


This submit was written with Martyna Shallenberg and Brode Mccrady from Myriad Genetics.
Healthcare organizations face challenges in processing and managing excessive volumes of complicated medical documentation whereas sustaining high quality in affected person care. These organizations want options to course of paperwork successfully to fulfill rising calls for. Myriad Genetics, a supplier of genetic testing and precision medication options serving healthcare suppliers and sufferers worldwide, addresses this problem.
Myriad’s Income Engineering Division processes 1000’s of healthcare paperwork each day throughout Girls’s Well being, Oncology, and Psychological Well being divisions. The corporate classifies incoming paperwork into lessons akin to Take a look at Request Types, Lab Outcomes, Medical Notes, and Insurance coverage to automate Prior Authorization workflows. The system routes these paperwork to applicable exterior distributors for processing primarily based on their recognized doc class. They manually carry out Key Info Extraction (KIE) together with insurance coverage particulars, affected person data, and take a look at outcomes to find out Medicare eligibility and assist downstream processes.
As doc volumes elevated, Myriad confronted challenges with its current system. The automated doc classification resolution labored however was pricey and time-consuming. Info extraction remained handbook attributable to complexity. To deal with excessive prices and sluggish processing, Myriad wanted a greater resolution.
This submit explores how Myriad Genetics partnered with the AWS Generative AI Innovation Heart (GenAIIC) to rework their healthcare doc processing pipeline utilizing Amazon Bedrock and Amazon Nova basis fashions. We element the challenges with their current resolution, and the way generative AI lowered prices and improved processing velocity.
We study the technical implementation utilizing AWS’s open source GenAI Intelligent Document Processing (GenAI IDP) Accelerator solution, the optimization methods used for doc classification and key data extraction, and the measurable enterprise affect on Myriad’s prior authorization workflows. We cowl how we used immediate engineering strategies, mannequin choice methods, and architectural choices to construct a scalable resolution that processes complicated medical paperwork with excessive accuracy whereas decreasing operational prices.
Doc processing bottlenecks limiting healthcare operations
Myriad Genetics’ each day operations depend upon effectively processing complicated medical paperwork containing vital data for affected person care workflows and regulatory compliance. Their current resolution mixed Amazon Textract for Optical Character Recognition (OCR) with Amazon Comprehend for doc classification.
Regardless of 94% classification accuracy, this resolution had operational challenges:
- Operational prices: 3 cents per web page leading to $15,000 month-to-month bills per enterprise unit
- Classification latency: 8.5 minutes per doc, delaying downstream prior authorization workflows
Info extraction was solely handbook, requiring contextual understanding to distinguish vital scientific distinctions (like “is metastatic” versus “is just not metastatic”) and to find data like insurance coverage numbers and affected person data throughout various doc codecs. This processing burden was substantial, with Girls’s Well being customer support requiring as much as 10 full-time workers contributing 78 hours each day within the Girls’s Well being enterprise unit alone.
Myriad wanted an answer to:
- Cut back doc classification prices whereas sustaining or bettering accuracy
- Speed up doc processing to get rid of workflow bottlenecks
- Automate data extraction for medical paperwork
- Scale throughout a number of enterprise items and doc sorts
Amazon Bedrock and generative AI
Trendy giant language fashions (LLMs) course of complicated healthcare paperwork with excessive accuracy attributable to pre-training on huge textual content corpora. This pre-training allows LLMs to know language patterns and doc constructions with out function engineering or giant labeled datasets. Amazon Bedrock is a totally managed service that gives a broad vary of high-performing LLMs from main AI corporations. It supplies the safety, privateness, and accountable AI capabilities that healthcare organizations require when processing delicate medical data. For this resolution, we used Amazon’s latest basis fashions:
- Amazon Nova Professional: An economical, low-latency mannequin superb for doc classification
- Amazon Nova Premier: A sophisticated mannequin with reasoning capabilities for data extraction
Resolution overview
We carried out an answer with Myriad utilizing AWS’s open supply GenAI IDP Accelerator. The accelerator supplies a scalable, serverless structure that converts unstructured paperwork into structured information. The accelerator processes a number of paperwork in parallel by means of configurable concurrency limits with out overwhelming downstream providers. Its built-in evaluation framework lets customers present anticipated output by means of the consumer interface (UI) and consider generated outcomes to iteratively customise configuration and enhance accuracy.
