


How can groups run trillion-parameter language fashions on present mixed-GPU clusters with out costly new {hardware} or deep vendor lock-in? The analysis group at Perplexity has launched TransferEngine and the encircling pplx backyard toolkit as an open supply infrastructure for large-scale language mannequin methods. This gives a approach to run fashions with as much as 1 trillion parameters throughout blended GPU clusters with out being tied to a single cloud supplier or buying new GB200-class {hardware}.
The actual bottleneck is the community material, not FLOP
Trendy deployments of skilled combine fashions similar to DeepSeek V3 with 671 billion parameters and Kimi K2 with 1 trillion parameters now not match on a single 8 GPU server. The principle constraint is the community material between GPUs, because it must span a number of nodes.
The {hardware} scenario is fragmented right here. NVIDIA ConnectX 7 usually makes use of the Dependable Connection transport, which delivers sequentially. The AWS Elastic Material Adapter makes use of a scalable and dependable datagram transport that’s dependable however defective. Additionally, to succeed in 400 Gbps with one GPU, chances are you’ll want 4 community adapters at 100 Gbps or two community adapters at 200 Gbps.
Present libraries similar to DeepEP, NVSHMEM, MoonCake, and NIXL are typically optimized for one vendor and have lowered or lack of help for the opposite vendor. Perplexity’s analysis group says: research paper Previous to this work, no viable cross-provider resolution for LLM inference existed.
TransferEngine, a transportable RDMA layer for LLM methods
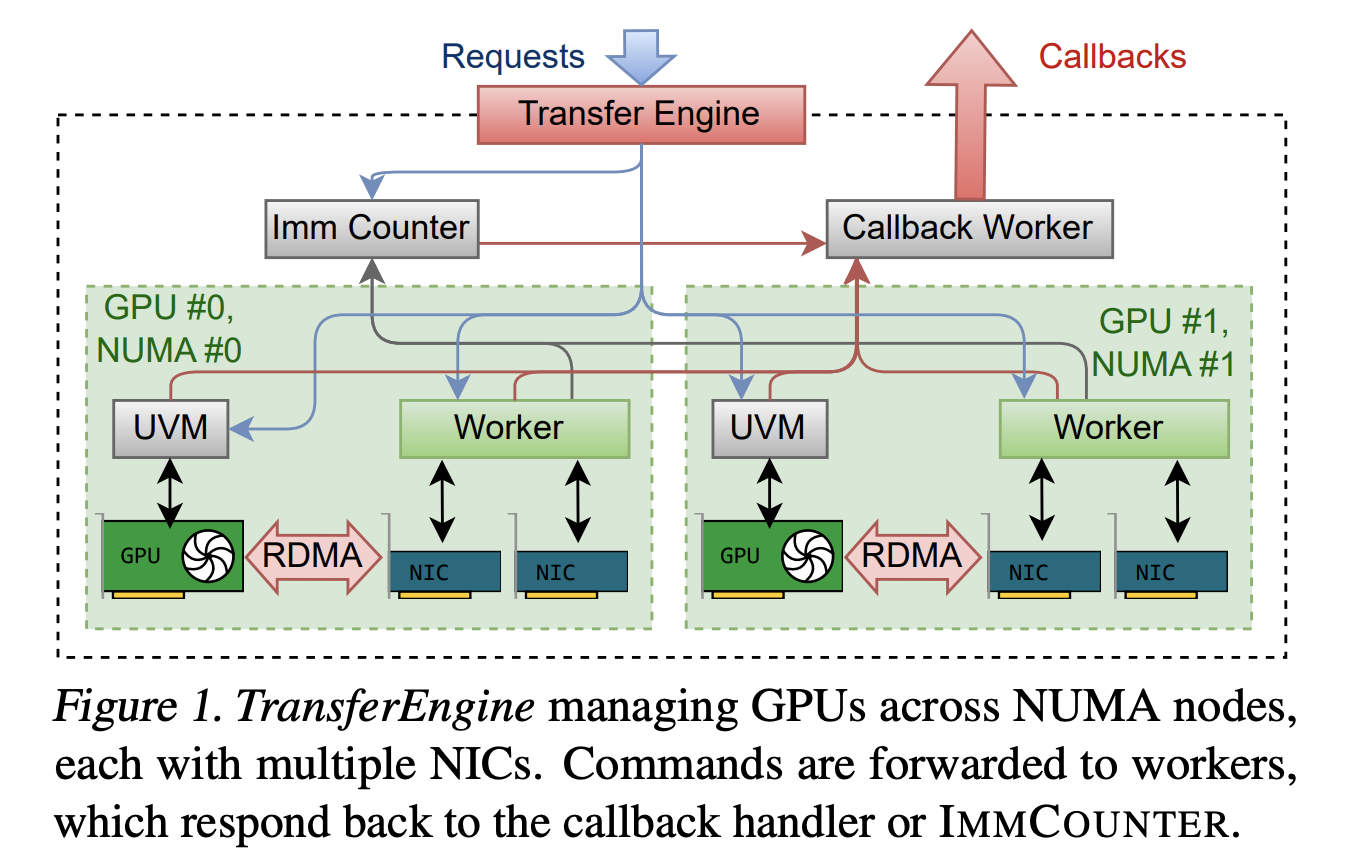
TransferEngine addresses this concern by concentrating on solely the intersection of ensures between community interface controllers. It assumes that the underlying RDMA transport is dependable, however makes no assumptions about message order. Along with this, it exposes a one-sided WriteImm operation and an ImmCounter primitive for completion notification.
