


On this submit, we present you ways Amazon Search optimized GPU occasion utilization by leveraging AWS Batch for SageMaker Coaching jobs. This managed resolution enabled us to orchestrate machine studying (ML) coaching workloads on GPU-accelerated occasion households like P5, P4, and others. We may also present a step-by-step walkthrough of the use case implementation.
Machine studying at Amazon Search
At Amazon Search, we use a whole bunch of GPU-accelerated situations to coach and consider ML fashions that assist our clients uncover merchandise they love. Scientists usually prepare a couple of mannequin at a time to search out the optimum set of options, mannequin structure, and hyperparameter settings that optimize the mannequin’s efficiency. We beforehand leveraged a first-in-first-out (FIFO) queue to coordinate mannequin coaching and analysis jobs. Nevertheless, we would have liked to make use of a extra nuanced standards to prioritize which jobs ought to run in what order. Manufacturing fashions wanted to run with excessive precedence, exploratory analysis as medium precedence, and hyperparameter sweeps and batch inference as low precedence. We additionally wanted a system that might deal with interruptions. Ought to a job fail, or a given occasion kind turn into saturated, we would have liked the job to run on different obtainable appropriate occasion sorts whereas respecting the general prioritization standards. Lastly, we wished a managed resolution so we may focus extra on mannequin improvement as an alternative of managing infrastructure.
After evaluating a number of choices, we selected AWS Batch for Amazon SageMaker Coaching jobs as a result of it finest met our necessities. This resolution seamlessly built-in AWS Batch with Amazon SageMaker and allowed us to run jobs per our prioritization standards. This enables utilized scientists to submit a number of concurrent jobs with out guide useful resource administration. By leveraging AWS Batch options comparable to superior prioritization by fair-share scheduling, we elevated peak utilization of GPU-accelerated situations from 40% to over 80%.
Amazon Search: AWS Batch for SageMaker Coaching Job implementation
We leveraged three AWS applied sciences to arrange our job queue. We used Service Environments to configure the SageMaker AI parameters that AWS Batch makes use of to submit and handle SageMaker Coaching jobs. We used Share Identifiers to prioritize our workloads. Lastly, we used Amazon CloudWatch to watch and the availability of alerting functionality for essential occasions or deviations from anticipated habits. Let’s dive deep into these constructs.
Service environments. We arrange service environments to signify the entire GPU capability obtainable for every occasion household, comparable to P5s and P4s. Every service surroundings was configured with mounted limits primarily based on our group’s reserved capability in AWS Batch. Observe that for groups utilizing SageMaker Coaching Plans, these limits could be set to the variety of reserved situations, making capability planning extra simple. By defining these boundaries, we established how the entire GPU occasion capability inside a service surroundings was distributed throughout completely different manufacturing jobs. Every manufacturing experiment was allotted a portion of this capability by Share Identifiers.
Determine 1 offers a real-world instance of how we used AWS Batch’s fair-share scheduling to divide 100 GPU occasion between ShareIDs. We allotted 60 situations to ProdExp1, and 40 to ProdExp2. When ProdExp2 used solely 25 GPU situations, the remaining 15 may very well be borrowed by ProdExp1, permitting it to scale as much as 75 GPU situations. When ProdExp2 later wanted its full 40 GPU situations, the scheduler preempted jobs from ProdExp1 to revive stability. This instance used the P4 occasion household, however the identical strategy may apply to any SageMaker-supported EC2 occasion household. This ensured that manufacturing workloads have assured entry to their assigned capability, whereas exploratory or ad-hoc experiments may nonetheless make use of any idle GPU situations. This design safeguarded essential workloads and improved general occasion utilization by making certain that no reserved capability went unused.
Determine 1: AWS Batch fair-share scheduling
Share Identifiers. We used Share Identifiers to allocate fractions of a service surroundings’s capability to manufacturing experiments. Share Identifiers are string tags utilized at job submission time. AWS Batch used these tags to trace utilization and implement fair-share scheduling. For initiatives that required devoted capability, we outlined preset Share Identifiers with quotas in AWS Batch. This reserved capability for manufacturing tracks. These quotas acted as equity targets fairly than laborious limits. Idle capability may nonetheless be borrowed, however underneath rivalry, AWS Batch enforced equity by preempting sources from overused identifiers and reassigned them to underused ones.
