


This weblog publish introduces the brand new Amazon Nova mannequin analysis options in Amazon SageMaker AI. This launch provides {custom} metrics help, LLM-based desire testing, log likelihood seize, metadata evaluation, and multi-node scaling for big evaluations.
The brand new options embrace:
- Customized metrics use the convey your personal metrics (BYOM) features to regulate analysis standards on your use case.
- Nova LLM-as-a-Decide handles subjective evaluations via pairwise A/B comparisons, reporting win/tie/loss ratios and Bradley-Terry scores with explanations for every judgment.
- Token-level log possibilities reveal mannequin confidence, helpful for calibration and routing selections.
- Metadata passthrough retains per-row fields for evaluation by buyer phase, area, issue, or precedence stage with out additional processing.
- Multi-node execution distributes workloads whereas sustaining steady aggregation, scaling analysis datasets from 1000’s to tens of millions of examples.
In SageMaker AI, groups can outline mannequin evaluations utilizing JSONL information in Amazon Easy Storage Service (Amazon S3), then execute them as SageMaker coaching jobs with management over pre- and post-processing workflows with outcomes delivered as structured JSONL with per-example and aggregated metrics and detailed metadata. Groups can then combine outcomes with analytics instruments like Amazon Athena and AWS Glue, or immediately route them into present observability stacks, with constant outcomes.
The remainder of this publish introduces the brand new options after which demonstrates step-by-step easy methods to arrange evaluations, run decide experiments, seize and analyze log possibilities, use metadata for evaluation, and configure multi-node runs in an IT help ticket classification instance.
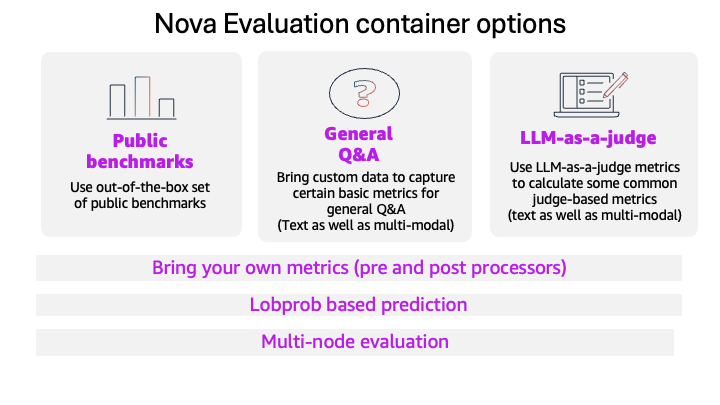
Options for mannequin analysis utilizing Amazon SageMaker AI
When selecting which fashions to convey into manufacturing, correct analysis methodologies require testing a number of fashions, together with custom-made variations in SageMaker AI. To take action successfully, groups want an identical check circumstances passing the identical prompts, metrics, and analysis logic to completely different fashions. This makes positive rating variations replicate mannequin efficiency, not analysis strategies.
Amazon Nova fashions which might be custom-made in SageMaker AI now inherit the total analysis infrastructure as base fashions making it a good comparability. Outcomes land as structured JSONL in Amazon S3, prepared for Athena queries or routing to your observability stack. Let’s focus on a few of the new options out there for mannequin analysis.
Convey your personal metrics (BYOM)
Normal metrics won’t all the time suit your particular necessities. Customized metrics options leverage AWS Lambda features to deal with information preprocessing, output post-processing, and metric calculation. As an example, a customer support bot wants empathy and model consistency metrics; a medical assistant may require medical accuracy measures. With {custom} metrics, you may check what issues on your area.
On this characteristic, pre- and post-processor features are encapsulated in a Lambda perform that’s used to course of information earlier than inference to normalize codecs or inject context and to then calculate your {custom} metrics utilizing post-processing perform after the mannequin responds. Lastly, the outcomes are aggregated utilizing your alternative of min, max, common, or sum, thereby providing higher flexibility when completely different check examples carry various significance.
