knowledgeable computation is finished in a diminished latent house, which reduces communication prices and permits for extra consultants for use, and a multi-token prediction head that generates a number of future tokens per ahead move. These modifications enhance high quality and allow speculative-style acceleration of lengthy textual content and chain-of-thought workloads.
- Effectivity with massive coaching knowledge and NVFP4 accuracy: Nemotron 3 is pre-trained with roughly 25 trillion tokens, together with over 3 trillion new tokens in comparison with the earlier technology, and Tremendous and Extremely are primarily educated on NVFP4 (a 4-bit floating level format for NVIDIA GPUs). This mix will increase throughput and reduces reminiscence utilization whereas bringing accuracy nearer to plain precision.
Please verify paper, technology blog and Model weights in HF. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Additionally, be at liberty to comply with us Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information that’s technically sound and simply understood by a large viewers. The platform boasts over 2 million views monthly, which exhibits its recognition amongst viewers.

{kind=link}