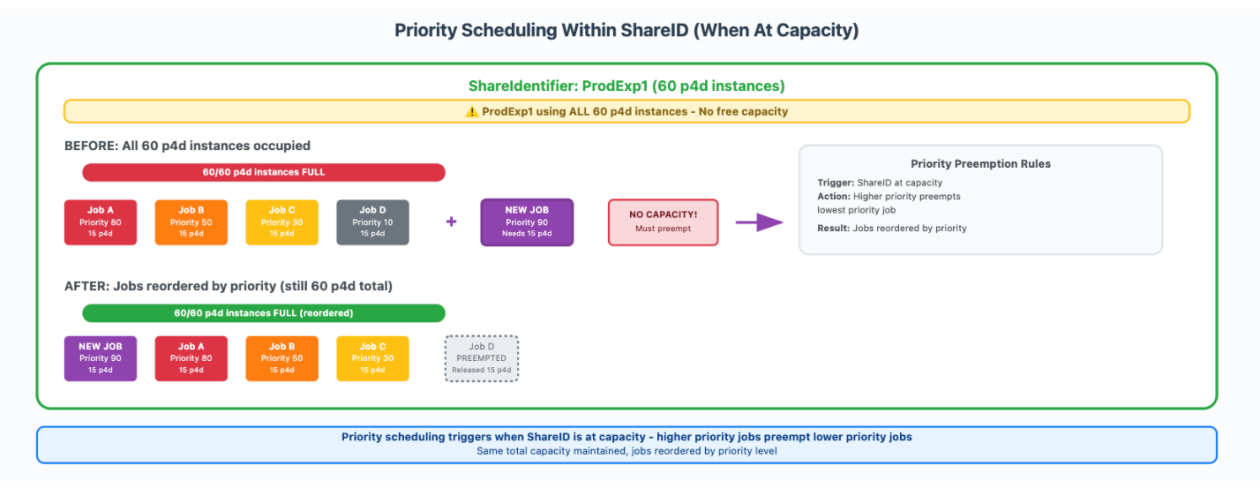
Inside every Share Identifier, job priorities starting from 0 to 99 decided execution order, however priority-based preemption solely triggered when the ShareIdentifier reached its allotted capability restrict. Determine 2 illustrates how we setup and used our share identifiers. ProdExp1 had 60 p4d situations and ran jobs at numerous priorities. Job A had a precedence of 80, Job B was set to 50, Job C was set to at 30, and Job D had a precedence 10. When all 60 situations have been occupied and a brand new high-priority job (precedence 90) requiring 15 situations was submitted, the system preempted the bottom precedence working job (Job D) to make room, whereas sustaining the entire of 60 situations for that Share Identifier.
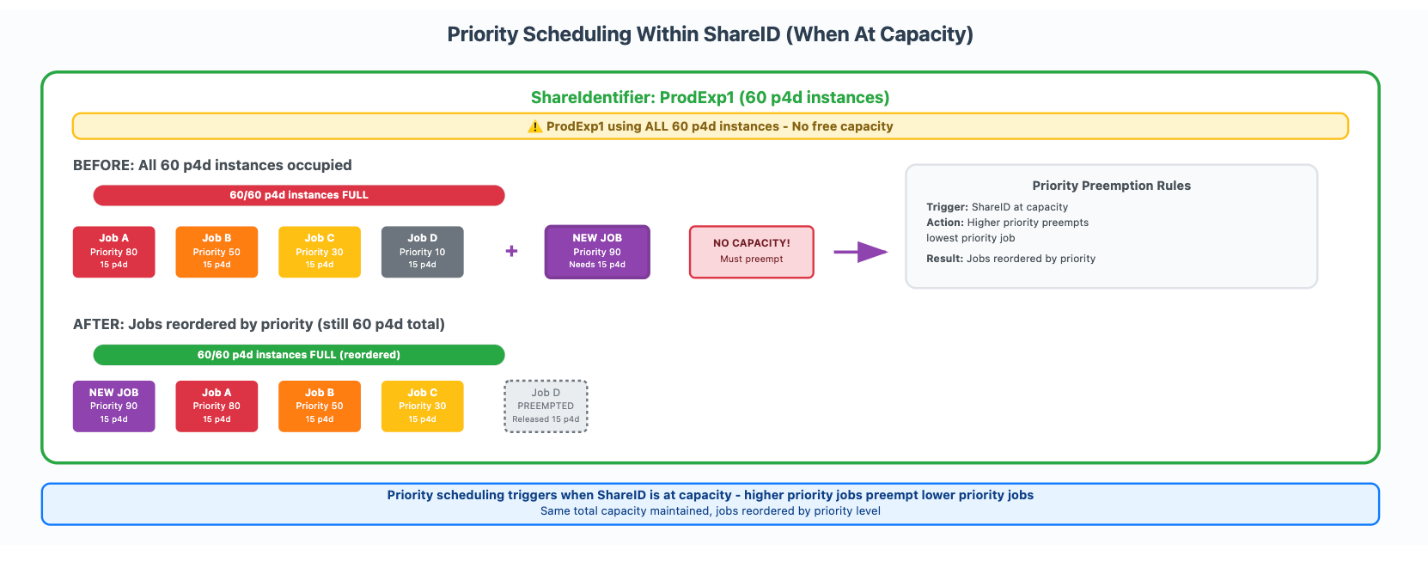
Determine 2: Precedence scheduling inside a Share ID
Amazon CloudWatch. We used Amazon CloudWatch to instrument our SageMaker coaching jobs. SageMaker mechanically publishes metrics on job progress and useful resource utilization, whereas AWS Batch offers detailed data on job scheduling and execution. With AWS Batch, we queried the standing of every job by the AWS Batch APIs. This made it attainable to trace jobs as they transitioned by states comparable to SUBMITTED, PENDING, RUNNABLE, STARTING, RUNNING, SUCCEEDED, and FAILED. We revealed these metrics and job states to CloudWatch and configured dashboards and alarms to alert anytime we encountered prolonged wait instances, sudden failures, or underutilized sources. This built-in integration offered each real-time visibility and historic development evaluation, which helped our group keep operational effectivity throughout GPU clusters with out constructing customized monitoring techniques.
Operational influence on group efficiency