Multimodal LLM-as-a-judge analysis
LLM-as-a-judge automates desire testing for textual content in addition to multimodal duties utilizing Amazon Nova LLM-as-a-Decide fashions for response comparability. The system implements pairwise analysis: for every immediate, it compares baseline and challenger responses, working the comparability in each ahead and backward passes to detect positional bias. The output consists of Bradley-Terry possibilities (the probability one response is most well-liked over one other) with bootstrap-sampled confidence intervals, giving statistical confidence in desire outcomes.
Nova LLM-as-a-Decide fashions are purposefully custom-made for judging associated analysis duties. Every judgment consists of pure language rationales explaining why the decide most well-liked one response over different, serving to with focused enhancements slightly than blind optimization. Nova LLM-as-a-Decide evaluates advanced reasoning duties like help ticket classification, the place nuanced understanding issues greater than easy key phrase matching.
The tie detection is equally useful, figuring out the place fashions have reached parity. Mixed with customary error metrics, you may decide whether or not efficiency variations are statistically significant or inside noise margins; that is necessary when deciding if a mannequin replace justifies deployment.
Use log likelihood for mannequin analysis
Log possibilities present mannequin confidence for every generated token, revealing insights into mannequin uncertainty and prediction high quality. Log possibilities help calibration research, confidence routing, and hallucination detection past primary accuracy. Token-level confidence helps determine unsure predictions for extra dependable methods.
A Nova analysis container with SageMaker AI mannequin analysis now captures token-level log possibilities throughout inference for uncertainty-aware analysis workflows. The characteristic integrates with analysis pipelines and supplies the muse for superior diagnostic capabilities. You possibly can correlate mannequin confidence with precise efficiency, implement high quality gates based mostly on uncertainty thresholds, and detect potential points earlier than they affect manufacturing methods. Add log likelihood seize by including the top_logprobs parameter to your analysis configuration:
When mixed with the metadata passthrough characteristic as mentioned within the subsequent part, log possibilities assist with stratified confidence evaluation throughout completely different information segments and use instances. This mix supplies detailed insights into mannequin habits, so groups can perceive not simply the place fashions fail, however why they fail and the way assured they’re of their predictions giving them extra management over calibration.
Go metadata info when utilizing mannequin analysis
Customized datasets now help metadata fields when getting ready the analysis dataset. Metadata helps evaluate outcomes throughout completely different fashions and datasets. The metadata subject accepts any string for tagging and evaluation with the enter information and eval outcomes. With the addition of the metadata subject, the general schema per information level in JSONL file turns into the next:
Allow multi-node analysis
The analysis container helps multi-node analysis for quicker processing. Set the replicas parameter to allow multi-node analysis to a worth higher than one.
Case research: IT help ticket classification assistant
The next case research demonstrates a number of of those new options utilizing IT help ticket classification. On this use case, fashions classify tickets as {hardware}, software program, community, or entry points whereas explaining their reasoning. This checks each accuracy and clarification high quality, and reveals {custom} metrics, metadata passthrough, log likelihood evaluation, and multi-node scaling in apply.
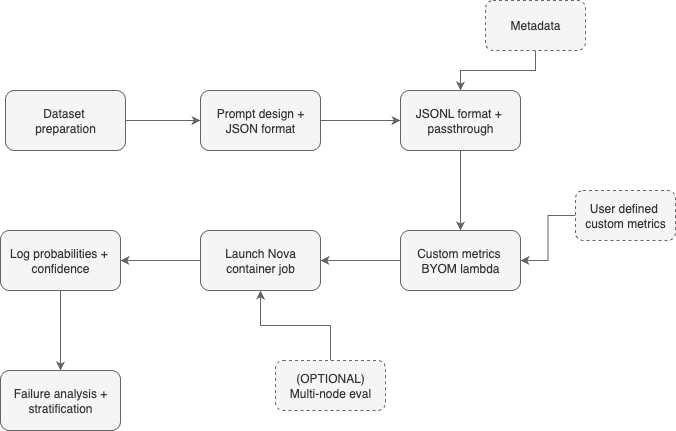
Dataset overview
The help ticket classification dataset comprises IT help tickets spanning completely different precedence ranges and technical domains, every with structured metadata for detailed evaluation. Every analysis instance features a help ticket question, the system context, a structured response containing the anticipated class, the reasoning based mostly on ticket content material, and a pure language description. Amazon SageMaker Floor Fact responses embrace considerate explanations like Based mostly on the error message mentioning community timeout and the consumer's description of intermittent connectivity, this seems to be a community infrastructure situation requiring escalation to the community staff. The dataset consists of metadata tags for issue stage (straightforward/medium/exhausting based mostly on technical complexity), precedence (low/medium/excessive), and area class, demonstrating how metadata passthrough works for stratified evaluation with out post-processing joins.