The accelerator provides 1-click deployment with a selection of pre-built patterns optimized for various workloads with completely different configurability, price, and accuracy necessities:
- Pattern 1 – Makes use of Amazon Bedrock Knowledge Automation, a totally managed service that gives wealthy out-of-the-box options, ease of use, and easy per-page pricing. This sample is beneficial for many use instances.
- Pattern 2 – Makes use of Amazon Textract and Amazon Bedrock with Amazon Nova, Anthropic’s Claude, or customized fine-tuned Amazon Nova fashions. This sample is right for complicated paperwork requiring customized logic.
- Pattern 3 – Makes use of Amazon Textract, Amazon SageMaker with a fine-tuned mannequin for classification, and Amazon Bedrock for extraction. This sample is right for paperwork requiring specialised classification.
Sample 2 proved most fitted for this venture, assembly the vital requirement of low price whereas providing flexibility to optimize accuracy by means of immediate engineering and LLM choice. This sample provides a no-code configuration – customise doc sorts, extraction fields, and processing logic by means of configuration, editable within the internet UI.
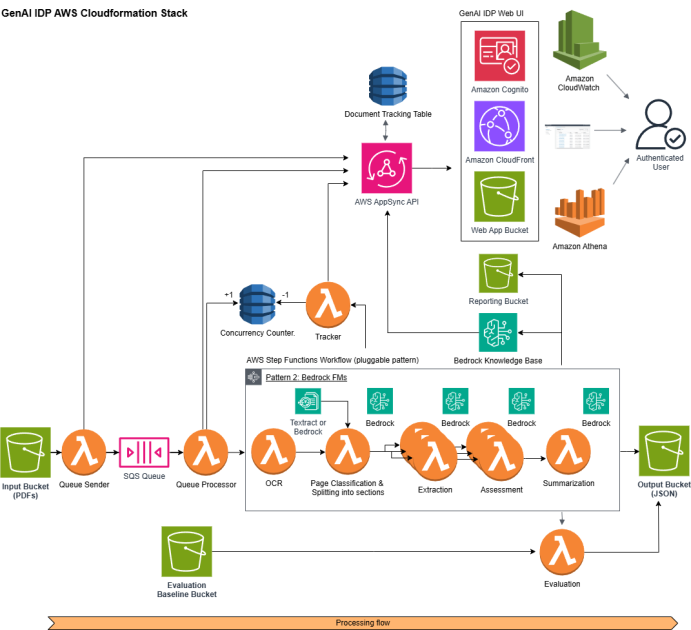
We custom-made the definitions of doc lessons, key attributes and their definitions per doc class, LLM selection, LLM hyperparameters, and classification and extraction LLM prompts by way of Sample 2’s config file. In manufacturing, Myriad built-in this resolution into their current event-driven structure. The next diagram illustrates the manufacturing pipeline:

- Doc Ingestion: Incoming order occasions set off doc retrieval from supply doc administration methods, with cache optimization for beforehand processed paperwork.
- Concurrency Administration: DynamoDB tracked concurrent AWS Step Perform jobs whereas Amazon Easy Queue Service (SQS) queues information exceeding concurrency limits for doc processing.
- Textual content Extraction: Amazon Textract extracted textual content, format data, tables and kinds from the normalized paperwork.
- Classification: The configured LLM analyzed the extracted content material primarily based on the custom-made doc classification immediate supplied within the config file and classifies paperwork into applicable classes.