By adopting AWS Batch for SageMaker Coaching jobs, we enabled experiments to run with out considerations about useful resource availability or rivalry. Researchers may submit jobs with out ready for guide scheduling, which elevated the variety of experiments that may very well be run in parallel. This led to shorter queue instances, greater GPU utilization, and quicker turnaround of coaching outcomes, straight enhancing each analysis throughput and supply timelines.
Easy methods to arrange AWS Batch for SageMaker Coaching jobs
To arrange an identical surroundings, you may observe this tutorial, which exhibits you the right way to orchestrate a number of GPU massive language mannequin (LLM) fine-tuning jobs utilizing a number of GPU-powered situations. The answer can be obtainable on GitHub.
Stipulations
To orchestrate a number of SageMaker Coaching jobs with AWS Batch, first you must full the next stipulations:
Clone the GitHub repository with the property for this deployment. This repository consists of notebooks that reference property:
Create AWS Batch sources
To create the mandatory sources to handle SageMaker Coaching job queues with AWS Batch, we offer utility features within the instance to automate the creation of the Service Atmosphere, Scheduling Coverage, and Job Queue.
The service surroundings represents the Amazon SageMaker AI capability limits obtainable to schedule, expressed by most variety of situations. The scheduling coverage signifies how useful resource computes are allotted in a job queue between customers or workloads. The job queue is the scheduler interface that researchers work together with to submit jobs and interrogate job standing. AWS Batch offers two completely different queues we will function with:
- FIFO queues – Queues through which no scheduling insurance policies are required
- Truthful-share queues – Queues through which a scheduling coverage Amazon Useful resource Identify (ARN) is required to orchestrate the submitted jobs