of library Gives a minimal API in Rust. Gives two-sided sending and receiving of management messages, in addition to three main single-sided operations. submit_single_write, submit_paged_writesand submit_scatter,plus submit_barrier Primitives for synchronizing throughout teams of friends. The NetAddr construction identifies the peer and the MrDesc construction describes the registered reminiscence space. The alloc_uvm_watcher name creates a device-side watcher for CPU-GPU synchronization in superior pipelines.
Internally, TransferEngine spawns one employee thread per GPU and constructs a DomainGroup per GPU that coordinates one to 4 RDMA community interface controllers. A single ConnectX 7 gives 400 Gbps. With EFA, a DomainGroup aggregates 4 community adapters at 100 Gbps or two community adapters at 200 Gbps to succeed in the identical bandwidth. The sharding logic is conscious of all community interface controllers and may break up transfers between them.
Throughout the {hardware}, the researchers report peak throughput of 400 Gbps with each NVIDIA ConnectX 7 and AWS EFA. That is in keeping with a single-platform resolution and ensures that the abstraction layer doesn’t go away behind vital efficiency.

pplx backyard, open supply bundle
TransferEngine is shipped as a part of the pplx backyard repository on GitHub below the MIT license. The listing construction is easy. fabric-lib Accommodates the RDMA TransferEngine library. p2p-all-to-all Implement skilled mixing for all kernels. python-ext Gives Python extension modules from Rust core, python/pplx_garden Accommodates Python bundle code.
System necessities mirror the newest GPU clusters. The Perplexity analysis group recommends Linux kernel 5.12 or later, CUDA 12.8 or later, libfabric, libibverbs, GDRCopy, and RDMA material with GPUDirect RDMA enabled for DMA BUF help. Every GPU requires no less than one devoted RDMA community interface controller.