- Key Info Extraction: The configured LLM extracted medical data utilizing extraction immediate supplied within the config file.
- Structured Output: The pipeline formatted the ends in a structured method and delivered to Myriad’s Authorization System by way of RESTful operations.
Doc classification with generative AI
Whereas Myriad’s current resolution achieved 94% accuracy, misclassifications occurred attributable to structural similarities, overlapping content material, and shared formatting patterns throughout doc sorts. This semantic ambiguity made it troublesome to differentiate between related paperwork. We guided Myriad on immediate optimization strategies that used LLM’s contextual understanding capabilities. This method moved past sample matching to allow semantic evaluation of doc context and goal, figuring out distinguishing options that human specialists acknowledge however earlier automated methods missed.
AI-driven immediate engineering for doc classification
We developed class definitions with distinguishing traits between related doc sorts. To establish these differentiators, we supplied doc samples from every class to Anthropic Claude Sonnet 3.7 on Amazon Bedrock with mannequin reasoning enabled (a function that permits the mannequin to exhibit its step-by-step evaluation course of). The mannequin recognized distinguishing options between related doc lessons, which Myriad’s material specialists refined and included into the GenAI IDP Accelerator’s Pattern 2 config file for doc classification prompts.
Format-based classification methods
We used doc construction and formatting as key differentiators to differentiate between related doc sorts that shared comparable content material however differed in construction. We enabled the classification fashions to acknowledge format-specific traits akin to format constructions, area preparations, and visible parts, permitting the system to distinguish between paperwork that textual content material alone can not distinguish. For instance, lab stories and take a look at outcomes each include affected person data and medical information, however lab stories show numerical values in tabular format whereas take a look at outcomes comply with a story format. We instructed the LLM: “Lab stories include numerical outcomes organized in tables with reference ranges and items. Take a look at outcomes current findings in paragraph format with scientific interpretations.”
Implementing destructive prompting for enhanced accuracy
We carried out destructive prompting strategies to resolve confusion between related paperwork by explicitly instructing the mannequin what classifications to keep away from. This method added exclusionary language to classification prompts, specifying traits that shouldn’t be related to every doc kind. Initially, the system steadily misclassified Take a look at Request Types (TRFs) as Take a look at Outcomes attributable to confusion between affected person medical historical past and lab measurements. Including a destructive immediate like “These kinds include affected person medical historical past. DO NOT confuse them with take a look at outcomes which include present/latest lab measurements” to the TRF definition improved the classification accuracy by 4%. By offering express steering on frequent misclassification patterns, the system averted typical errors and confusion between related doc sorts.
Mannequin choice for price and efficiency optimization
Mannequin choice drives optimum cost-performance at scale, so we performed complete benchmarking utilizing the GenAI IDP Accelerator’s evaluation framework. We examined 4 basis fashions—Amazon Nova Lite, Amazon Nova Professional, Amazon Nova Premier, and Anthropic Claude Sonnet 3.7—utilizing 1,200 healthcare paperwork throughout three doc lessons: Take a look at Request Types, Lab Outcomes, and Insurance coverage. We assessed every mannequin utilizing three vital metrics: classification accuracy, processing latency, and price per doc. The accelerator’s price monitoring enabled direct comparability of operational bills throughout completely different mannequin configurations, making certain efficiency enhancements translate into measurable enterprise worth at scale.
The analysis outcomes demonstrated that Amazon Nova Professional achieved optimum stability for Myriad’s use case. We transitioned from Myriad’s Amazon Comprehend implementation to Amazon Nova Professional with optimized prompts for doc classification, attaining important enhancements: classification accuracy elevated from 94% to 98%, processing prices decreased by 77%, and processing velocity improved by 80%—decreasing classification time from 8.5 minutes to 1.5 minutes per doc.