We advocate creating devoted service environments for every job queue in a 1:1 ratio. FIFO queues present primary message supply, whereas fair-share scheduling (FSS) queues present extra subtle scheduling, balancing utilization inside a Share Identifier, share weights, and job precedence. For purchasers who don’t want a number of shares however would really like the power to assign a precedence on job submission, we advocate creating an FSS queue and utilizing a single share inside it for all submissions.To create the sources, execute the next instructions:
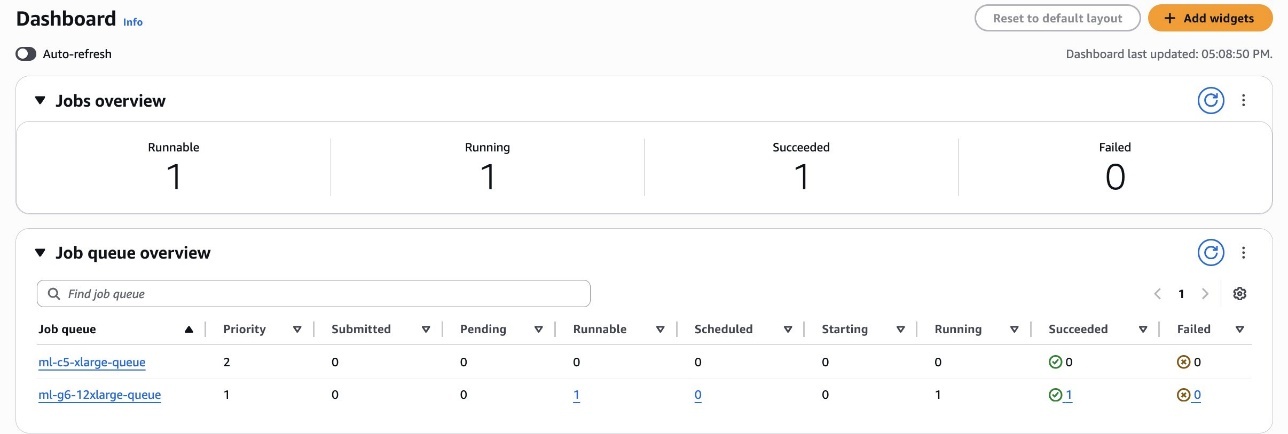
You may navigate the AWS Batch Dashboard, proven within the following screenshot, to discover the created sources.
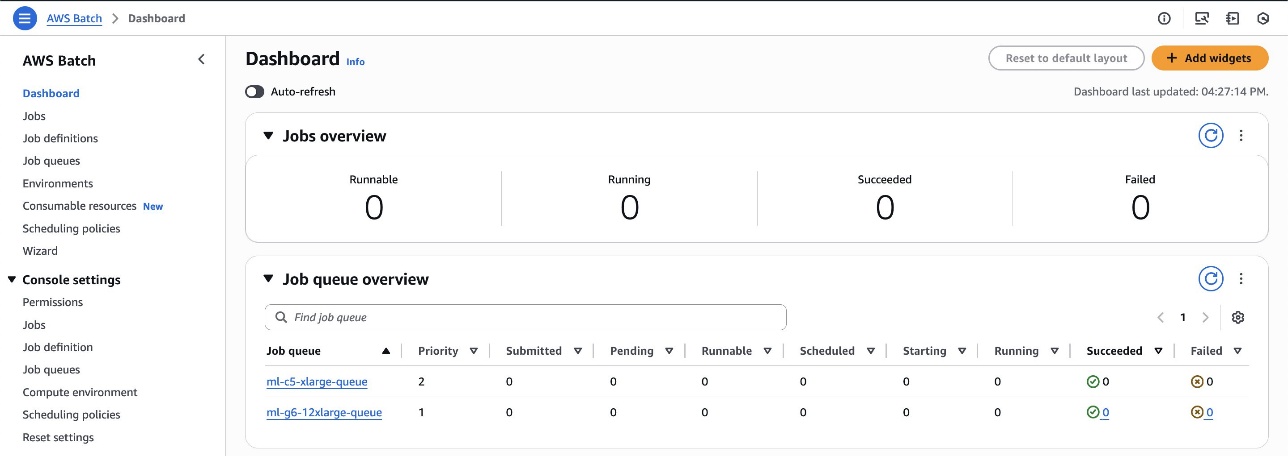
This automation script created two queues:
ml-c5-xlarge-queue– A FIFO queue with precedence 2 used for CPU workloadsml-g6-12xlarge-queue– A good-share queue with precedence 1 used for GPU workloads
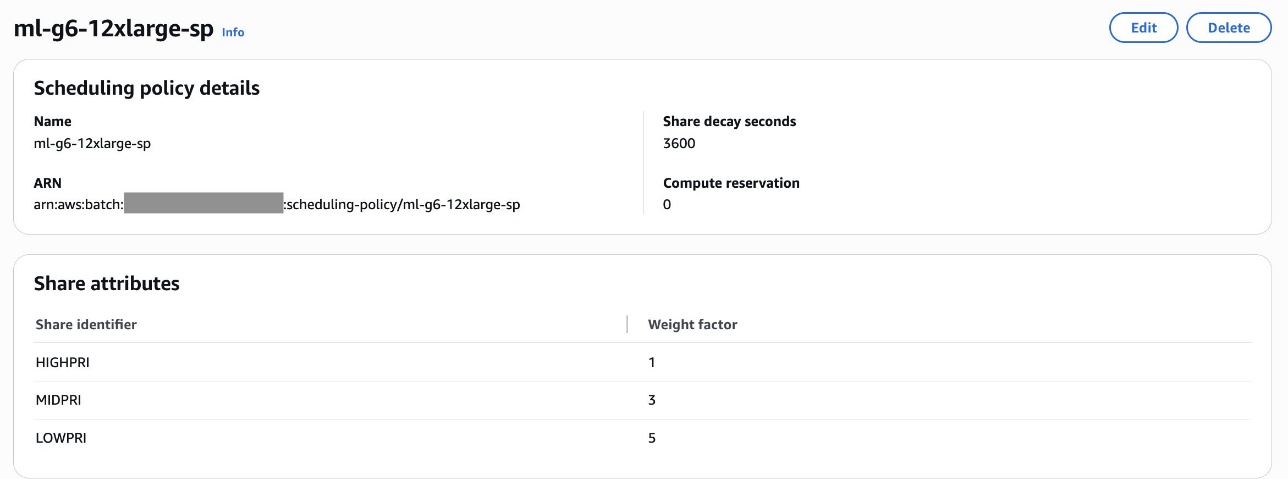
The related scheduling coverage for the queue ml-g6-12xlarge-queue is with share attributes comparable to Excessive precedence (HIGHPRI), Medium precedence (MIDPRI) and Low precedence (LOWPRI) together with the queue weights. Customers can submit jobs and assign them to one in all three shares: HIGHPRI, MIDPRI, or LOWPRI and assign weights comparable to 1 for prime precedence and three for medium and 5 for low precedence. Under is the screenshot displaying the scheduling coverage particulars:
For directions on the right way to arrange the service surroundings and a job queue, check with the Getting began part in Introducing AWS Batch help for SageMaker Coaching Jobs weblog.
Run LLM fine-tuning jobs on SageMaker AI
We run the pocket book pocket book.ipynb to start out submitting SageMaker Coaching jobs with AWS Batch. The pocket book comprises the code to arrange the info used for the workload, add on Amazon Easy Storage Service (Amazon S3), and outline the hyperparameters required by the job to be executed.
To run the fine-tuning workload utilizing SageMaker Coaching jobs, this instance makes use of the ModelTrainer class. The ModelTrainer class is a more recent and extra intuitive strategy to mannequin coaching that considerably enhances consumer expertise. It helps distributed coaching, construct your personal container (BYOC), and recipes.