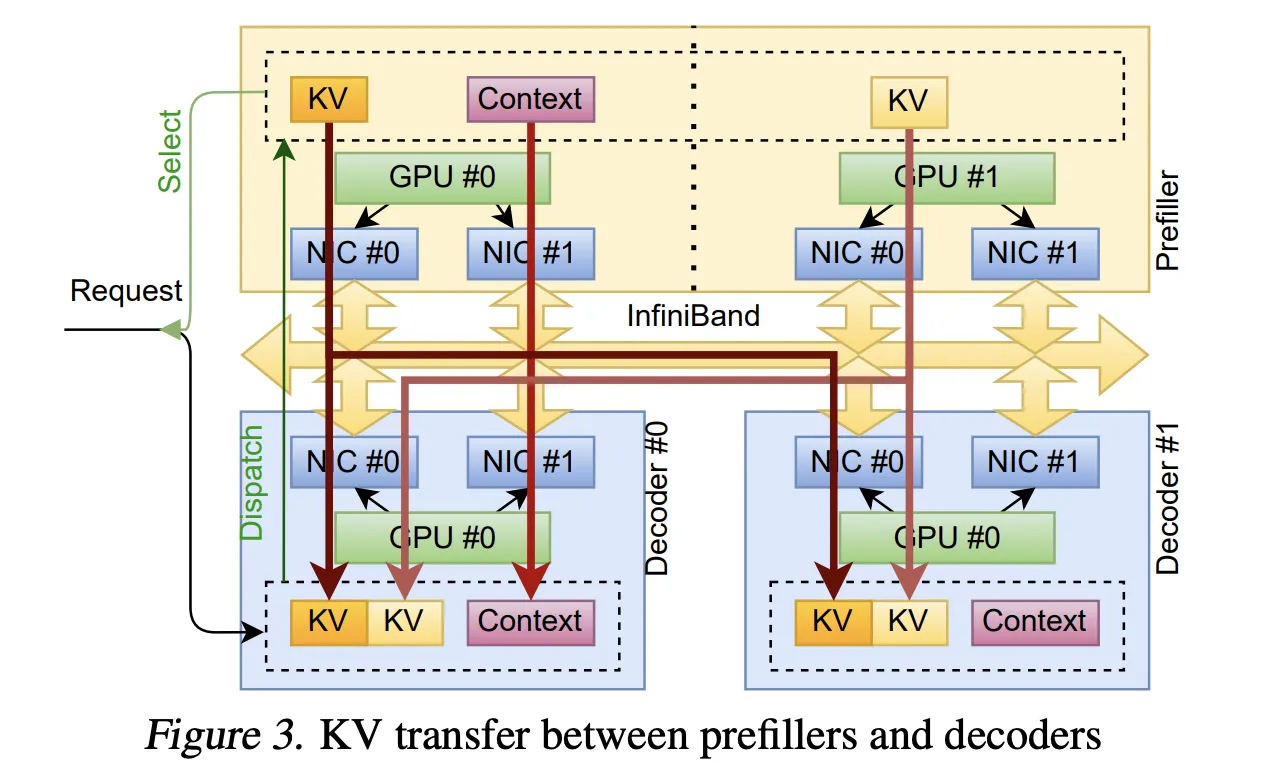
Granular prefill and decoding
of starting Manufacturing use instances are decomposed inferences. As a result of prefill and decode are carried out on separate clusters, the system should stream KvCache from the prefill GPU for quick GPU decoding.
TransferEngine makes use of alloc_uvm_watcher to trace mannequin progress. Throughout prefill, the mannequin will increase the watcher worth after every layer’s consideration output projection. When a employee detects a change, it points a web page write to the KvCache web page for that layer after which a single write to the remainder of the context. This strategy permits layer-by-layer streaming of cache pages with out fixing world membership, and avoids strict ordering constraints on aggregates.