Stipulations
Earlier than you run the pocket book, make certain the provisioned atmosphere has the next:
- An AWS account
- AWS Id and Entry Administration (IAM) permissions to create a Lambda perform, the flexibility to run SageMaker coaching jobs inside the related AWS account within the earlier step, and skim and write permissions to an S3 bucket
- A growth atmosphere with SageMaker Python SDK and the Nova {custom} analysis SDK (
nova_custom_evaluation_sdk)
Step 1: Put together the immediate
For our help ticket classification activity, we have to assess not solely whether or not the mannequin identifies the right class, but additionally whether or not it supplies coherent reasoning and adheres to structured output codecs to have a whole overview required in manufacturing methods. For crafting the immediate, we’re going to use Nova prompting greatest practices.
System immediate design: Beginning with the system immediate, we set up the mannequin’s position and anticipated habits via a centered system immediate:
This immediate units clear expectations: the mannequin ought to act as a website knowledgeable, base selections on visible proof, and prioritize accuracy. By framing the duty as knowledgeable evaluation slightly than informal remark, we encourage extra considerate, detailed responses.
Question construction: The question template requests each classification and justification:
The express request for reasoning is necessary—it forces the mannequin to articulate its decision-making course of, serving to with analysis of clarification high quality alongside classification accuracy. This mirrors real-world necessities the place mannequin selections usually must be interpretable for stakeholders or regulatory compliance.
Structured response format: We outline the anticipated output as JSON with three elements:
This construction helps the three-dimensional analysis technique we’ll focus on later on this publish:
- class subject – Classification accuracy metrics (precision, recall, F1)
- thought subject – Reasoning coherence analysis
- description subject – Pure language high quality evaluation
By defining the response as parseable JSON, we assist with automated metric calculation via our {custom} Lambda features whereas sustaining human-readable explanations for mannequin selections. This immediate structure transforms analysis from easy proper/fallacious classification into a whole evaluation of mannequin capabilities. Manufacturing AI methods must be correct, explainable, and dependable of their output formatting—and our immediate design explicitly checks all three dimensions. The structured format additionally facilitates the metadata-driven stratified evaluation we’ll use in later steps, the place we will correlate reasoning high quality with confidence scores and issue ranges throughout completely different breed classes.
Step 2: Put together the dataset for analysis with metadata
On this step, we’ll put together our help ticket dataset with metadata help to assist with stratified evaluation throughout completely different classes and issue ranges. The metadata passthrough characteristic retains {custom} fields full for detailed efficiency evaluation with out post-hoc joins. Let’s evaluate an instance dataset.
Dataset schema with metadata
For our help ticket classification analysis, we’ll use the improved gen_qa format with structured metadata:
Look at this additional: how will we mechanically generate structured metadata for every analysis instance? This metadata enrichment course of analyzes the content material to categorise activity sorts, assess issue ranges, and determine domains, creating the muse for stratified evaluation in later steps. By embedding this contextual info immediately into our dataset, we assist the Nova analysis pipeline hold these insights full, so we will perceive mannequin efficiency throughout completely different segments with out requiring advanced post-processing joins.
As soon as our dataset is enriched with metadata, we have to export it within the JSONL format required by the Nova analysis container.
The next export perform codecs our ready examples with embedded metadata in order that they’re prepared for the analysis pipeline, sustaining the precise schema construction wanted for the Amazon SageMaker processing workflow:
Step 3: Put together {custom} metrics to judge {custom} fashions
After getting ready and verifying your information adheres to the required schema, the subsequent necessary step is to develop analysis metrics code to evaluate your {custom} mannequin’s efficiency. Use Nova analysis container and the convey your personal metric (BYOM) workflow to regulate your mannequin analysis pipeline with {custom} metrics and information workflows.