For added details about ModelTrainer, you may check with Speed up your ML lifecycle utilizing the brand new and improved Amazon SageMaker Python SDK – Half 1: ModelTrainer.
To arrange the fine-tuning workload, full the next steps:
- Choose the occasion kind, the container picture for the coaching job, and outline the checkpoint path the place the mannequin will probably be saved:
- Create the ModelTrainer operate to encapsulate the coaching setup. The ModelTrainer class simplifies the expertise by encapsulating code and coaching setup. On this instance:
SourceCode– The supply code configuration. That is used to configure the supply code for working the coaching job through the use of your native python scripts.Compute– The compute configuration. That is used to specify the compute sources for the coaching job.
- Arrange the enter channels for ModelTrainer by creating InputData objects from the offered S3 bucket paths for the coaching and validation datasets:
Queue SageMaker Coaching jobs
This part and the next are meant for use interactively as a way to discover the right way to use the Amazon SageMaker Python SDK to submit jobs to your Batch queues. Comply with these steps:
- Choose the queue to make use of:
- Within the subsequent cell, submit two coaching jobs within the queue:
LOW PRIORITYMEDIUM PRIORITY
- Use the API
submitto submit all the roles:
Show the standing of working and in queue jobs
We are able to use the job queue checklist and job queue snapshot APIs to programmatically view a snapshot of the roles that the queue will run subsequent. For fair-share queues, this ordering is dynamic and sometimes must be refreshed as a result of new jobs are submitted to the queue or as share utilization modifications over time.
The next screenshot exhibits the roles submitted with low precedence and medium precedence within the Runnable State and within the queue.