Automating Key Info Extraction with generative AI
Myriad’s data extraction was handbook, requiring as much as 10 full-time workers contributing 78 hours each day within the Girls’s Well being unit alone, which created operational bottlenecks and scalability constraints. Automating healthcare KIE offered challenges: checkbox fields required distinguishing between marking types (checkmarks, X’s, handwritten marks); paperwork contained ambiguous visible parts like overlapping marks or content material spanning a number of fields; extraction wanted contextual understanding to distinguish scientific distinctions and find data throughout various doc codecs. We labored with Myriad to develop an automatic KIE resolution, implementing the next optimization strategies to handle extraction complexity.
Enhanced OCR configuration for checkbox recognition
To deal with checkbox identification challenges, we enabled Amazon Textract’s specialised TABLES and FORMS options on the GenAI IDP Accelerator portal as proven within the following picture, to enhance OCR discrimination between chosen and unselected checkbox parts. These options enhanced the system’s means to detect and interpret marking types present in medical kinds.
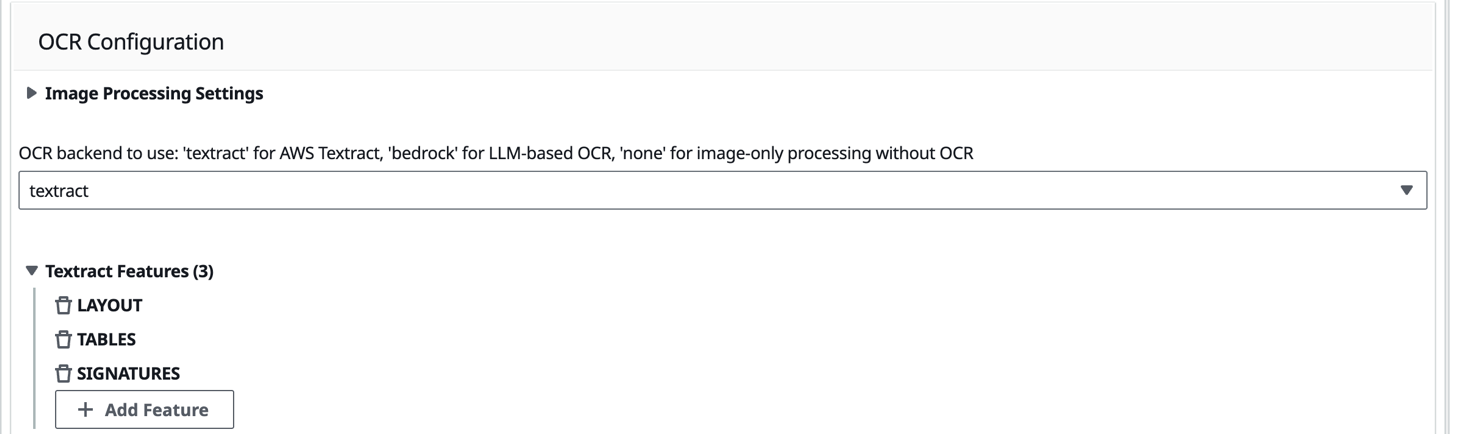
We enhanced accuracy by incorporating visible cues into the extraction prompts. We up to date the prompts with directions akin to “search for seen marks in or across the small sq. containers (✓, x, or handwritten marks)” to information the language mannequin in figuring out checkbox picks. This mix of enhanced OCR capabilities and focused prompting improved checkbox extraction in medical kinds.
Visible context studying by means of few-shot examples
Configuring Textract and bettering prompts alone couldn’t deal with complicated visible parts successfully. We carried out a multimodal method that despatched each doc pictures and extracted textual content from Textract to the muse mannequin, enabling simultaneous evaluation of visible format and textual content material for correct extraction choices. We carried out few-shot learning by offering instance doc pictures paired with their anticipated extraction outputs to information the mannequin’s understanding of assorted type layouts and marking types. A number of doc picture examples with their right extraction patterns create prolonged LLM prompts. We leveraged the GenAI IDP Accelerator’s built-in integration with Amazon Bedrock’s prompt caching feature to cut back prices and latency. Immediate caching shops prolonged few-shot examples in reminiscence for five minutes—when processing a number of related paperwork inside that timeframe, Bedrock reuses cached examples as an alternative of reprocessing them, decreasing each price and processing time.