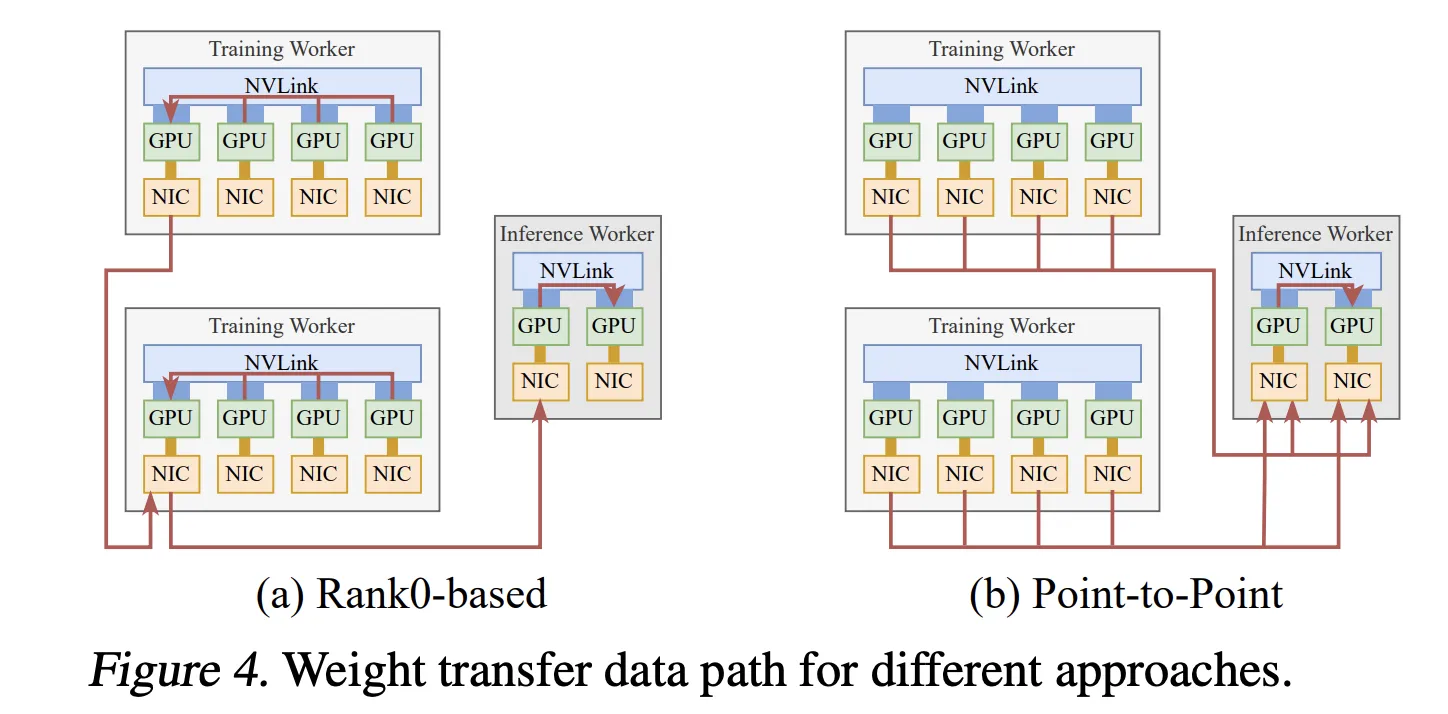
Quick weight switch for reinforcement studying
of Quantity 2 The system is a fine-tuning of asynchronous reinforcement studying, the place coaching and inference are carried out on separate GPU swimming pools. Conventional designs acquire up to date parameters into one rank after which broadcast them, which limits throughput to a single community interface controller.
The Perplexity analysis group as an alternative makes use of TransferEngine to carry out point-to-point weight transfers. Every coaching GPU writes its parameter shard on to its corresponding inference GPU utilizing one-sided writes. Pipeline execution splits every tensor into phases and copies it from the host to the gadget as absolutely sharded knowledge parallel offloads weights, performs reconstruction and elective quantization, RDMA transfers, and boundaries applied by Scatter and ImmCounter.
In manufacturing, this setup gives weight updates for fashions similar to Kim K2 with 1 trillion parameters and DeepSeek V3 with 671 billion parameters in about 1.3 seconds from 256 coaching GPUs to 128 inference GPUs.
Mixture of specialists routing between ConnectX and EFA
of third The pplx backyard half is a combination of point-to-point specialists that dispatch and mix kernels. Use NVLink for intra-node site visitors and RDMA for inter-node site visitors. Dispatch and mix are break up into separate transmit and obtain phases, permitting the decoder to carry out micro-batch and overlap communication with grouped frequent matrix multiplications.