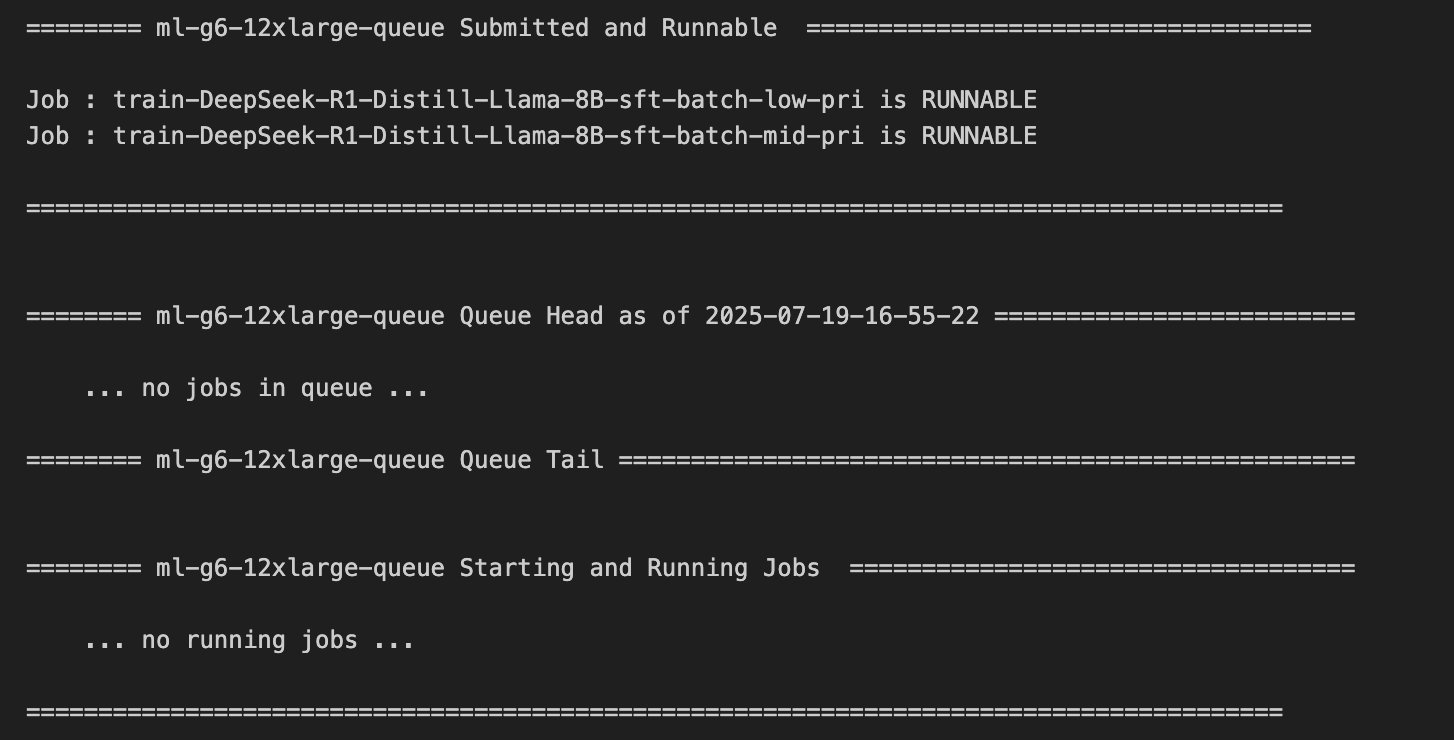
You may as well check with the AWS Batch Dashboard, proven within the following screenshot, to investigate the standing of the roles.