Introduction to BYOM workflow
With the BYOM characteristic, you may tailor your mannequin analysis workflow to your particular wants with totally customizable pre-processing, post-processing, and metrics capabilities. BYOM offers you management over the analysis course of, serving to you to fine-tune and enhance your mannequin’s efficiency metrics based on your undertaking’s distinctive necessities.
Key duties for this classification downside
- Outline duties and metrics: On this use case, mannequin analysis requires three duties:
- Class prediction accuracy: This may assess how precisely the mannequin predicts the right class for given inputs. For this we’ll use customary metrics resembling accuracy, precision, recall, and F1 rating to quantify efficiency.
- Schema adherence: Subsequent, we additionally need to make sure that the mannequin’s outputs conform to the desired schema. This step is necessary for sustaining consistency and compatibility with downstream functions. For this we’ll use validation strategies to confirm that the output format matches the required schema.
- Thought course of coherence: Subsequent, we additionally need to consider the coherence and reasoning behind the mannequin’s selections. This includes analyzing the mannequin’s thought course of to assist validate predictions are logically sound. Strategies resembling consideration mechanisms, interpretability instruments, and mannequin explanations can present insights into the mannequin’s decision-making course of.
The BYOM characteristic for evaluating {custom} fashions requires constructing a Lambda perform.
- Configure a {custom} layer in your Lambda perform. Within the GitHub release, discover and obtain the pre-built nova-custom-eval-layer.zip file.
- Use the next command to add the {custom} Lambda layer:
- Add the printed layer and
AWSLambdaPowertoolsPythonV3-python312-arm64(or comparable AWS layer based mostly on Python model and runtime model compatibility) to your Lambda perform to make sure all vital dependencies are put in. - For growth of the Lambda perform, import two key dependencies: one for importing the preprocessor and postprocessor decorators and one to construct the
lambda_handler:
- Add the preprocessor and postprocessor logic.
- Preprocessor logic: Implement features that manipulate the info earlier than it’s handed to the inference server. This may embrace immediate manipulations or different information preprocessing steps. The pre-processor expects an occasion dictionary (dict), a sequence of key worth pairs, as enter:
Instance:
- Postprocessor logic: Implement features that course of the inference outcomes. This may contain parsing fields, including {custom} validations, or calculating particular metrics. The postprocessor expects an occasion dict as enter which has this format:
- Preprocessor logic: Implement features that manipulate the info earlier than it’s handed to the inference server. This may embrace immediate manipulations or different information preprocessing steps. The pre-processor expects an occasion dictionary (dict), a sequence of key worth pairs, as enter:
- Outline the Lambda handler, the place you add the pre-processor and post-processor logics, earlier than and after inference respectively.
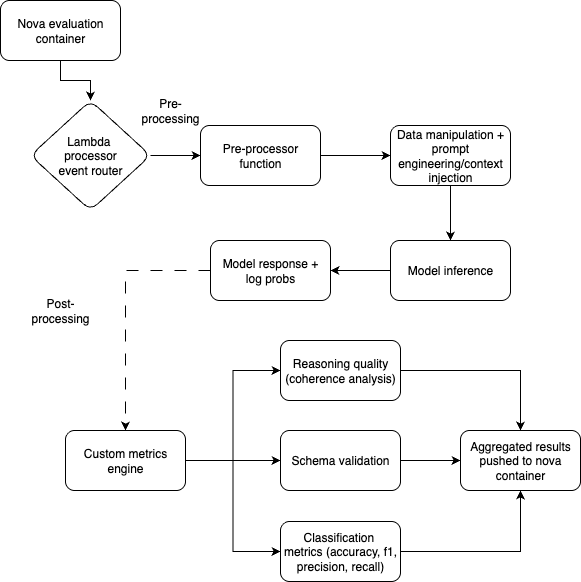
Step 4: Launch the analysis job with {custom} metrics
Now that you’ve constructed your {custom} processors and encoded your analysis metrics, you may select a recipe and make vital changes to ensure the earlier BYOM logic will get executed. For this, first select bring your own data recipes from the general public repo, and ensure the next code adjustments are made.