Chain of thought reasoning for complicated extraction
Whereas this multimodal method improved extraction accuracy, we nonetheless confronted challenges with overlapping and ambiguous tick marks in complicated type layouts. To carry out properly in ambiguous and sophisticated conditions, we used Amazon Nova Premier and carried out Chain of Thought reasoning to have the mannequin suppose by means of extraction choices step-by-step utilizing considering tags. For instance:
Moreover, we included reasoning explanations within the few-shot examples, demonstrating how we reached conclusions in ambiguous instances. This method enabled the mannequin to work by means of complicated visible proof and contextual clues earlier than making ultimate determinations, bettering efficiency with ambiguous tick marks.
Testing throughout 32 doc samples with various complexity ranges by way of the GenAI IDP Accelerator revealed that Amazon Textract with Structure, TABLES, and FORMS options enabled, paired with Amazon Nova Premier’s superior reasoning capabilities and the inclusion of few-shot examples, delivered one of the best outcomes. The answer achieved 90% accuracy (identical as human evaluator baseline accuracy) whereas processing paperwork in roughly 1.3 minutes every.
Outcomes and enterprise affect
Via our new resolution, we delivered measurable enhancements that met the enterprise targets established on the venture outset:
Doc classification efficiency:
- We elevated accuracy from 94% to 98% by means of immediate optimization strategies for Amazon Nova Professional, together with AI-driven immediate engineering, document-format primarily based classification methods, and destructive prompting.
- We lowered classification prices by 77% (from 3.1 to 0.7 cents per web page) by migrating from Amazon Comprehend to Amazon Nova Professional with optimized prompts.
- We lowered classification time by 80% (from 8.5 to 1.5 minutes per doc) by selecting Amazon Nova Professional to supply a low-latency and cost-effective resolution.
New automated Key Info Extraction efficiency:
- We achieved 90% extraction accuracy (identical because the baseline handbook course of): Delivered by means of a mixture of Amazon Textract’s doc evaluation capabilities, visible context studying by means of few-shot examples and Amazon Nova Premier’s reasoning for complicated information interpretation.
- We achieved processing prices of 9 cents per web page and processing time of 1.3 minutes per doc in comparison with handbook baseline requiring as much as 10 full-time workers working 78 hours each day per enterprise unit.
Enterprise affect and rollout
Myriad has deliberate a phased rollout starting with doc classification. They plan to launch our new classification resolution within the Girls’s Well being enterprise unit, adopted by Oncology and Psychological Well being divisions. Because of our work, Myriad will understand as much as $132K in annual financial savings of their doc classification prices. The answer reduces every prior authorization submission time by 2 minutes—specialists now full orders in 4 minutes as an alternative of six minutes attributable to quicker entry to tagged paperwork. This enchancment saves 300 hours month-to-month throughout 9,000 prior authorizations in Girls’s Well being alone, equal to 50 hours per prior authorization specialist.
These measurable enhancements have remodeled Myriad’s operations, as their engineering management confirms:
“Partnering with the GenAIIC emigrate our Clever Doc Processing resolution from AWS Comprehend to Bedrock has been a transformative step ahead. By bettering each efficiency and accuracy, the answer is projected to ship financial savings of greater than $10,000 per thirty days. The staff’s shut collaboration with Myriad’s inner engineering staff delivered a high-quality, scalable resolution, whereas their deep experience in superior language fashions has elevated our capabilities. This has been a wonderful instance of how innovation and partnership can drive measurable enterprise affect.”