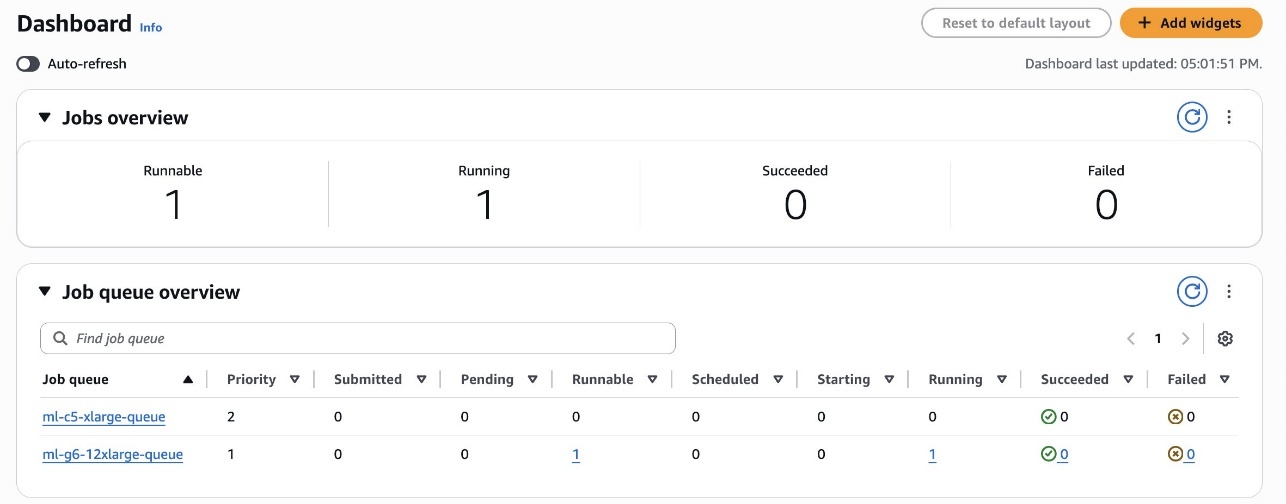
As proven within the following screenshot, the primary job executed with the SageMaker Coaching job is the MEDIUM PRIORITY one, by respecting the scheduling coverage guidelines outlined beforehand.
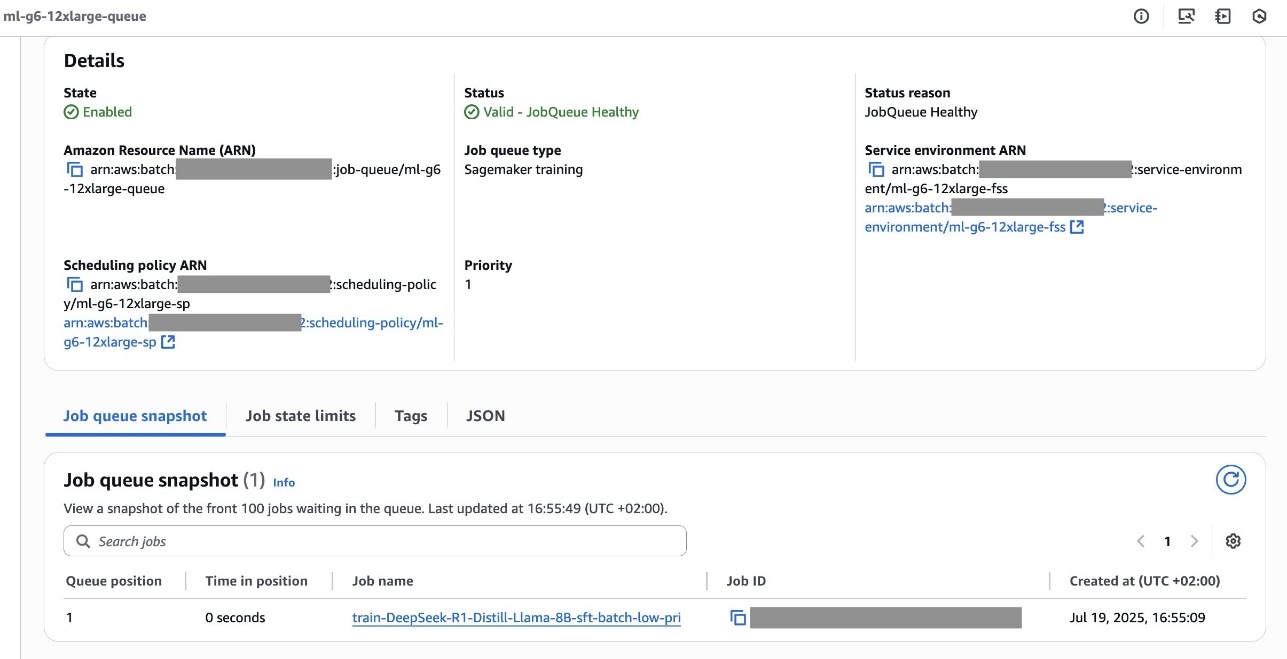
You may discover the working coaching job within the SageMaker AI console, as proven within the following screenshot.