The host proxy thread polls the GPU standing and calls TransferEngine when the ship buffer is prepared. First, routes are exchanged, after which every rank calculates the successive obtain offset for every skilled and writes tokens to a personal buffer that may be reused between dispatch and be a part of. This reduces the reminiscence footprint and maintains sufficient writes to make use of the whole hyperlink bandwidth.
For ConnectX 7, the Perplexity analysis group stories state-of-the-art decoding latencies akin to DeepEP throughout skilled counts. With AWS EFA, the identical kernel gives the primary viable MoE decoding latency with greater however sensible values.
Multi-node testing with DeepSeek V3 and Kim K2 on AWS H200 situations reduces latency at medium batch sizes, a typical regime for manufacturing providers, by distributing fashions throughout nodes.
Comparability desk
| key factors | TransferEngine (pplx backyard) | Deep EP | NVSHMEM (common MoE utilization) | mooncake |
|---|---|---|---|---|
| Primary position | Transportable RDMA point-to-point for LLM methods | We ship and mix every part to MoE All | Frequent GPU shared reminiscence and collectives | Distributed KV cache for LLM inference |
| {Hardware} focus | NVIDIA ConnectX 7 and AWS EFA, a number of NICs per GPU | NVIDIA ConnectX with GPU-initiated RDMA IBGDA | NVIDIA GPU on RDMA material with EFA | RDMA NIC for KV-centric serving stack |
| EFA standing | Full help, peak 400 Gbps reported | Not supported, requires IBGDA of ConnectX | API works, however MoE utilization reveals vital degradation in EFA | Paper stories that EFA will not be supported within the RDMA engine |
| Portability of LLM methods | Single cross-vendor API throughout ConnectX 7 and EFA | Vendor-specific ConnectX targeted | NVIDIA-centric, not suitable with EFA MoE routing | Centered on KV sharing, no cross-provider help |
Essential factors
- TransferEngine gives a single RDMA point-to-point abstraction that works with each NVIDIA ConnectX 7 and AWS EFA to transparently handle a number of community interface controllers per GPU.
- This library makes use of ImmCounter to show single-sided WriteImm to attain peak 400 Gbps throughput on each NIC households. This permits it to compete with a single vendor’s stack whereas sustaining portability.
- The Perplexity group makes use of TransferEngine on three manufacturing methods, combining disaggregated prefill decoding with KvCache streaming, reinforcement studying weight switch to replace trillion-parameter fashions in about 1.3 seconds, and Combination of Consultants dispatch for large-scale fashions like Kimi K2.
- With ConnectX 7, pplx backyard’s MoE kernel gives state-of-the-art decoding latency, exceeding DeepEP on the identical {hardware}. In the meantime, EFA delivers the primary sensible MoE latency for multi-trillion parameter workloads.
- As a result of TransferEngine is open supply below the MIT license and situated in pplx backyard, groups can run very giant mixture of specialists and dense fashions on heterogeneous H100 or H200 clusters throughout cloud suppliers with out having to rewrite every vendor-specific networking stack.
The discharge of Perplexity’s TransferEngine and pplx backyard is a sensible contribution to LLM infrastructure groups which might be hampered by vendor-specific networking stacks and costly material upgrades. A conveyable RDMA abstraction that reaches peaks of 400 Gbps on each NVIDIA ConnectX 7 and AWS EFA, helps KvCache streaming, quick reinforcement studying weight switch, and skilled combination routing, instantly addressing the trillions of parameter provisioning constraints of real-world methods.
Please verify paper and lipo. Please be happy to test it out GitHub page for tutorials, code, and notebooks. Please be happy to comply with us too Twitter Do not forget to affix us 100,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. Asif is a visionary entrepreneur and engineer dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a synthetic intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information that’s technically sound and simply understood by a large viewers. The platform boasts over 2 million views per 30 days, which reveals its reputation amongst viewers.

{kind=link}