- Guarantee that the processor secret’s added on to the recipe with right particulars:
- lambda-arn: The Amazon Useful resource Identify (ARN) for a buyer Lambda perform that handles pre-processing and post-processing
- preprocessing: Whether or not so as to add {custom} pre-processing operations
- post-processing: Whether or not so as to add {custom} post-processing operations
- aggregation: In-built aggregation perform to select from.
min, max, common, or sum
- Launch a coaching job with an analysis container:
Step 5: Use metadata and log possibilities to calibrate the accuracy
You may as well embrace log likelihood as an inference config variable to assist conduct logit-based evaluations. For this we will cross top_logprobs beneath inference within the recipe:
top_logprobs signifies the variety of most certainly tokens to return at every token place every with an related log likelihood. This worth have to be an integer from 0 to twenty. Logprobs comprise the thought of output tokens and log possibilities of every output token returned within the content material of message.
As soon as the job runs efficiently and you’ve got the outcomes, you could find the log possibilities beneath the sector pred_logprobs. This subject comprises the thought of output tokens and log possibilities of every output token returned within the content material of message. Now you can use the logits produced to do calibration on your classification activity. The log possibilities of every output token may be helpful for calibration, to regulate the predictions and deal with these possibilities as confidence rating.
Step 6: Failure evaluation on low confidence prediction
After calibrating our mannequin utilizing metadata and log possibilities, we will now determine and analyze failure patterns in low-confidence predictions. This evaluation helps us perceive the place our mannequin struggles and guides focused enhancements.
Loading outcomes with log possibilities
Now, let’s look at intimately how we mix the inference outputs with detailed log likelihood information from the Amazon Nova analysis pipeline. This helps us carry out confidence-aware failure evaluation by merging the prediction outcomes with token-level uncertainty info.
Generate a confidence rating from log possibilities by changing the logprobs to possibilities and utilizing the rating of the primary token within the classification response. We solely use the primary token as we all know subsequent tokens within the classification would align the category label. This step creates downstream high quality gates through which we might route low confidence scores to human evaluate, have a view into mannequin uncertainty to validate if the mannequin is “guessing,” stopping hallucinations from reaching customers, and later permits stratified evaluation.
Preliminary evaluation
Subsequent, we carry out stratified failure evaluation, which mixes confidence scores with metadata classes to determine particular failure patterns. This multi-dimensional evaluation reveals failure modes throughout completely different activity sorts, issue ranges, and domains. Stratified failure evaluation systematically examines low-confidence predictions to determine particular patterns and root causes. It first filters predictions under the arrogance threshold, then conducts multi-dimensional evaluation throughout metadata classes to pinpoint the place the mannequin struggles most. We additionally analyze content material patterns in failed predictions, searching for uncertainty language and categorizing error sorts (JSON format points, size issues, or content material errors) earlier than producing insights that inform groups precisely what to repair.
Preview preliminary outcomes
Now let’s evaluate our preliminary outcomes displaying what was parsed out.
Step 7: Scale the evaluations on multi-node prediction
After figuring out failure patterns, we have to scale our analysis to bigger datasets for testing. Nova analysis containers now help multi-node analysis to enhance throughput and pace by configuring the variety of replicas wanted within the recipe.
The Nova analysis container handles multi-node scaling mechanically whenever you specify multiple reproduction in your analysis recipe. Multi-node scaling distributes the workload throughout a number of nodes whereas sustaining the identical analysis high quality and metadata passthrough capabilities.
Outcome aggregation and efficiency evaluation
The Nova analysis container mechanically handles outcome aggregation from a number of replicas, however we will analyze the scaling effectiveness and restrict metadata-based evaluation to the distributed analysis.