Submit an extra job
Now you can submit an extra SageMaker Coaching job with HIGH PRIORITY to the queue:
You may discover the standing from the dashboard, as proven within the following screenshot.
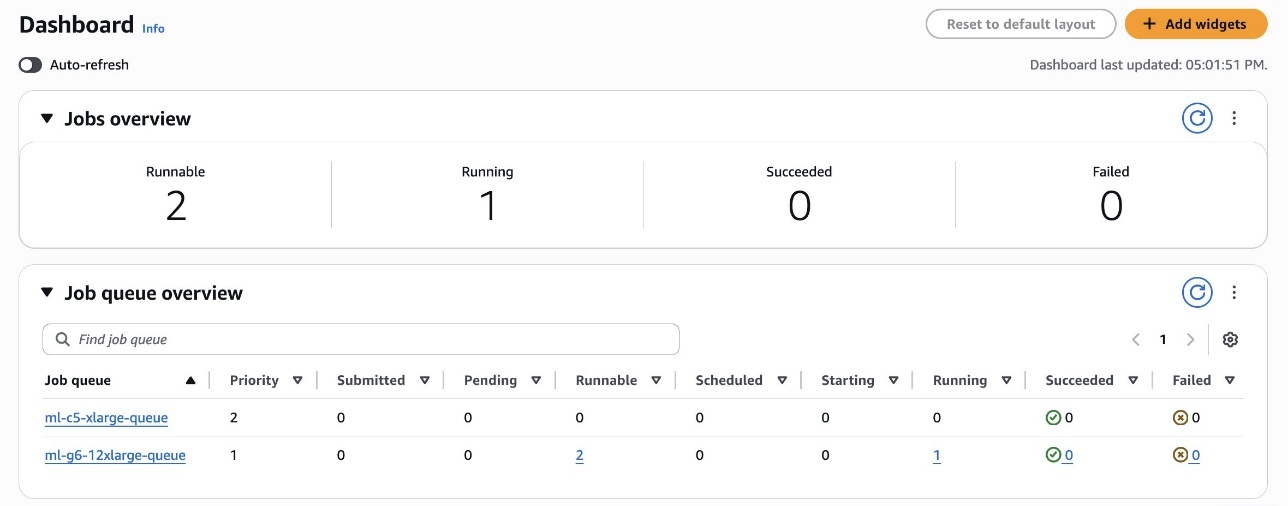
The HIGH PRIORITY job, regardless of being submitted later within the queue, will probably be executed earlier than the opposite runnable jobs by respecting the scheduling coverage guidelines, as proven within the following screenshot.
Because the scheduling coverage within the screenshot exhibits, the LOWPRI share has a better weight issue (5) than the MIDPRI share (3). Since a decrease weight signifies greater precedence, a LOWPRI job will probably be executed after a MIDPRI job, even when they’re submitted on the identical time.

Clear up
To wash up your sources to keep away from incurring future fees, observe these steps:
- Confirm that your coaching job isn’t working anymore. To take action, in your SageMaker console, select Coaching and verify Coaching jobs.
- Delete AWS Batch sources through the use of the command
python create_resources.py --cleanfrom the GitHub instance or by manually deleting them from the AWS Administration Console.
Conclusion
On this submit, we demonstrated how Amazon Search used AWS Batch for SageMaker Coaching Jobs to optimize GPU useful resource utilization and coaching job administration. The answer reworked their coaching infrastructure by implementing subtle queue administration and fair proportion scheduling, growing peak GPU utilization from 40% to over 80%.We advocate that organizations going through related ML coaching infrastructure challenges discover AWS Batch integration with SageMaker, which offers built-in queue administration capabilities and priority-based scheduling. The answer eliminates guide useful resource coordination whereas offering workloads with acceptable prioritization by configurable scheduling insurance policies.
To start implementing AWS Batch with SageMaker Coaching jobs, you may entry our pattern code and implementation information within the amazon-sagemaker-examples repository on GitHub. The instance demonstrates the right way to arrange AWS Identification and Entry Administration (IAM) permissions, create AWS Batch sources, and orchestrate a number of GPU-powered coaching jobs utilizing ModelTrainer class.
The authors want to thank Charles Thompson and Kanwaljit Khurmi for his or her collaboration.
In regards to the authors

{kind=link}