– Martyna Shallenberg, Senior Director of Software program Engineering, Myriad Genetics
Conclusion
The AWS GenAI IDP Accelerator enabled Myriad’s speedy implementation, offering a versatile framework that lowered improvement time. Healthcare organizations want tailor-made options—the accelerator delivers in depth customization capabilities that permit customers adapt options to particular doc sorts and workflows with out requiring in depth code adjustments or frequent redeployment throughout improvement. Our method demonstrates the facility of strategic immediate engineering and mannequin choice. We achieved excessive accuracy in a specialised area by specializing in immediate design, together with destructive prompting and visible cues. We optimized each price and efficiency by deciding on Amazon Nova Professional for classification and Nova Premier for complicated extraction—matching the fitting mannequin to every particular process.
Discover the answer for your self
Organizations trying to enhance their doc processing workflows can expertise these advantages firsthand. The open supply GenAI IDP Accelerator that powered Myriad’s transformation is offered to deploy and take a look at in your surroundings. The accelerator’s easy setup course of lets customers rapidly consider how generative AI can rework doc processing challenges.
When you’ve explored the accelerator and seen its potential affect in your workflows, attain out to the AWS GenAIIC staff to discover how the GenAI IDP Accelerator might be custom-made and optimized to your particular use case. This hands-on method ensures you may make knowledgeable choices about implementing clever doc processing in your group.
Concerning the authors
 Priyashree Roy is a Knowledge Scientist II on the AWS Generative AI Innovation Heart, the place she applies her experience in machine studying and generative AI to develop revolutionary options for strategic AWS prospects. She brings a rigorous scientific method to complicated enterprise challenges, knowledgeable by her PhD in experimental particle physics from Florida State College and postdoctoral analysis on the College of Michigan.
Priyashree Roy is a Knowledge Scientist II on the AWS Generative AI Innovation Heart, the place she applies her experience in machine studying and generative AI to develop revolutionary options for strategic AWS prospects. She brings a rigorous scientific method to complicated enterprise challenges, knowledgeable by her PhD in experimental particle physics from Florida State College and postdoctoral analysis on the College of Michigan.
 Mofijul Islam is an Utilized Scientist II and Tech Lead on the AWS Generative AI Innovation Heart, the place he helps prospects sort out customer-centric analysis and enterprise challenges utilizing generative AI, giant language fashions (LLM), multi-agent studying, code era, and multimodal studying. He holds a PhD in machine studying from the College of Virginia, the place his work targeted on multimodal machine studying, multilingual pure language processing (NLP), and multitask studying. His analysis has been revealed in top-tier conferences like NeurIPS, Worldwide Convention on Studying Representations (ICLR), Empirical Strategies in Pure Language Processing (EMNLP), Society for Synthetic Intelligence and Statistics (AISTATS), and Affiliation for the Development of Synthetic Intelligence (AAAI), in addition to Institute of Electrical and Electronics Engineers (IEEE) and Affiliation for Computing Equipment (ACM) Transactions.
Mofijul Islam is an Utilized Scientist II and Tech Lead on the AWS Generative AI Innovation Heart, the place he helps prospects sort out customer-centric analysis and enterprise challenges utilizing generative AI, giant language fashions (LLM), multi-agent studying, code era, and multimodal studying. He holds a PhD in machine studying from the College of Virginia, the place his work targeted on multimodal machine studying, multilingual pure language processing (NLP), and multitask studying. His analysis has been revealed in top-tier conferences like NeurIPS, Worldwide Convention on Studying Representations (ICLR), Empirical Strategies in Pure Language Processing (EMNLP), Society for Synthetic Intelligence and Statistics (AISTATS), and Affiliation for the Development of Synthetic Intelligence (AAAI), in addition to Institute of Electrical and Electronics Engineers (IEEE) and Affiliation for Computing Equipment (ACM) Transactions.