Multi-node analysis makes use of the Nova analysis container’s built-in capabilities via the replicas parameter, distributing workloads mechanically and aggregating outcomes whereas holding all metadata-based stratified evaluation capabilities. The container handles the complexity of distributed processing, serving to groups to scale from 1000’s to tens of millions of examples by rising the reproduction rely.
Conclusion
This instance demonstrated Nova mannequin analysis fundamentals exhibiting the capabilities of recent characteristic releases for the Nova analysis container. We confirmed how us utilization of {custom} metrics (BYOM) with domain-specific assessments can drive deep insights. Then defined easy methods to extract and use log possibilities to disclose mannequin uncertainty easing the implementation of high quality gates and confidence-based routing. Then confirmed how the metadata passthrough functionality is used downstream for stratified evaluation, pinpointing the place fashions battle and the place to focus enhancements. We then recognized a easy strategy to scale these methods with multi-node analysis capabilities. Together with these options in your analysis pipeline may help you make knowledgeable selections on which fashions to undertake and the place customization needs to be utilized.
Get began now with the Nova evaluation demo notebook which has detailed executable code for every step above, from dataset preparation via failure evaluation, providing you with a baseline to change so you may consider your personal use case.
Try the Amazon Nova Samples repository for full code examples throughout quite a lot of use instances.
In regards to the authors
 Tony Santiago is a Worldwide Companion Options Architect at AWS, devoted to scaling generative AI adoption throughout International Techniques Integrators. He makes a speciality of answer constructing, technical go-to-market alignment, and functionality growth—enabling tens of 1000’s of builders at GSI companions to ship AI-powered options for his or her clients. Drawing on greater than 20 years of world know-how expertise and a decade with AWS, Tony champions sensible applied sciences that drive measurable enterprise outcomes. Outdoors of labor, he’s keen about studying new issues and spending time with household.
Tony Santiago is a Worldwide Companion Options Architect at AWS, devoted to scaling generative AI adoption throughout International Techniques Integrators. He makes a speciality of answer constructing, technical go-to-market alignment, and functionality growth—enabling tens of 1000’s of builders at GSI companions to ship AI-powered options for his or her clients. Drawing on greater than 20 years of world know-how expertise and a decade with AWS, Tony champions sensible applied sciences that drive measurable enterprise outcomes. Outdoors of labor, he’s keen about studying new issues and spending time with household.
 Akhil Ramaswamy is a Worldwide Specialist Options Architect at AWS, specializing in superior mannequin customization and inference on SageMaker AI. He companions with international enterprises throughout numerous industries to resolve advanced enterprise issues utilizing the AWS generative AI stack. With experience in constructing production-grade agentic methods, Akhil focuses on growing scalable go-to-market options that assist enterprises drive innovation whereas maximizing ROI. Outdoors of labor, you could find him touring, figuring out, or having fun with a pleasant e-book.
Akhil Ramaswamy is a Worldwide Specialist Options Architect at AWS, specializing in superior mannequin customization and inference on SageMaker AI. He companions with international enterprises throughout numerous industries to resolve advanced enterprise issues utilizing the AWS generative AI stack. With experience in constructing production-grade agentic methods, Akhil focuses on growing scalable go-to-market options that assist enterprises drive innovation whereas maximizing ROI. Outdoors of labor, you could find him touring, figuring out, or having fun with a pleasant e-book.
 Anupam Dewan is a Senior Options Architect working in Amazon Nova staff with a ardour for generative AI and its real-world functions. He focuses on constructing, enabling, and benchmarking AI functions for GenAI clients in Amazon. With a background in AI/ML, information science, and analytics, Anupam helps clients study and make Amazon Nova work for his or her GenAI use instances to ship enterprise outcomes. Outdoors of labor, you could find him mountain climbing or having fun with nature.
Anupam Dewan is a Senior Options Architect working in Amazon Nova staff with a ardour for generative AI and its real-world functions. He focuses on constructing, enabling, and benchmarking AI functions for GenAI clients in Amazon. With a background in AI/ML, information science, and analytics, Anupam helps clients study and make Amazon Nova work for his or her GenAI use instances to ship enterprise outcomes. Outdoors of labor, you could find him mountain climbing or having fun with nature.

{kind=link}