 Nivedha Balakrishnan is a Deep Studying Architect II on the AWS Generative AI Innovation Heart, the place she helps prospects design and deploy generative AI functions to resolve complicated enterprise challenges. Her experience spans giant language fashions (LLMs), multimodal studying, and AI-driven automation. She holds a Grasp’s in Utilized Knowledge Science from San Jose State College and a Grasp’s in Biomedical Engineering from Linköping College, Sweden. Her earlier analysis targeted on AI for drug discovery and healthcare functions, bridging life sciences with machine studying.
Nivedha Balakrishnan is a Deep Studying Architect II on the AWS Generative AI Innovation Heart, the place she helps prospects design and deploy generative AI functions to resolve complicated enterprise challenges. Her experience spans giant language fashions (LLMs), multimodal studying, and AI-driven automation. She holds a Grasp’s in Utilized Knowledge Science from San Jose State College and a Grasp’s in Biomedical Engineering from Linköping College, Sweden. Her earlier analysis targeted on AI for drug discovery and healthcare functions, bridging life sciences with machine studying.
 Martyna Shallenberg is a Senior Director of Software program Engineering at Myriad Genetics, the place she leads cross-functional groups in constructing AI-driven enterprise options that rework income cycle operations and healthcare supply. With a novel background spanning genomics, molecular diagnostics, and software program engineering, she has scaled revolutionary platforms starting from Clever Doc Processing (IDP) to modular LIMS options. Martyna can also be the Founder & President of BioHive’s HealthTech Hub, fostering cross-domain collaboration to speed up precision medication and healthcare innovation.
Martyna Shallenberg is a Senior Director of Software program Engineering at Myriad Genetics, the place she leads cross-functional groups in constructing AI-driven enterprise options that rework income cycle operations and healthcare supply. With a novel background spanning genomics, molecular diagnostics, and software program engineering, she has scaled revolutionary platforms starting from Clever Doc Processing (IDP) to modular LIMS options. Martyna can also be the Founder & President of BioHive’s HealthTech Hub, fostering cross-domain collaboration to speed up precision medication and healthcare innovation.
 Brode Mccrady is a Software program Engineering Supervisor at Myriad Genetics, the place he leads initiatives in AI, income methods, and clever doc processing. With over a decade of expertise in enterprise intelligence and strategic analytics, Brode brings deep experience in translating complicated enterprise wants into scalable technical options. He holds a level in Economics, which informs his data-driven method to problem-solving and enterprise technique.
Brode Mccrady is a Software program Engineering Supervisor at Myriad Genetics, the place he leads initiatives in AI, income methods, and clever doc processing. With over a decade of expertise in enterprise intelligence and strategic analytics, Brode brings deep experience in translating complicated enterprise wants into scalable technical options. He holds a level in Economics, which informs his data-driven method to problem-solving and enterprise technique.
 Randheer Gehlot is a Principal Buyer Options Supervisor at AWS who makes a speciality of healthcare and life sciences transformation. With a deep concentrate on AI/ML functions in healthcare, he helps enterprises design and implement environment friendly cloud options that tackle actual enterprise challenges. His work includes partnering with organizations to modernize their infrastructure, allow innovation, and speed up their cloud adoption journey whereas making certain sensible, sustainable outcomes.
Randheer Gehlot is a Principal Buyer Options Supervisor at AWS who makes a speciality of healthcare and life sciences transformation. With a deep concentrate on AI/ML functions in healthcare, he helps enterprises design and implement environment friendly cloud options that tackle actual enterprise challenges. His work includes partnering with organizations to modernize their infrastructure, allow innovation, and speed up their cloud adoption journey whereas making certain sensible, sustainable outcomes.
Acknowledgements
We wish to thank Bob Strahan, Kurt Mason, Akhil Nooney and Taylor Jensen for his or her important contributions, strategic choices and steering all through.

{kind=link}